list = new ArrayList<>();
+
+ while(true){
+ byte[] arr = new byte[1024 * 10];//10kb
+ list.add(arr);
+// try {
+// Thread.sleep(5);
+// } catch (InterruptedException e) {
+// e.printStackTrace();
+// }
+ }
+ }
+}
+```
+
+### 老年代使用CMS GC
+
+**GC设置方法**:参数中使用-XX:+UseConcMarkSweepGC,说明老年代使用CMS GC,同时年轻代也会触发对ParNew的使用,因此添加该参数之后,新生代使用ParNew GC,而老年代使用CMS GC,整体是并发垃圾收集,主打低延迟
+
+
+
+打印出来的GC细节:
+
+
+
+
+
+### 新生代使用Serial GC
+
+ **GC设置方法**:参数中使用-XX:+UseSerialGC,说明新生代使用Serial GC,同时老年代也会触发对Serial Old GC的使用,因此添加该参数之后,新生代使用Serial GC,而老年代使用Serial Old GC,整体是串行垃圾收集
+
+
+
+ 打印出来的GC细节:
+
+
+
+DefNew代表新生代使用Serial GC,然后Tenured代表老年代使用Serial Old GC
+
+## GC 日志分类
+
+### MinorGC
+
+MinorGC(或 young GC 或 YGC)日志:
+
+```java
+[GC (Allocation Failure) [PSYoungGen: 31744K->2192K (36864K) ] 31744K->2200K (121856K), 0.0139308 secs] [Times: user=0.05 sys=0.01, real=0.01 secs]
+```
+
+
+
+
+
+### FullGC
+
+```java
+[Full GC (Metadata GC Threshold) [PSYoungGen: 5104K->0K (132096K) ] [Par01dGen: 416K->5453K (50176K) ]5520K->5453K (182272K), [Metaspace: 20637K->20637K (1067008K) ], 0.0245883 secs] [Times: user=0.06 sys=0.00, real=0.02 secs]
+```
+
+
+
+
+
+## GC 日志结构剖析
+
+### 透过日志看垃圾收集器
+
+- Serial 收集器:新生代显示 "[DefNew",即 Default New Generation
+
+- ParNew 收集器:新生代显示 "[ParNew",即 Parallel New Generation
+
+- Parallel Scavenge 收集器:新生代显示"[PSYoungGen",JDK1.7 使用的即 PSYoungGen
+
+- Parallel Old 收集器:老年代显示"[ParoldGen"
+
+- G1 收集器:显示”garbage-first heap“
+
+### 透过日志看 GC 原因
+
+- Allocation Failure:表明本次引起 GC 的原因是因为新生代中没有足够的区域存放需要分配的数据
+- Metadata GCThreshold:Metaspace 区不够用了
+- FErgonomics:JVM 自适应调整导致的 GC
+- System:调用了 System.gc()方法
+
+### 透过日志看 GC 前后情况
+
+通过图示,我们可以发现 GC 日志格式的规律一般都是:GC 前内存占用-> GC 后内存占用(该区域内存总大小)
+
+```java
+[PSYoungGen: 5986K->696K (8704K) ] 5986K->704K (9216K)
+```
+
+- 中括号内:GC 回收前年轻代堆大小,回收后大小,(年轻代堆总大小)
+
+- 括号外:GC 回收前年轻代和老年代大小,回收后大小,(年轻代和老年代总大小)
+
+注意:Minor GC 堆内存总容量 = 9/10 年轻代 + 老年代。原因是 Survivor 区只计算 from 部分,而 JVM 默认年轻代中 Eden 区和 Survivor 区的比例关系,Eden:S0:S1=8:1:1。
+
+### 透过日志看 GC 时间
+
+GC 日志中有三个时间:user,sys 和 real
+
+- user:进程执行用户态代码(核心之外)所使用的时间。这是执行此进程所使用的实际 CPU 时间,其他进程和此进程阻塞的时间并不包括在内。在垃圾收集的情况下,表示 GC 线程执行所使用的 CPU 总时间。
+- sys:进程在内核态消耗的 CPU 时间,即在内核执行系统调用或等待系统事件所使用的 CPU 时间
+- real:程序从开始到结束所用的时钟时间。这个时间包括其他进程使用的时间片和进程阻塞的时间(比如等待 I/O 完成)。对于并行 gc,这个数字应该接近(用户时间+系统时间)除以垃圾收集器使用的线程数。
+
+由于多核的原因,一般的 GC 事件中,real time 是小于 sys time + user time 的,因为一般是多个线程并发的去做 GC,所以 real time 是要小于 sys + user time 的。如果 real > sys + user 的话,则你的应用可能存在下列问题:IO 负载非常重或 CPU 不够用。
+
+## Minor GC 日志解析
+
+### 日志格式
+
+```Java
+2021-09-06T08:44:49.453+0800: 4.396: [GC (Allocation Failure) [PSYoungGen: 76800K->8433K(89600K)] 76800K->8449K(294400K), 0.0060231 secs] [Times: user=0.02 sys=0.01, real=0.01 secs]
+```
+
+### 日志解析
+
+#### 2021-09-06T08:44:49.453+0800
+
+日志打印时间 日期格式 如 2013-05-04T21:53:59.234+0800
+
+添加-XX:+PrintGCDateStamps参数
+
+#### 4.396
+
+gc 发生时,Java 虚拟机启动以来经过的秒数
+
+添加-XX:+PrintGCTimeStamps该参数
+
+#### [GC (Allocation Failure)
+
+发生了一次垃圾回收,这是一次 Minor GC。它不区分新生代 GC 还是老年代 GC,括号里的内容是 gc 发生的原因,这里 Allocation Failure 的原因是新生代中没有足够区域能够存放需要分配的数据而失败。
+
+#### [PSYoungGen: 76800K->8433K(89600K)]
+
+**PSYoungGen**:表示GC发生的区域,区域名称与使用的GC收集器是密切相关的
+
+- **Serial收集器**:Default New Generation 显示Defnew
+- **ParNew收集器**:ParNew
+- **Parallel Scanvenge收集器**:PSYoung
+- 老年代和新生代同理,也是和收集器名称相关
+
+**76800K->8433K(89600K)**:GC前该内存区域已使用容量->GC后盖区域容量(该区域总容量)
+
+- 如果是新生代,总容量则会显示整个新生代内存的9/10,即eden+from/to区
+- 如果是老年代,总容量则是全身内存大小,无变化
+
+#### 76800K->8449K(294400K)
+
+虽然本次是Minor GC,只会进行新生代的垃圾收集,但是也肯定会打印堆中总容量相关信息
+
+在显示完区域容量GC的情况之后,会接着显示整个堆内存区域的GC情况:GC前堆内存已使用容量->GC后堆内存容量(堆内存总容量),并且堆内存总容量 = 9/10 新生代 + 老年代,然后堆内存总容量肯定小于初始化的内存大小
+
+#### ,0.0088371
+
+整个GC所花费的时间,单位是秒
+
+#### [Times:user=0.02 sys=0.01,real=0.01 secs]
+
+- **user**:指CPU工作在用户态所花费的时间
+- **sys**:指CPU工作在内核态所花费的时间
+- **real**:指在此次事件中所花费的总时间
+
+## Full GC 日志解析
+
+### 日志格式
+
+```Java
+2021-09-06T08:44:49.453+0800: 4.396: [Full GC (Metadata GC Threshold) [PSYoungGen: 10082K->0K(89600K)] [ParOldGen: 32K->9638K(204800K)] 10114K->9638K(294400K), [Metaspace: 20158K->20156K(1067008K)], 0.0149928 secs] [Times: user=0.06 sys=0.02, real=0.02 secs]
+```
+
+### 日志解析
+
+#### 2020-11-20T17:19:43.794-0800
+
+日志打印时间 日期格式 如 2013-05-04T21:53:59.234+0800
+
+添加-XX:+PrintGCDateStamps参数
+
+#### 1.351
+
+gc 发生时,Java 虚拟机启动以来经过的秒数
+
+添加-XX:+PrintGCTimeStamps该参数
+
+#### Full GC(Metadata GCThreshold)
+
+括号中是gc发生的原因,原因:Metaspace区不够用了。
+除此之外,还有另外两种情况会引起Full GC,如下:
+
+1. Full GC(FErgonomics)
+ 原因:JVM自适应调整导致的GC
+2. Full GC(System)
+ 原因:调用了System.gc()方法
+
+#### [PSYoungGen: 100082K->0K(89600K)]
+
+**PSYoungGen**:表示GC发生的区域,区域名称与使用的GC收集器是密切相关的
+
+- **Serial收集器**:Default New Generation 显示DefNew
+- **ParNew收集器**:ParNew
+- **Parallel Scanvenge收集器**:PSYoungGen
+- 老年代和新生代同理,也是和收集器名称相关
+
+**10082K->0K(89600K)**:GC前该内存区域已使用容量->GC该区域容量(该区域总容量)
+
+- 如果是新生代,总容量会显示整个新生代内存的9/10,即eden+from/to区
+
+- 如果是老年代,总容量则是全部内存大小,无变化
+
+#### ParOldGen:32K->9638K(204800K)
+
+老年代区域没有发生GC,因此本次GC是metaspace引起的
+
+#### 10114K->9638K(294400K),
+
+在显示完区域容量GC的情况之后,会接着显示整个堆内存区域的GC情况:GC前堆内存已使用容量->GC后堆内存容量(堆内存总容量),并且堆内存总容量 = 9/10 新生代 + 老年代,然后堆内存总容量肯定小于初始化的内存大小
+
+#### [Meatspace:20158K->20156K(1067008K)],
+
+metaspace GC 回收2K空间
+
+
+
+## 论证FullGC是否会回收元空间/永久代垃圾
+
+```Java
+/**
+ * jdk6/7中:
+ * -XX:PermSize=10m -XX:MaxPermSize=10m
+ *
+ * jdk8中:
+ * -XX:MetaspaceSize=10m -XX:MaxMetaspaceSize=10m
+ *
+ * @author IceBlue
+ * @create 2020 22:24
+ */
+public class OOMTest extends ClassLoader {
+ public static void main(String[] args) {
+ int j = 0;
+ try {
+ for (int i = 0; i < 100000; i++) {
+ OOMTest test = new OOMTest();
+ //创建ClassWriter对象,用于生成类的二进制字节码
+ ClassWriter classWriter = new ClassWriter(0);
+ //指明版本号,修饰符,类名,包名,父类,接口
+ classWriter.visit(Opcodes.V1_8, Opcodes.ACC_PUBLIC, "Class" + i, null, "java/lang/Object", null);
+ //返回byte[]
+ byte[] code = classWriter.toByteArray();
+ //类的加载
+ test.defineClass("Class" + i, code, 0, code.length);//Class对象
+ test = null;
+ j++;
+ }
+ } finally {
+ System.out.println(j);
+ }
+ }
+}
+```
+
+输出结果:
+
+```
+[GC (Metadata GC Threshold) [PSYoungGen: 10485K->1544K(152576K)] 10485K->1552K(500736K), 0.0011517 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
+[Full GC (Metadata GC Threshold) [PSYoungGen: 1544K->0K(152576K)] [ParOldGen: 8K->658K(236544K)] 1552K->658K(389120K), [Metaspace: 3923K->3320K(1056768K)], 0.0051012 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
+[GC (Metadata GC Threshold) [PSYoungGen: 5243K->832K(152576K)] 5902K->1490K(389120K), 0.0009536 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
+
+-------省略N行-------
+
+[Full GC (Last ditch collection) [PSYoungGen: 0K->0K(2427904K)] [ParOldGen: 824K->824K(5568000K)] 824K->824K(7995904K), [Metaspace: 3655K->3655K(1056768K)], 0.0041177 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
+Heap
+ PSYoungGen total 2427904K, used 0K [0x0000000755f80000, 0x00000007ef080000, 0x00000007ffe00000)
+ eden space 2426880K, 0% used [0x0000000755f80000,0x0000000755f80000,0x00000007ea180000)
+ from space 1024K, 0% used [0x00000007ea180000,0x00000007ea180000,0x00000007ea280000)
+ to space 1536K, 0% used [0x00000007eef00000,0x00000007eef00000,0x00000007ef080000)
+ ParOldGen total 5568000K, used 824K [0x0000000602200000, 0x0000000755f80000, 0x0000000755f80000)
+ object space 5568000K, 0% used [0x0000000602200000,0x00000006022ce328,0x0000000755f80000)
+ Metaspace used 3655K, capacity 4508K, committed 9728K, reserved 1056768K
+ class space used 394K, capacity 396K, committed 2048K, reserved 1048576K
+
+进程已结束,退出代码0
+
+```
+
+通过不断地动态生成类对象,输出GC日志
+
+根据GC日志我们可以看出当元空间容量耗尽时,会触发FullGC,而每次FullGC之前,至会进行一次MinorGC,而MinorGC只会回收新生代空间;
+
+只有在FullGC时,才会对新生代,老年代,永久代/元空间全部进行垃圾收集
\ No newline at end of file
diff --git "a/JDK/JVM/\347\274\226\350\257\221JDK13.md" "b/JDK/JVM/\347\274\226\350\257\221JDK13.md"
new file mode 100644
index 0000000000..07e0b72daa
--- /dev/null
+++ "b/JDK/JVM/\347\274\226\350\257\221JDK13.md"
@@ -0,0 +1,92 @@
+# 1 系统环境
+
+Xcode
+Oracle JDK: 13
+
+先确保系统已安装freetype和ccache
+- freetype: 2.9
+- ccache: 3.3.5
+
+```bash
+$ brew install freetype ccache
+```
+
+# 2 下载源码
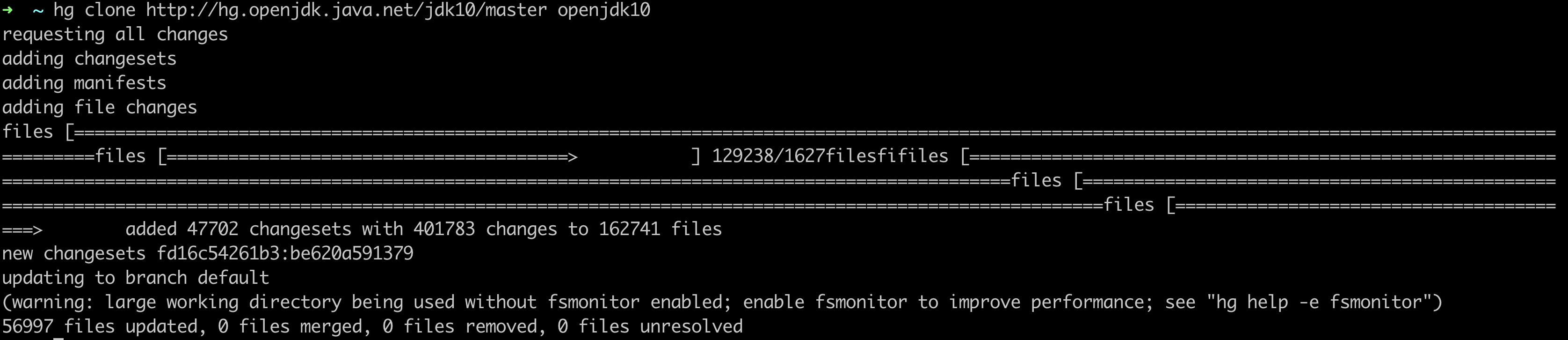
+通过Mercurial代码管理版本管理工具从Repository中直接获取源码(Repository为http://hg.openjdk.java.net)
+
+
+# 3 自动检测依赖
+进入解压后的文件夹,然后运行`bash ./configure`。这是一项检测所需要的依赖是否安装好了的脚本。只需要根据其提供的错误提示,将相应错误修改完成即可。
+
+# 4 配置参数
+## 参数说明
+```java
+--with-debug-level=slowdebug 启用slowdebug级别调试
+--enable-dtrace 启用dtrace
+--with-jvm-variants=server 编译server类型JVM
+--with-target-bits=64 指定JVM为64位
+--enable-ccache 启用ccache,加快编译
+--with-num-cores=8 编译使用CPU核心数
+--with-memory-size=8000 编译使用内存
+--disable-warnings-as-errors 忽略警告
+```
+
+```bash
+bash configure
+--with-debug-level=slowdebug --enable-dtrace
+--with-jvm-variants=server
+--with-target-bits=64
+--enable-ccache
+--with-num-cores=8
+--with-memory-size=8000
+--disable-warnings-as-errors
+```
+
+- 直接报错
+```java
+configure: error: No xcodebuild tool and no system framework headers found, use --with-sysroot or --with-sdk-name to provide a path to a valid SDK
+```
+运行了一下`xcodebuild`,错误信息如下:
+
+```java
+xcode-select: error: tool 'xcodebuild' requires Xcode,
+but active developer directory
+'/Library/Developer/CommandLineTools' is a command line tools instance
+```
+
+- 解决方案
+
+```java
+sudo xcode-select --switch /Applications/Xcode.app/Contents/Developer
+```
+
+
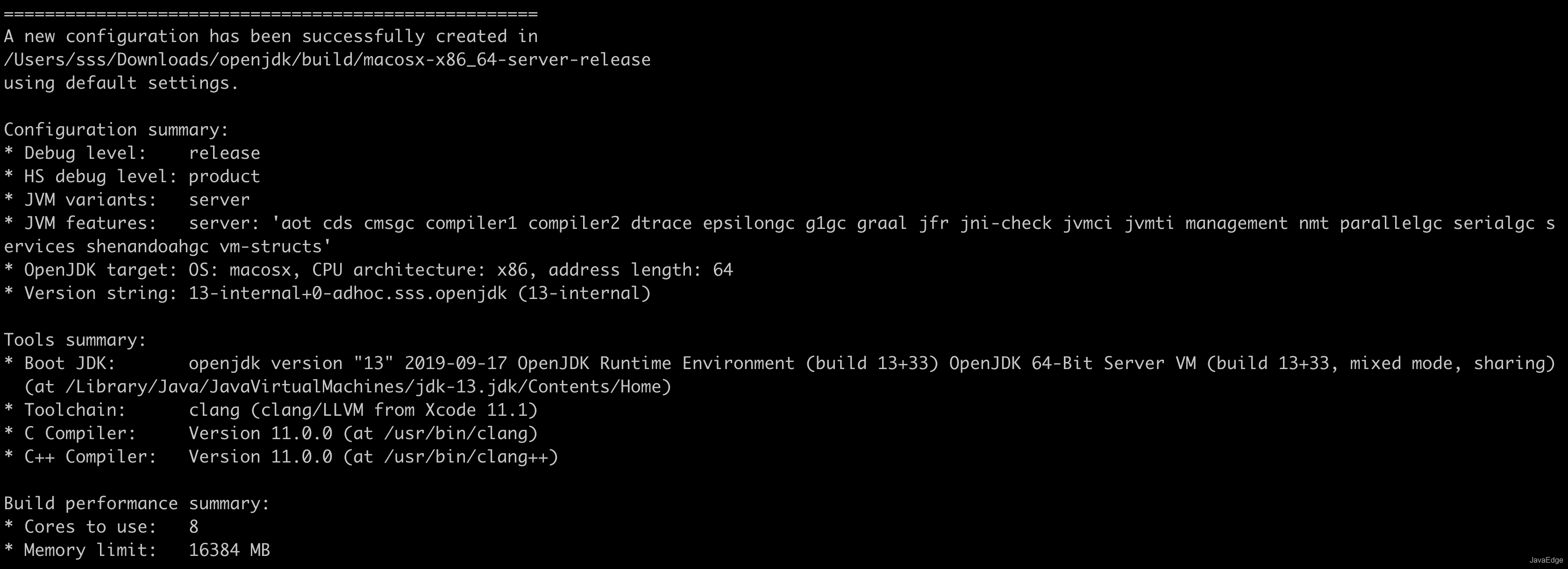
+- 继续执行bash configure得到如下
+
+
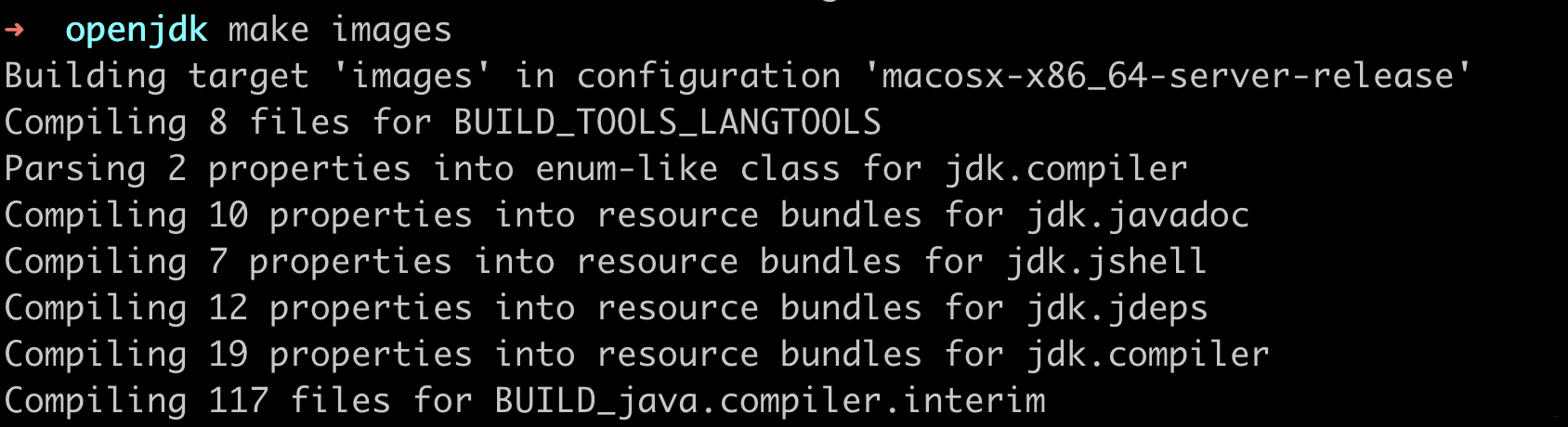
+# 5 开始编译
+
+```java
+make image
+```
+
+
+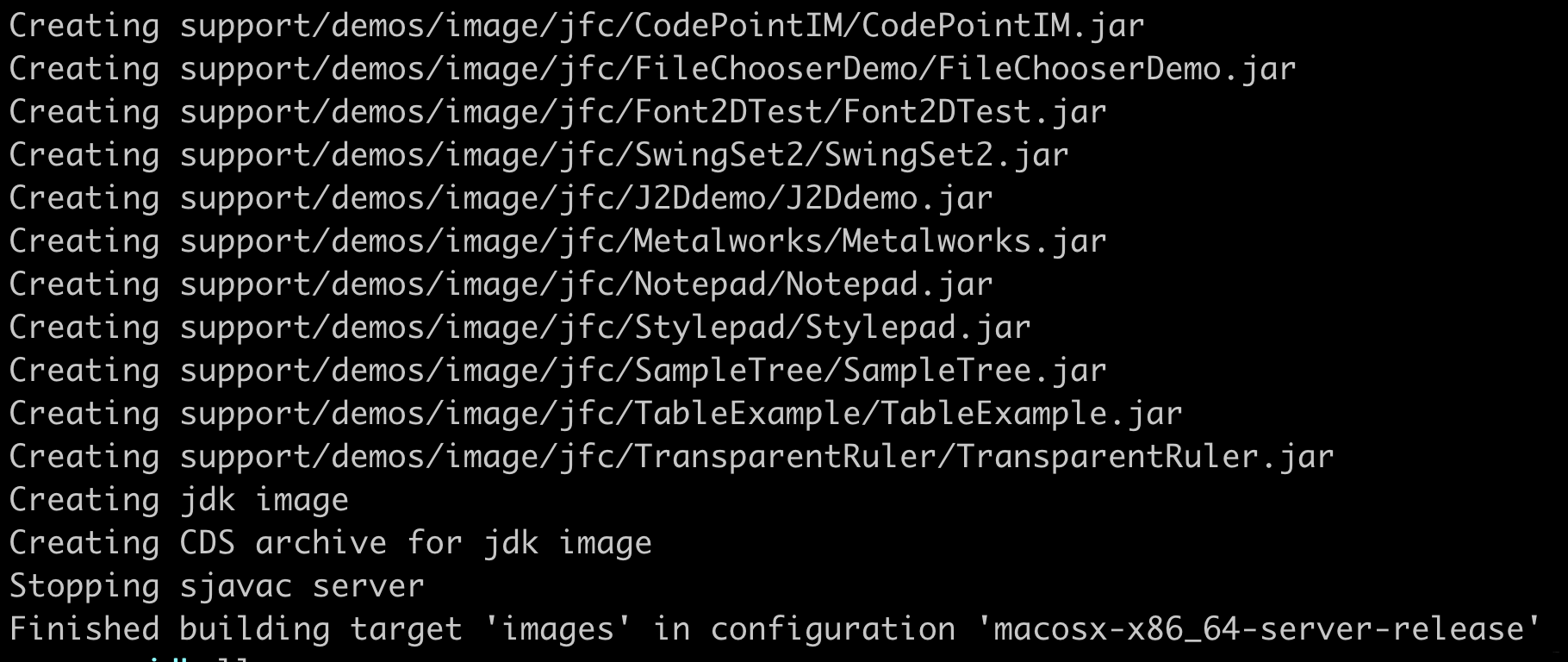
+完成了!
+
+# 6 验证
+
+
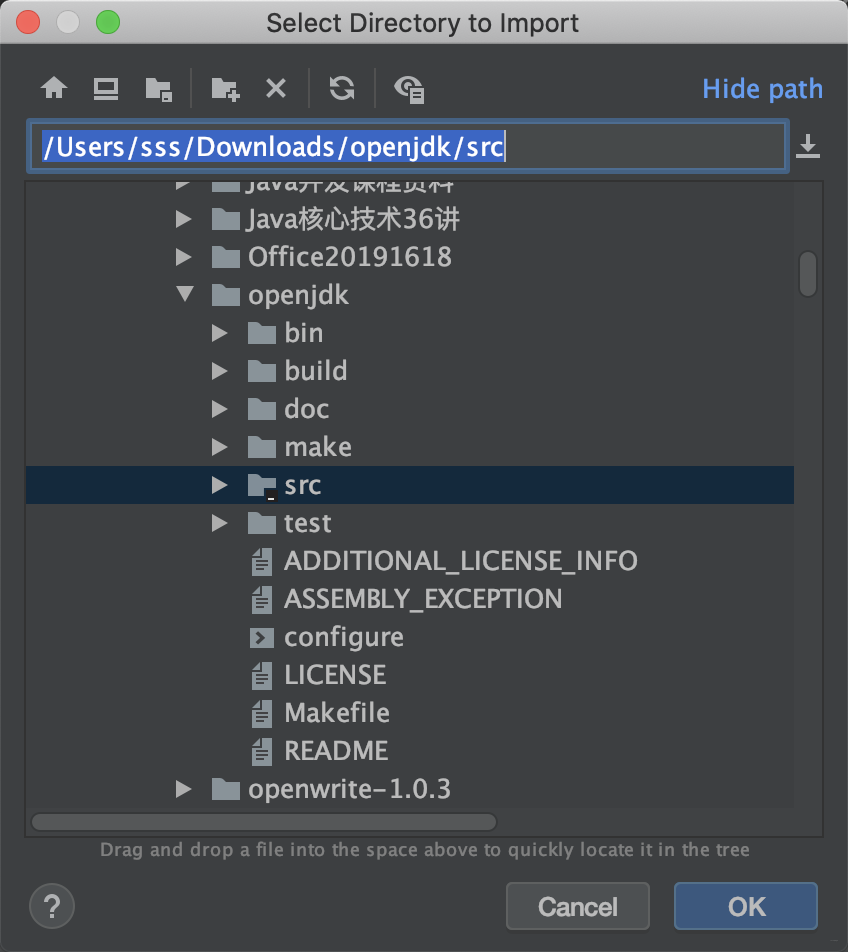
+# 7 Clion 导入项目
+
+
+
+- 选择ok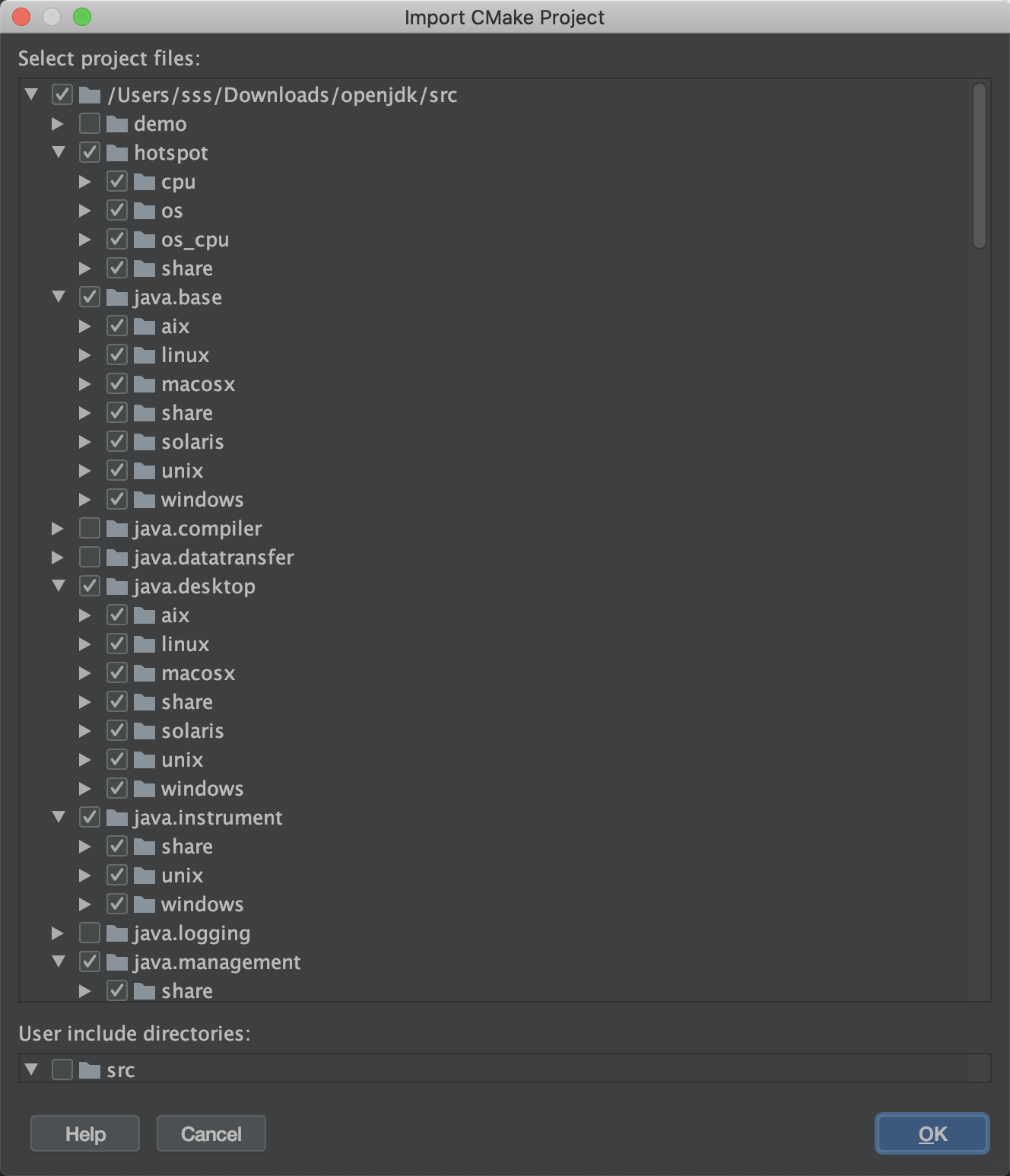
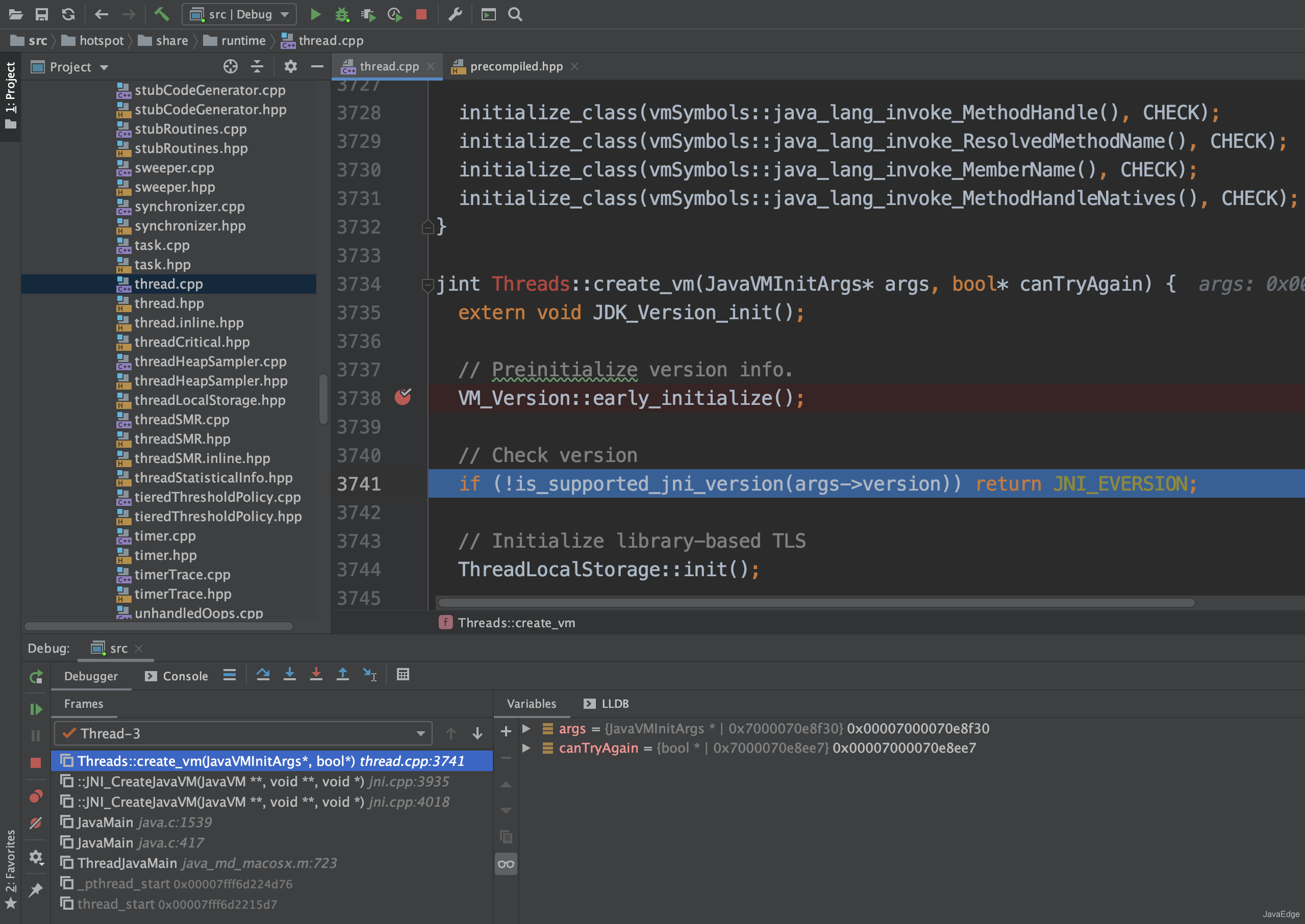
+# 8 编辑配置
+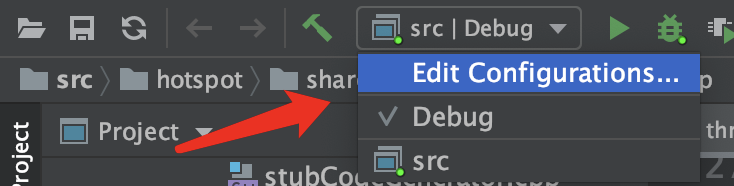
+如下图编辑DEBUG配置信息
+- Executable 选择之前build出的镜像里的java可执行文件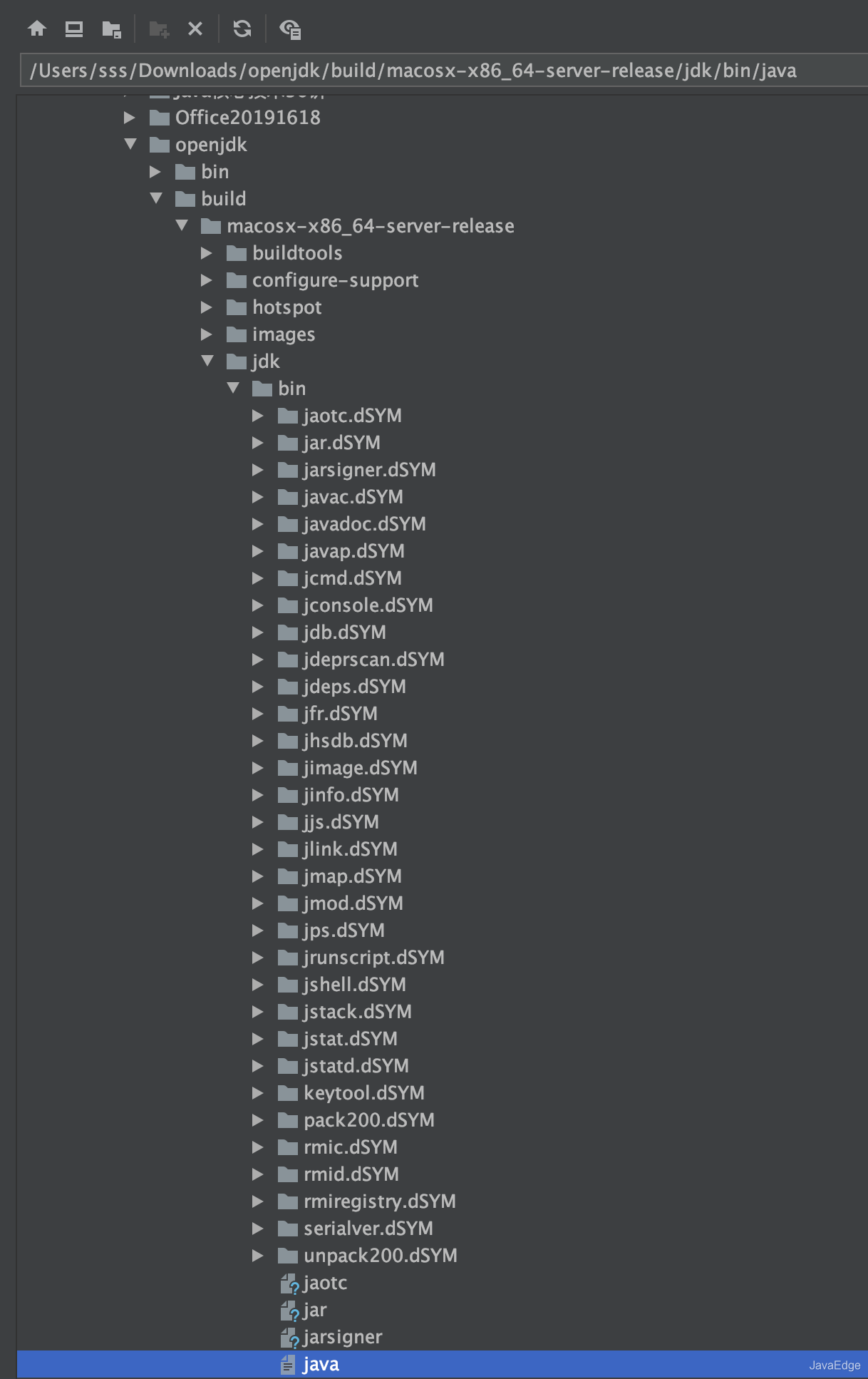
+- Program arguments 填写-version,输出Java版本
+- Before launch 注意:这里一定要移除Build,否则会报错无法调试
+
+
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Iterator\350\277\255\344\273\243\345\231\250\345\210\260\345\272\225\346\230\257\344\273\200\344\271\210?.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Iterator\350\277\255\344\273\243\345\231\250\345\210\260\345\272\225\346\230\257\344\273\200\344\271\210?.md"
new file mode 100644
index 0000000000..09ae906da6
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Iterator\350\277\255\344\273\243\345\231\250\345\210\260\345\272\225\346\230\257\344\273\200\344\271\210?.md"
@@ -0,0 +1,109 @@
+我们常使用 JDK 提供的迭代接口进行 Java 集合的迭代。
+```java
+Iterator iterator = list.iterator();
+while (iterator.hasNext()) {
+ String string = iterator.next();
+ //do something
+}
+```
+迭代可以简单地理解为遍历,是一个标准化遍历各类容器里面的所有对象的方法类。Iterator 模式是用于遍历集合类的标准访问方法。它可以把访问逻辑从不同类型集合类中抽象出来,从而避免向客户端暴露集合内部结构。
+
+在没有迭代器时,我们都这么处理:
+数组处理:
+```java
+int[] arrays = new int[10];
+for(int i = 0 ; i < arrays.length ; i++){
+ int a = arrays[i];
+ // do sth
+}
+```
+ArrayList处理:
+```java
+List list = new ArrayList();
+for(int i = 0 ; i < list.size() ; i++){
+ String string = list.get(i);
+ // do sth
+}
+```
+这些方式,都需要事先知道集合内部结构,访问代码和集合结构本身紧耦合,无法将访问逻辑从集合类和客户端代码中分离。同时每一种集合对应一种遍历方法,客户端代码无法复用。
+
+实际应用中,若需要将上面将两个集合进行整合,则很麻烦。所以为解决如上问题, Iterator 模式诞生了。
+它总是用同一种逻辑遍历集合,从而客户端无需再维护集合内部结构,所有内部状态都由 Iterator 维护。客户端不直接和集合类交互,它只控制 Iterator,向它发送”向前”,”向后”,”取当前元素”的命令,即可实现对客户端透明地遍历整个集合。
+
+# java.util.Iterator
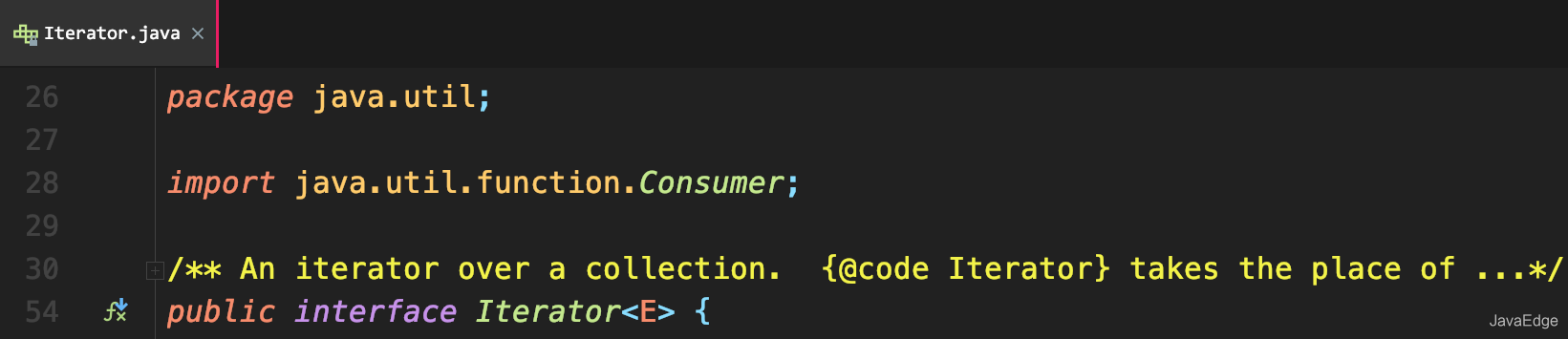
+在 Java 中 Iterator 为一个接口,它只提供迭代的基本规则,在 JDK 中他是这样定义的:对 collection 进行迭代的迭代器。
+
+
+迭代器取代了Java集合框架中的 Enumeration。迭代器与枚举有两点不同:
+1. 迭代器允许调用者利用定义良好的语义在迭代期间,从迭代器所指向的 collection 移除元素
+2. 优化方法名
+
+其接口定义如下:
+
+```java
+Object next():返回迭代器刚越过的元素的引用,返回值是 Object,需要强制转换成自己需要的类型
+
+boolean hasNext():判断容器内是否还有可供访问的元素
+
+void remove():删除迭代器刚越过的元素
+```
+一般只需使用 next()、hasNext() 即可完成迭代:
+```java
+for(Iterator it = c.iterator(); it.hasNext(); ) {
+ Object o = it.next();
+ // do sth
+}
+```
+所以Iterator一大优点是无需知道集合内部结构。集合的内部结构、状态都由 Iterator 维护,通过统一的方法 hasNext()、next() 来判断、获取下一个元素,至于具体的内部实现我们就不用关心了。
+# 各个集合的 Iterator 实现
+ArrayList 的内部实现采用数组,所以我们只需要记录相应位置的索引即可。
+
+## ArrayList 的 Iterator 实现
+在 ArrayList 内部首先是定义一个内部类 Itr,该内部类实现 Iterator 接口,如下:
+
+
+- ArrayList#iterator() :返回的是 Itr() 内部类
+
+### 成员变量
+在 Itr 内部定义了三个 int 型的变量:
+- cursor
+下一个元素的索引位置
+- lastRet
+上一个元素的索引位置
+```java
+int cursor;
+int lastRet = -1;
+int expectedModCount = modCount;
+```
+所以lastRet 一直比 cursor 小 1。所以 hasNext() 实现很简单:
+
+### next()
+实现其实也是比较简单,只要返回 cursor 索引位置处的元素即可,然后更新cursor、lastRet :
+```java
+public E next() {
+ checkForComodification();
+ // 记录索引位置
+ int i = cursor;
+ // 如果获取元素大于集合元素个数,则抛出异常
+ if (i >= size)
+ throw new NoSuchElementException();
+ Object[] elementData = ArrayList.this.elementData;
+ if (i >= elementData.length)
+ throw new ConcurrentModificationException();
+ // cursor + 1
+ cursor = i + 1;
+ // lastRet + 1 且返回cursor处元素
+ return (E) elementData[lastRet = i];
+}
+```
+checkForComodification() 主要判断集合的修改次数是否合法,即判断遍历过程中集合是否被修改过。
+modCount 用于记录 ArrayList 集合的修改次数,初始化为 0。每当集合被修改一次(结构上面的修改,内部update不算),如 add、remove 等方法,modCount + 1。
+所以若 modCount 不变,则表示集合内容未被修改。该机制主要用于实现 ArrayList 集合的快速失败机制。所以要保证在遍历过程中不出错误,我们就应该保证在遍历过程中不会对集合产生结构上的修改(当然 remove 方法除外),出现了异常错误,我们就应该认真检查程序是否出错而不是 catch 后不做处理。
+
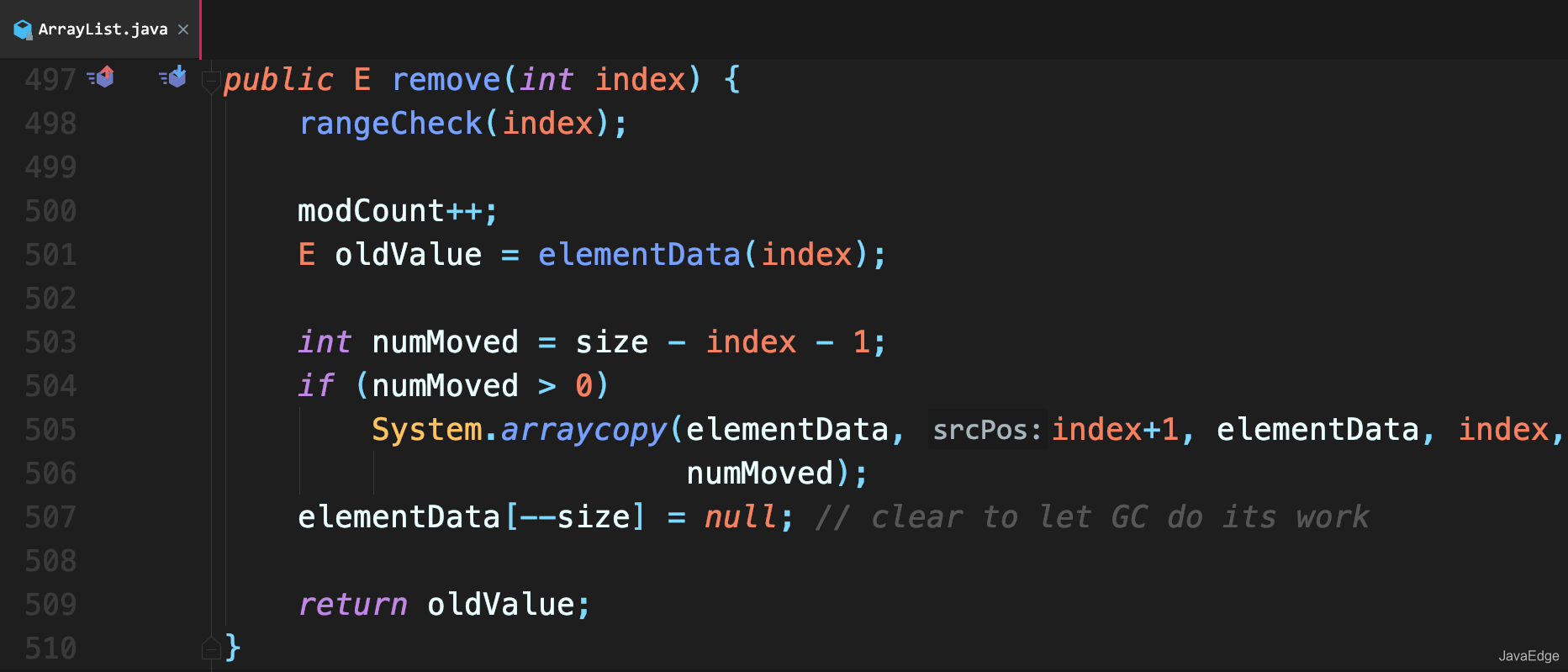
+### remove()
+调用 ArrayList 本身的 remove() 方法删除 lastRet 位置元素,然后修改 modCount 即可。
+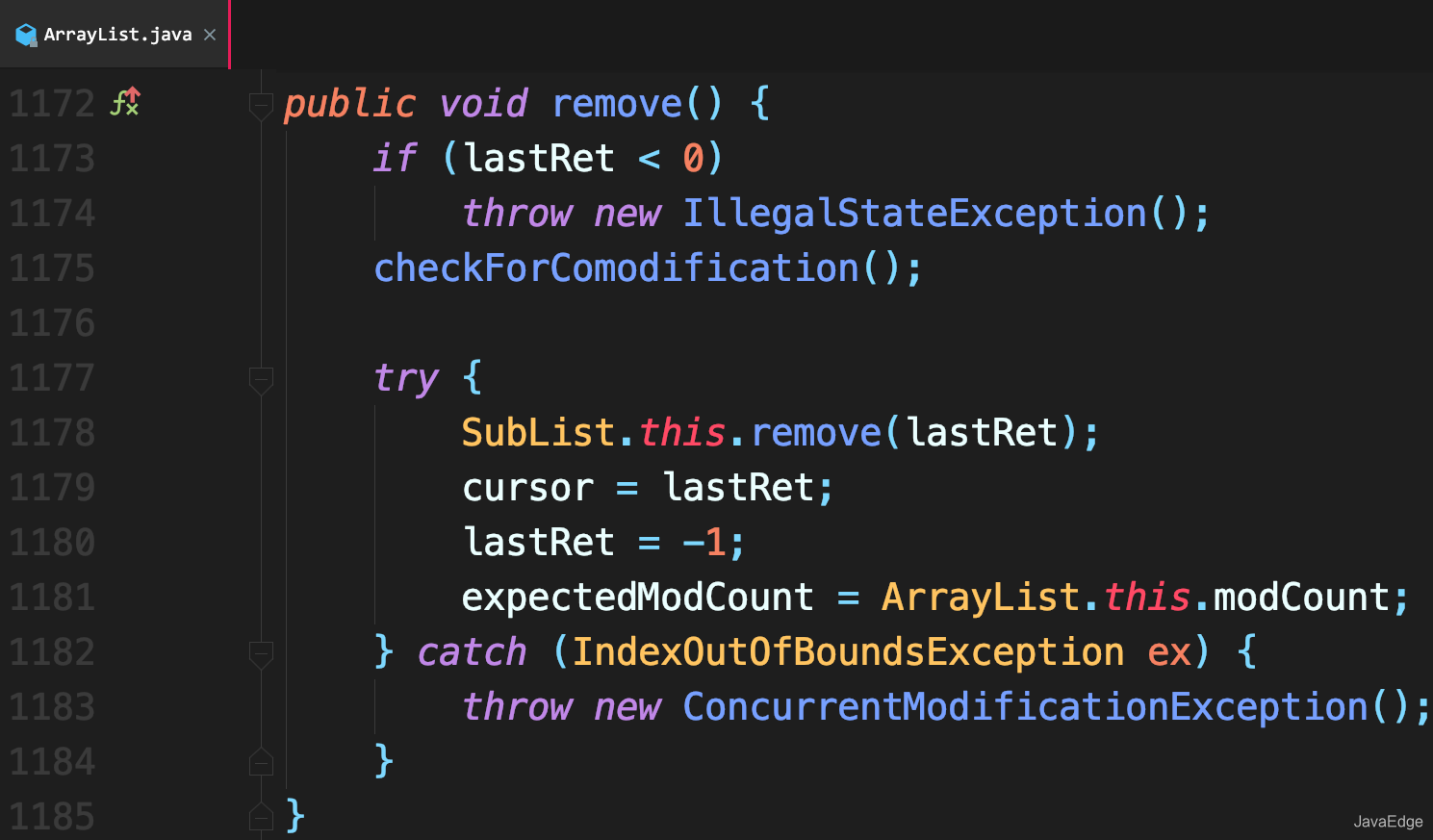
+- SubList.this#remove(lastRet)
+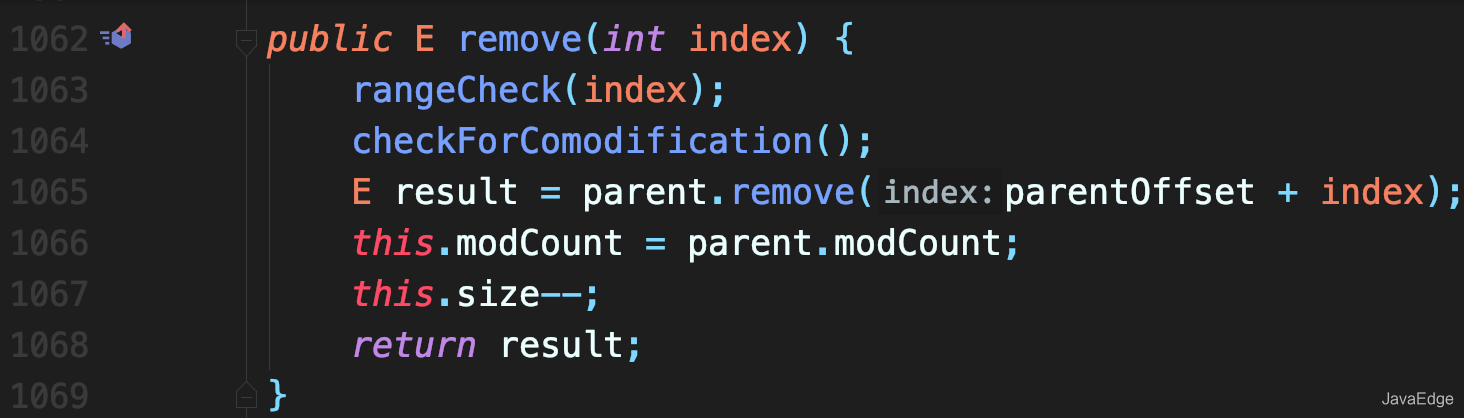
+- ArrayList#remove
+
\ No newline at end of file
diff --git a/Java/JAVA-Calendar.md "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/JAVA-Calendar.md"
similarity index 100%
rename from Java/JAVA-Calendar.md
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/JAVA-Calendar.md"
diff --git "a/Java/Java-Map\347\232\204containsKey(Object-key)\345\222\214containsValue(Object-value)\346\226\271\346\263\225.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java-Map\347\232\204containsKey(Object-key)\345\222\214containsValue(Object-value)\346\226\271\346\263\225.md"
similarity index 100%
rename from "Java/Java-Map\347\232\204containsKey(Object-key)\345\222\214containsValue(Object-value)\346\226\271\346\263\225.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java-Map\347\232\204containsKey(Object-key)\345\222\214containsValue(Object-value)\346\226\271\346\263\225.md"
diff --git "a/Java/Java-\346\263\233\345\236\213\350\247\243\346\203\221\344\271\213---extends-T-\345\222\214---super-T-.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java-\346\263\233\345\236\213\350\247\243\346\203\221\344\271\213---extends-T-\345\222\214---super-T-.md"
similarity index 100%
rename from "Java/Java-\346\263\233\345\236\213\350\247\243\346\203\221\344\271\213---extends-T-\345\222\214---super-T-.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java-\346\263\233\345\236\213\350\247\243\346\203\221\344\271\213---extends-T-\345\222\214---super-T-.md"
diff --git "a/Java/Java-\347\232\204\346\263\250\350\247\243.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java-\347\232\204\346\263\250\350\247\243.md"
similarity index 100%
rename from "Java/Java-\347\232\204\346\263\250\350\247\243.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java-\347\232\204\346\263\250\350\247\243.md"
diff --git "a/Java/Java8-\345\216\237\345\255\220\345\274\271\347\261\273\344\271\213LongAdder\346\272\220\347\240\201\345\210\206\346\236\220.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8-\345\216\237\345\255\220\345\274\271\347\261\273\344\271\213LongAdder\346\272\220\347\240\201\345\210\206\346\236\220.md"
similarity index 100%
rename from "Java/Java8-\345\216\237\345\255\220\345\274\271\347\261\273\344\271\213LongAdder\346\272\220\347\240\201\345\210\206\346\236\220.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8-\345\216\237\345\255\220\345\274\271\347\261\273\344\271\213LongAdder\346\272\220\347\240\201\345\210\206\346\236\220.md"
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\346\226\260\347\211\271\346\200\247\344\271\213Lambda\350\241\250\350\276\276\345\274\217&Stream\346\265\201&\346\226\271\346\263\225\345\274\225\347\224\250.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\346\226\260\347\211\271\346\200\247\344\271\213Lambda\350\241\250\350\276\276\345\274\217&Stream\346\265\201&\346\226\271\346\263\225\345\274\225\347\224\250.md"
new file mode 100644
index 0000000000..1801de8086
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\346\226\260\347\211\271\346\200\247\344\271\213Lambda\350\241\250\350\276\276\345\274\217&Stream\346\265\201&\346\226\271\346\263\225\345\274\225\347\224\250.md"
@@ -0,0 +1,1842 @@
+> 集合优化了对象的存储,而流和对象的处理有关。
+
+流是一系列与特定存储机制无关的元素——实际上,流并没有“存储”之说。
+
+利用流,无需迭代集合中的元素,就可以提取和操作它们。这些管道通常被组合在一起,在流上形成一条操作管道。
+
+大多数情况下,将对象存储在集合是为了处理他们,因此你将会发现编程焦点从集合转移到了流。流的一个核心好处是,它使得**程序更加短小并且更易理解**。当 Lambda 表达式和方法引用和流一起使用的时候会让人感觉自成一体。流使得 Java 8 更添魅力。
+
+假如你要随机展示 5 至 20 之间不重复的整数并进行排序。实际上,你的关注点首先是创建一个有序集合。围绕这个集合进行后续操作。但使用流式编程,就可以简单陈述你想做什么:
+```java
+// streams/Randoms.java
+import java.util.*;
+public class Randoms {
+ public static void main(String[] args) {
+ new Random(47)
+ .ints(5, 20)
+ .distinct()
+ .limit(7)
+ .sorted()
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+6
+10
+13
+16
+17
+18
+19
+```
+
+首先,我们给 **Random** 对象一个种子(以便程序再次运行时产生相同的输出)。`ints()` 方法产生一个流并且 `ints()` 方法有多种方式的重载 — 两个参数限定了数值产生的边界。这将生成一个整数流。我们可以使用中间流操作(intermediate stream operation) `distinct()` 来获取它们的非重复值,然后使用 `limit()` 方法获取前 7 个元素。接下来,我们使用 `sorted()` 方法排序。最终使用 `forEach()` 方法遍历输出,它根据传递给它的函数对每个流对象执行操作。在这里,我们传递了一个可以在控制台显示每个元素的方法引用。`System.out::println` 。
+
+注意 `Randoms.java` 中没有声明任何变量。流可以在不使用赋值或可变数据的情况下对有状态的系统建模,这非常有用。
+
+声明式编程(Declarative programming)是一种:声明要做什么,而非怎么做的编程风格。正如我们在函数式编程中所看到的。**注意**,命令式编程的形式更难以理解。代码示例:
+
+```java
+// streams/ImperativeRandoms.java
+import java.util.*;
+public class ImperativeRandoms {
+ public static void main(String[] args) {
+ Random rand = new Random(47);
+ SortedSet rints = new TreeSet<>();
+ while(rints.size() < 7) {
+ int r = rand.nextInt(20);
+ if(r < 5) continue;
+ rints.add(r);
+ }
+ System.out.println(rints);
+ }
+}
+```
+
+输出结果:
+
+```
+[7, 8, 9, 11, 13, 15, 18]
+```
+
+在 `Randoms.java` 中,我们无需定义任何变量,但在这里我们定义了 3 个变量: `rand`,`rints` 和 `r`。由于 `nextInt()` 方法没有下限的原因(其内置的下限永远为 0),这段代码实现起来更复杂。所以我们要生成额外的值来过滤小于 5 的结果。
+
+**注意**,你必须要研究程序的真正意图,而在 `Randoms.java` 中,代码只是告诉了你它正在做什么。这种语义清晰性也是 Java 8 的流式编程更受推崇的重要原因。
+
+在 `ImperativeRandoms.java` 中显式地编写迭代机制称为外部迭代。而在 `Randoms.java` 中,流式编程采用内部迭代,这是流式编程的核心特性之一。这种机制使得编写的代码可读性更强,也更能利用多核处理器的优势。通过放弃对迭代过程的控制,我们把控制权交给并行化机制。我们将在[并发编程](24-Concurrent-Programming.md)一章中学习这部分内容。
+
+另一个重要方面,流是懒加载的。这代表着它只在绝对必要时才计算。你可以将流看作“延迟列表”。由于计算延迟,流使我们能够表示非常大(甚至无限)的序列,而不需要考虑内存问题。
+
+
+
+## 流支持
+
+Java 设计者面临着这样一个难题:现存的大量类库不仅为 Java 所用,同时也被应用在整个 Java 生态圈数百万行的代码中。如何将一个全新的流的概念融入到现有类库中呢?
+
+比如在 **Random** 中添加更多的方法。只要不改变原有的方法,现有代码就不会受到干扰。
+
+问题是,接口部分怎么改造呢?特别是涉及集合类接口的部分。如果你想把一个集合转换为流,直接向接口添加新方法会破坏所有老的接口实现类。
+
+Java 8 采用的解决方案是:在[接口](10-Interfaces.md)中添加被 `default`(`默认`)修饰的方法。通过这种方案,设计者们可以将流式(*stream*)方法平滑地嵌入到现有类中。流方法预置的操作几乎已满足了我们平常所有的需求。流操作的类型有三种:创建流,修改流元素(中间操作, Intermediate Operations),消费流元素(终端操作, Terminal Operations)。最后一种类型通常意味着收集流元素(通常是到集合中)。
+
+下面我们来看下每种类型的流操作。
+
+
+## 流创建
+
+你可以通过 `Stream.of()` 很容易地将一组元素转化成为流(`Bubble` 类在本章的后面定义):
+
+```java
+// streams/StreamOf.java
+import java.util.stream.*;
+public class StreamOf {
+ public static void main(String[] args) {
+ Stream.of(new Bubble(1), new Bubble(2), new Bubble(3))
+ .forEach(System.out::println);
+ Stream.of("It's ", "a ", "wonderful ", "day ", "for ", "pie!")
+ .forEach(System.out::print);
+ System.out.println();
+ Stream.of(3.14159, 2.718, 1.618)
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+Bubble(1)
+Bubble(2)
+Bubble(3)
+It's a wonderful day for pie!
+3.14159
+2.718
+1.618
+```
+
+每个集合都可通过 `stream()` 产生一个流。示例:
+
+```java
+import java.util.*;
+import java.util.stream.*;
+public class CollectionToStream {
+ public static void main(String[] args) {
+ List bubbles = Arrays.asList(new Bubble(1), new Bubble(2), new Bubble(3));
+ System.out.println(bubbles.stream()
+ .mapToInt(b -> b.i)
+ .sum());
+
+ Set w = new HashSet<>(Arrays.asList("It's a wonderful day for pie!".split(" ")));
+ w.stream()
+ .map(x -> x + " ")
+ .forEach(System.out::print);
+ System.out.println();
+
+ Map m = new HashMap<>();
+ m.put("pi", 3.14159);
+ m.put("e", 2.718);
+ m.put("phi", 1.618);
+ m.entrySet().stream()
+ .map(e -> e.getKey() + ": " + e.getValue())
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+6
+a pie! It's for wonderful day
+phi: 1.618
+e: 2.718
+pi: 3.14159
+```
+
+- 创建 `List` 对象后,只需简单调用**所有集合中都有**的 `stream()`。
+- 中间操作 `map()` 会获取流中的所有元素,并且对流中元素应用操作从而产生新的元素,并将其传递到后续的流中。通常 `map()` 会获取对象并产生新的对象,但在这里产生了特殊的用于数值类型的流。例如,`mapToInt()` 方法将一个对象流(object stream)转换成为包含整型数字的 `IntStream`。
+- 通过调用字符串的 `split()`来获取元素用于定义变量 `w`。
+- 为了从 **Map** 集合中产生流数据,我们首先调用 `entrySet()` 产生一个对象流,每个对象都包含一个 `key` 键以及与其相关联的 `value` 值。然后分别调用 `getKey()` 和 `getValue()` 获取值。
+
+### 随机数流
+
+`Random` 类被一组生成流的方法增强了。代码示例:
+
+```java
+// streams/RandomGenerators.java
+import java.util.*;
+import java.util.stream.*;
+public class RandomGenerators {
+ public static void show(Stream stream) {
+ stream
+ .limit(4)
+ .forEach(System.out::println);
+ System.out.println("++++++++");
+ }
+
+ public static void main(String[] args) {
+ Random rand = new Random(47);
+ show(rand.ints().boxed());
+ show(rand.longs().boxed());
+ show(rand.doubles().boxed());
+ // 控制上限和下限:
+ show(rand.ints(10, 20).boxed());
+ show(rand.longs(50, 100).boxed());
+ show(rand.doubles(20, 30).boxed());
+ // 控制流大小:
+ show(rand.ints(2).boxed());
+ show(rand.longs(2).boxed());
+ show(rand.doubles(2).boxed());
+ // 控制流的大小和界限
+ show(rand.ints(3, 3, 9).boxed());
+ show(rand.longs(3, 12, 22).boxed());
+ show(rand.doubles(3, 11.5, 12.3).boxed());
+ }
+}
+```
+
+输出结果:
+
+```
+-1172028779
+1717241110
+-2014573909
+229403722
+++++++++
+2955289354441303771
+3476817843704654257
+-8917117694134521474
+4941259272818818752
+++++++++
+0.2613610344283964
+0.0508673570556899
+0.8037155449603999
+0.7620665811558285
+++++++++
+16
+10
+11
+12
+++++++++
+65
+99
+54
+58
+++++++++
+29.86777681078574
+24.83968447804611
+20.09247112332014
+24.046793846338723
+++++++++
+1169976606
+1947946283
+++++++++
+2970202997824602425
+-2325326920272830366
+++++++++
+0.7024254510631527
+0.6648552384607359
+++++++++
+6
+7
+7
+++++++++
+17
+12
+20
+++++++++
+12.27872414236691
+11.732085449736195
+12.196509449817267
+++++++++
+```
+
+为了消除冗余代码,我创建了一个泛型方法 `show(Stream stream)` (在讲解泛型之前就使用这个特性,确实有点作弊,但是回报是值得的)。类型参数 `T` 可以是任何类型,所以这个方法对 **Integer**、**Long** 和 **Double** 类型都生效。但是 **Random** 类只能生成基本类型 **int**, **long**, **double** 的流。幸运的是, `boxed()` 流操作将会自动地把基本类型包装成为对应的装箱类型,从而使得 `show()` 能够接受流。
+
+我们可以使用 **Random** 为任意对象集合创建 **Supplier**。如下是一个文本文件提供字符串对象的例子。
+
+Cheese.dat 文件内容:
+
+```
+// streams/Cheese.dat
+Not much of a cheese shop really, is it?
+Finest in the district, sir.
+And what leads you to that conclusion?
+Well, it's so clean.
+It's certainly uncontaminated by cheese.
+```
+
+我们通过 **File** 类将 Cheese.dat 文件的所有行读取到 `List` 中。代码示例:
+
+```java
+// streams/RandomWords.java
+import java.util.*;
+import java.util.stream.*;
+import java.util.function.*;
+import java.io.*;
+import java.nio.file.*;
+public class RandomWords implements Supplier {
+ List words = new ArrayList<>();
+ Random rand = new Random(47);
+ RandomWords(String fname) throws IOException {
+ List lines = Files.readAllLines(Paths.get(fname));
+ // 略过第一行
+ for (String line : lines.subList(1, lines.size())) {
+ for (String word : line.split("[ .?,]+"))
+ words.add(word.toLowerCase());
+ }
+ }
+ public String get() {
+ return words.get(rand.nextInt(words.size()));
+ }
+ @Override
+ public String toString() {
+ return words.stream()
+ .collect(Collectors.joining(" "));
+ }
+ public static void main(String[] args) throws Exception {
+ System.out.println(
+ Stream.generate(new RandomWords("Cheese.dat"))
+ .limit(10)
+ .collect(Collectors.joining(" ")));
+ }
+}
+```
+
+输出结果:
+
+```
+it shop sir the much cheese by conclusion district is
+```
+
+在这里你可以看到更为复杂的 `split()` 运用。在构造器中,每一行都被 `split()` 通过空格或者被方括号包裹的任意标点符号进行分割。在结束方括号后面的 `+` 代表 `+` 前面的东西可以出现一次或者多次。
+
+我们注意到在构造函数中循环体使用命令式编程(外部迭代)。在以后的例子中,你甚至会看到我们如何消除这一点。这种旧的形式虽不是特别糟糕,但使用流会让人感觉更好。
+
+在 `toString()` 和主方法中你看到了 `collect()` 收集操作,它根据参数来组合所有流中的元素。
+
+当你使用 **Collectors.**`joining()`,你将会得到一个 `String` 类型的结果,每个元素都根据 `joining()` 的参数来进行分割。还有许多不同的 `Collectors` 用于产生不同的结果。
+
+在主方法中,我们提前看到了 **Stream.**`generate()` 的用法,它可以把任意 `Supplier` 用于生成 `T` 类型的流。
+
+
+### int 类型的范围
+
+`IntStream` 类提供了 `range()` 方法用于生成整型序列的流。编写循环时,这个方法会更加便利:
+
+```java
+// streams/Ranges.java
+import static java.util.stream.IntStream.*;
+public class Ranges {
+ public static void main(String[] args) {
+ // 传统方法:
+ int result = 0;
+ for (int i = 10; i < 20; i++)
+ result += i;
+ System.out.println(result);
+ // for-in 循环:
+ result = 0;
+ for (int i : range(10, 20).toArray())
+ result += i;
+ System.out.println(result);
+ // 使用流:
+ System.out.println(range(10, 20).sum());
+ }
+}
+```
+
+输出结果:
+
+```
+145
+145
+145
+```
+
+在主方法中的第一种方式是我们传统编写 `for` 循环的方式;第二种方式,我们使用 `range()` 创建了流并将其转化为数组,然后在 `for-in` 代码块中使用。但是,如果你能像第三种方法那样全程使用流是更好的。我们对范围中的数字进行求和。在流中可以很方便的使用 `sum()` 操作求和。
+
+注意 **IntStream.**`range()` 相比 `onjava.Range.range()` 拥有更多的限制。这是由于其可选的第三个参数,后者允许步长大于 1,并且可以从大到小来生成。
+
+实用小功能 `repeat()` 可以用来替换简单的 `for` 循环。代码示例:
+
+```java
+// onjava/Repeat.java
+package onjava;
+import static java.util.stream.IntStream.*;
+public class Repeat {
+ public static void repeat(int n, Runnable action) {
+ range(0, n).forEach(i -> action.run());
+ }
+}
+```
+
+其产生的循环更加清晰:
+
+```java
+// streams/Looping.java
+import static onjava.Repeat.*;
+public class Looping {
+ static void hi() {
+ System.out.println("Hi!");
+ }
+ public static void main(String[] args) {
+ repeat(3, () -> System.out.println("Looping!"));
+ repeat(2, Looping::hi);
+ }
+}
+```
+
+输出结果:
+
+```
+Looping!
+Looping!
+Looping!
+Hi!
+Hi!
+```
+
+原则上,在代码中包含并解释 `repeat()` 并不值得。诚然它是一个相当透明的工具,但结果取决于你的团队和公司的运作方式。
+
+### generate()
+
+参照 `RandomWords.java` 中 **Stream.**`generate()` 搭配 `Supplier` 使用的例子。代码示例:
+
+```java
+// streams/Generator.java
+import java.util.*;
+import java.util.function.*;
+import java.util.stream.*;
+
+public class Generator implements Supplier {
+ Random rand = new Random(47);
+ char[] letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ".toCharArray();
+
+ public String get() {
+ return "" + letters[rand.nextInt(letters.length)];
+ }
+
+ public static void main(String[] args) {
+ String word = Stream.generate(new Generator())
+ .limit(30)
+ .collect(Collectors.joining());
+ System.out.println(word);
+ }
+}
+```
+
+输出结果:
+
+```
+YNZBRNYGCFOWZNTCQRGSEGZMMJMROE
+```
+
+使用 `Random.nextInt()` 方法来挑选字母表中的大写字母。`Random.nextInt()` 的参数代表可以接受的最大的随机数范围,所以使用数组边界是经过深思熟虑的。
+
+如果要创建包含相同对象的流,只需要传递一个生成那些对象的 `lambda` 到 `generate()` 中:
+
+```java
+// streams/Duplicator.java
+import java.util.stream.*;
+public class Duplicator {
+ public static void main(String[] args) {
+ Stream.generate(() -> "duplicate")
+ .limit(3)
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+duplicate
+duplicate
+duplicate
+```
+
+如下是在本章之前例子中使用过的 `Bubble` 类。**注意**它包含了自己的静态生成器(Static generator)方法。
+
+```java
+// streams/Bubble.java
+import java.util.function.*;
+public class Bubble {
+ public final int i;
+
+ public Bubble(int n) {
+ i = n;
+ }
+
+ @Override
+ public String toString() {
+ return "Bubble(" + i + ")";
+ }
+
+ private static int count = 0;
+ public static Bubble bubbler() {
+ return new Bubble(count++);
+ }
+}
+```
+
+由于 `bubbler()` 与 `Supplier` 是接口兼容的,我们可以将其方法引用直接传递给 **Stream.**`generate()`:
+
+```java
+// streams/Bubbles.java
+import java.util.stream.*;
+public class Bubbles {
+ public static void main(String[] args) {
+ Stream.generate(Bubble::bubbler)
+ .limit(5)
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+Bubble(0)
+Bubble(1)
+Bubble(2)
+Bubble(3)
+Bubble(4)
+```
+
+这是创建单独工厂类(Separate Factory class)的另一种方式。在很多方面它更加整洁,但是这是一个对于代码组织和品味的问题——你总是可以创建一个完全不同的工厂类。
+
+### iterate()
+
+**Stream.**`iterate()` 以种子(第一个参数)开头,并将其传给方法(第二个参数)。方法的结果将添加到流,并存储作为第一个参数用于下次调用 `iterate()`,依次类推。我们可以利用 `iterate()` 生成一个斐波那契数列。代码示例:
+
+```java
+// streams/Fibonacci.java
+import java.util.stream.*;
+public class Fibonacci {
+ int x = 1;
+
+ Stream numbers() {
+ return Stream.iterate(0, i -> {
+ int result = x + i;
+ x = i;
+ return result;
+ });
+ }
+
+ public static void main(String[] args) {
+ new Fibonacci().numbers()
+ .skip(20) // 过滤前 20 个
+ .limit(10) // 然后取 10 个
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+6765
+10946
+17711
+28657
+46368
+75025
+121393
+196418
+317811
+514229
+```
+
+斐波那契数列将数列中最后两个元素进行求和以产生下一个元素。`iterate()` 只能记忆结果,因此我们需要利用一个变量 `x` 追踪另外一个元素。
+
+在主方法中,我们使用了一个之前没有见过的 `skip()` 操作。它根据参数丢弃指定数量的流元素。在这里,我们丢弃了前 20 个元素。
+
+### 流的建造者模式
+
+在建造者设计模式(也称构造器模式)中,首先创建一个 `builder` 对象,传递给它多个构造器信息,最后执行“构造”。**Stream** 库提供了这样的 `Builder`。在这里,我们重新审视文件读取并将其转换成为单词流的过程。代码示例:
+
+```java
+// streams/FileToWordsBuilder.java
+import java.io.*;
+import java.nio.file.*;
+import java.util.stream.*;
+
+public class FileToWordsBuilder {
+ Stream.Builder builder = Stream.builder();
+
+ public FileToWordsBuilder(String filePath) throws Exception {
+ Files.lines(Paths.get(filePath))
+ .skip(1) // 略过开头的注释行
+ .forEach(line -> {
+ for (String w : line.split("[ .?,]+"))
+ builder.add(w);
+ });
+ }
+
+ Stream stream() {
+ return builder.build();
+ }
+
+ public static void main(String[] args) throws Exception {
+ new FileToWordsBuilder("Cheese.dat")
+ .stream()
+ .limit(7)
+ .map(w -> w + " ")
+ .forEach(System.out::print);
+ }
+}
+```
+
+输出结果:
+
+```
+Not much of a cheese shop really
+```
+
+**注意**,构造器会添加文件中的所有单词(除了第一行,它是包含文件路径信息的注释),但是其并没有调用 `build()`。只要你不调用 `stream()` 方法,就可以继续向 `builder` 对象中添加单词。
+
+在该类的更完整形式中,你可以添加一个标志位用于查看 `build()` 是否被调用,并且可能的话增加一个可以添加更多单词的方法。在 `Stream.Builder` 调用 `build()` 方法后继续尝试添加单词会产生一个异常。
+
+### Arrays
+
+`Arrays` 类中含有一个名为 `stream()` 的静态方法用于把数组转换成为流。我们可以重写 `interfaces/Machine.java` 中的主方法用于创建一个流,并将 `execute()` 应用于每一个元素。代码示例:
+
+```java
+// streams/Machine2.java
+import java.util.*;
+import onjava.Operations;
+public class Machine2 {
+ public static void main(String[] args) {
+ Arrays.stream(new Operations[] {
+ () -> Operations.show("Bing"),
+ () -> Operations.show("Crack"),
+ () -> Operations.show("Twist"),
+ () -> Operations.show("Pop")
+ }).forEach(Operations::execute);
+ }
+}
+```
+
+输出结果:
+
+```
+Bing
+Crack
+Twist
+Pop
+```
+
+`new Operations[]` 表达式动态创建了 `Operations` 对象的数组。
+
+`stream()` 同样可以产生 **IntStream**,**LongStream** 和 **DoubleStream**。
+
+```java
+// streams/ArrayStreams.java
+import java.util.*;
+import java.util.stream.*;
+
+public class ArrayStreams {
+ public static void main(String[] args) {
+ Arrays.stream(new double[] { 3.14159, 2.718, 1.618 })
+ .forEach(n -> System.out.format("%f ", n));
+ System.out.println();
+
+ Arrays.stream(new int[] { 1, 3, 5 })
+ .forEach(n -> System.out.format("%d ", n));
+ System.out.println();
+
+ Arrays.stream(new long[] { 11, 22, 44, 66 })
+ .forEach(n -> System.out.format("%d ", n));
+ System.out.println();
+
+ // 选择一个子域:
+ Arrays.stream(new int[] { 1, 3, 5, 7, 15, 28, 37 }, 3, 6)
+ .forEach(n -> System.out.format("%d ", n));
+ }
+}
+```
+
+输出结果:
+
+```
+3.141590 2.718000 1.618000
+1 3 5
+11 22 44 66
+7 15 28
+```
+
+最后一次 `stream()` 的调用有两个额外的参数。第一个参数告诉 `stream()` 从数组的哪个位置开始选择元素,第二个参数用于告知在哪里停止。每种不同类型的 `stream()` 都有类似的操作。
+
+### 正则表达式
+
+Java 的正则表达式将在[字符串](18-Strings.md)这一章节详细介绍。Java 8 在 `java.util.regex.Pattern` 中增加了一个新的方法 `splitAsStream()`。这个方法可以根据传入的公式将字符序列转化为流。但是有一个限制,输入只能是 **CharSequence**,因此不能将流作为 `splitAsStream()` 的参数。
+
+我们再一次查看将文件处理为单词流的过程。这一次,我们使用流将文件分割为单独的字符串,接着使用正则表达式将字符串转化为单词流。
+
+```java
+// streams/FileToWordsRegexp.java
+import java.io.*;
+import java.nio.file.*;
+import java.util.stream.*;
+import java.util.regex.Pattern;
+public class FileToWordsRegexp {
+ private String all;
+ public FileToWordsRegexp(String filePath) throws Exception {
+ all = Files.lines(Paths.get(filePath))
+ .skip(1) // First (comment) line
+ .collect(Collectors.joining(" "));
+ }
+ public Stream stream() {
+ return Pattern
+ .compile("[ .,?]+").splitAsStream(all);
+ }
+ public static void
+ main(String[] args) throws Exception {
+ FileToWordsRegexp fw = new FileToWordsRegexp("Cheese.dat");
+ fw.stream()
+ .limit(7)
+ .map(w -> w + " ")
+ .forEach(System.out::print);
+ fw.stream()
+ .skip(7)
+ .limit(2)
+ .map(w -> w + " ")
+ .forEach(System.out::print);
+ }
+}
+```
+
+输出结果:
+
+```
+Not much of a cheese shop really is it
+```
+
+在构造器中我们读取了文件中的所有内容(跳过第一行注释,并将其转化成为单行字符串)。现在,当你调用 `stream()` 的时候,可以像往常一样获取一个流,但这次你可以多次调用 `stream()` 在已存储的字符串中创建一个新的流。这里有个限制,整个文件必须存储在内存中;在大多数情况下这并不是什么问题,但是这损失了流操作非常重要的优势:
+
+1. 流“不需要存储”。当然它们需要一些内部存储,但是这只是序列的一小部分,和持有整个序列并不相同。
+2. 它们是懒加载计算的。
+
+幸运的是,我们稍后就会知道如何解决这个问题。
+
+
+
+## 中间操作
+
+中间操作用于从一个流中获取对象,并将对象作为另一个流从后端输出,以连接到其他操作。
+
+### 跟踪和调试
+
+`peek()` 操作的目的是帮助调试。它允许你无修改地查看流中的元素。代码示例:
+
+```java
+// streams/Peeking.java
+class Peeking {
+ public static void main(String[] args) throws Exception {
+ FileToWords.stream("Cheese.dat")
+ .skip(21)
+ .limit(4)
+ .map(w -> w + " ")
+ .peek(System.out::print)
+ .map(String::toUpperCase)
+ .peek(System.out::print)
+ .map(String::toLowerCase)
+ .forEach(System.out::print);
+ }
+}
+```
+
+输出结果:
+
+```
+Well WELL well it IT it s S s so SO so
+```
+
+`FileToWords` 稍后定义,但它的功能实现貌似和之前我们看到的差不多:产生字符串对象的流。之后在其通过管道时调用 `peek()` 进行处理。
+
+因为 `peek()` 符合无返回值的 **Consumer** 函数式接口,所以我们只能观察,无法使用不同的元素来替换流中的对象。
+
+### 流元素排序
+
+在 `Randoms.java` 中,我们熟识了 `sorted()` 的默认比较器实现。其实它还有另一种形式的实现:传入一个 **Comparator** 参数。代码示例:
+
+```java
+// streams/SortedComparator.java
+import java.util.*;
+public class SortedComparator {
+ public static void main(String[] args) throws Exception {
+ FileToWords.stream("Cheese.dat")
+ .skip(10)
+ .limit(10)
+ .sorted(Comparator.reverseOrder())
+ .map(w -> w + " ")
+ .forEach(System.out::print);
+ }
+}
+```
+
+输出结果:
+
+```
+you what to the that sir leads in district And
+```
+
+`sorted()` 预设了一些默认的比较器。这里我们使用的是反转“自然排序”。当然你也可以把 Lambda 函数作为参数传递给 `sorted()`。
+
+### 移除元素
+
+* `distinct()`:在 `Randoms.java` 类中的 `distinct()` 可用于消除流中的重复元素。相比创建一个 **Set** 集合,该方法的工作量要少得多。
+
+* `filter(Predicate)`:过滤操作会保留与传递进去的过滤器函数计算结果为 `true` 的元素。
+
+在下例中,`isPrime()` 作为过滤器函数,用于检测质数。
+
+```java
+import java.util.stream.*;
+import static java.util.stream.LongStream.*;
+public class Prime {
+ public static Boolean isPrime(long n) {
+ return rangeClosed(2, (long)Math.sqrt(n))
+ .noneMatch(i -> n % i == 0);
+ }
+ public LongStream numbers() {
+ return iterate(2, i -> i + 1)
+ .filter(Prime::isPrime);
+ }
+ public static void main(String[] args) {
+ new Prime().numbers()
+ .limit(10)
+ .forEach(n -> System.out.format("%d ", n));
+ System.out.println();
+ new Prime().numbers()
+ .skip(90)
+ .limit(10)
+ .forEach(n -> System.out.format("%d ", n));
+ }
+}
+```
+
+输出结果:
+
+```
+2 3 5 7 11 13 17 19 23 29
+467 479 487 491 499 503 509 521 523 541
+```
+
+`rangeClosed()` 包含了上限值。如果不能整除,即余数不等于 0,则 `noneMatch()` 操作返回 `true`,如果出现任何等于 0 的结果则返回 `false`。 `noneMatch()` 操作一旦有失败就会退出。
+
+### 应用函数到元素
+
+- `map(Function)`:将函数操作应用在输入流的元素中,并将返回值传递到输出流中。
+
+- `mapToInt(ToIntFunction)`:操作同上,但结果是 **IntStream**。
+
+- `mapToLong(ToLongFunction)`:操作同上,但结果是 **LongStream**。
+
+- `mapToDouble(ToDoubleFunction)`:操作同上,但结果是 **DoubleStream**。
+
+在这里,我们使用 `map()` 映射多种函数到一个字符串流中。代码示例:
+
+```java
+// streams/FunctionMap.java
+import java.util.*;
+import java.util.stream.*;
+import java.util.function.*;
+class FunctionMap {
+ static String[] elements = { "12", "", "23", "45" };
+ static Stream
+ testStream() {
+ return Arrays.stream(elements);
+ }
+ static void test(String descr, Function func) {
+ System.out.println(" ---( " + descr + " )---");
+ testStream()
+ .map(func)
+ .forEach(System.out::println);
+ }
+ public static void main(String[] args) {
+ test("add brackets", s -> "[" + s + "]");
+ test("Increment", s -> {
+ try {
+ return Integer.parseInt(s) + 1 + "";
+ }
+ catch(NumberFormatException e) {
+ return s;
+ }
+ }
+ );
+ test("Replace", s -> s.replace("2", "9"));
+ test("Take last digit", s -> s.length() > 0 ?
+ s.charAt(s.length() - 1) + "" : s);
+ }
+}
+```
+
+输出结果:
+
+```
+---( add brackets )---
+[12]
+[]
+[23]
+[45]
+---( Increment )---
+13
+24
+46
+---( Replace )---
+19
+93
+45
+---( Take last digit )---
+2
+3
+5
+```
+
+在上面的自增示例中,我们使用 `Integer.parseInt()` 尝试将一个字符串转化为整数。如果字符串不能转化成为整数就会抛出 **NumberFormatException** 异常,我们只须回过头来将原始字符串放回到输出流中。
+
+在以上例子中,`map()` 将一个字符串映射为另一个字符串,但是我们完全可以产生和接收类型完全不同的类型,从而改变流的数据类型。下面代码示例:
+
+```java
+// streams/FunctionMap2.java
+// Different input and output types (不同的输入输出类型)
+import java.util.*;
+import java.util.stream.*;
+class Numbered {
+ final int n;
+ Numbered(int n) {
+ this.n = n;
+ }
+ @Override
+ public String toString() {
+ return "Numbered(" + n + ")";
+ }
+}
+class FunctionMap2 {
+ public static void main(String[] args) {
+ Stream.of(1, 5, 7, 9, 11, 13)
+ .map(Numbered::new)
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+Numbered(1)
+Numbered(5)
+Numbered(7)
+Numbered(9)
+Numbered(11)
+Numbered(13)
+```
+
+我们将获取到的整数通过构造器 `Numbered::new` 转化成为 `Numbered` 类型。
+
+如果使用 **Function** 返回的结果是数值类型的一种,我们必须使用合适的 `mapTo数值类型` 进行替代。代码示例:
+
+```java
+// streams/FunctionMap3.java
+// Producing numeric output streams( 产生数值输出流)
+import java.util.*;
+import java.util.stream.*;
+class FunctionMap3 {
+ public static void main(String[] args) {
+ Stream.of("5", "7", "9")
+ .mapToInt(Integer::parseInt)
+ .forEach(n -> System.out.format("%d ", n));
+ System.out.println();
+ Stream.of("17", "19", "23")
+ .mapToLong(Long::parseLong)
+ .forEach(n -> System.out.format("%d ", n));
+ System.out.println();
+ Stream.of("17", "1.9", ".23")
+ .mapToDouble(Double::parseDouble)
+ .forEach(n -> System.out.format("%f ", n));
+ }
+}
+```
+
+输出结果:
+
+```
+5 7 9
+17 19 23
+17.000000 1.900000 0.230000
+```
+
+遗憾的是,Java 设计者并没有尽最大努力去消除基本类型。
+
+### 在 `map()` 中组合流
+假设现有一个传入的元素流,并且打算对流元素使用 `map()` 函数。现在你已经找到了一些可爱并独一无二的函数功能,但问题来了:这个函数功能是产生一个流。我们想要产生一个元素流,而实际却产生了一个元素流的流。
+
+`flatMap()` 做了两件事:
+- 将产生流的函数应用在每个元素上(与 `map()` 所做的相同)
+- 然后将每个流都扁平化为元素
+
+因而最终产生的仅是元素。
+
+`flatMap(Function)`:当 `Function` 产生流时使用。
+
+`flatMapToInt(Function)`:当 `Function` 产生 `IntStream` 时使用。
+
+`flatMapToLong(Function)`:当 `Function` 产生 `LongStream` 时使用。
+
+`flatMapToDouble(Function)`:当 `Function` 产生 `DoubleStream` 时使用。
+
+为了弄清其工作原理,我们从传入一个刻意设计的函数给 `map()` 开始。该函数接受一个整数并产生一个字符串流:
+
+我们天真地希望能够得到字符串流,但实际得到的却是“Head”流的流。
+可使用 `flatMap()` 解决:
+
+从map返回的每个流都会自动扁平为组成它的字符串。
+
+现在从一个整数流开始,然后使用每个整数去创建更多的随机数。
+
+ `concat()`以参数顺序组合两个流。 如此,我们在每个随机 `Integer` 流的末尾添加一个 -1 作为标记。你可以看到最终流确实是从一组扁平流中创建的。
+
+因为 `rand.ints()` 产生的是一个 `IntStream`,所以必须使用 `flatMap()`、`concat()` 和 `of()` 的特定整数形式。
+
+将文件划分为单词流。
+最后使用到的是 **FileToWordsRegexp.java**,它的问题是需要将整个文件读入行列表中 —— 显然需要存储该列表。而我们真正想要的是创建一个不需要中间存储层的单词流。
+
+下面,我们再使用 ` flatMap()` 来解决这个问题:
+
+`stream()` 现在是个静态方法,因为它可自己完成整个流创建过程。
+
+**注意**:`\\W+` 是一个正则表达式,表示非单词字符,`+` 表示可出现一或多次。小写形式的 `\\w` 表示“单词字符”。
+
+之前遇到的问题是 `Pattern.compile().splitAsStream()` 产生的结果为流,这意味着当只想要一个简单的单词流时,在传入的行流(stream of lines)上调用 `map()` 会产生一个单词流的流。
+好在 `flatMap()` 可将**元素流的流**扁平化为一个**简单的元素流**。或者,可使用 `String.split()` 生成一个数组,其可以被 `Arrays.stream()` 转化成为流:
+```java
+.flatMap(line -> Arrays.stream(line.split("\\W+"))))
+```
+有了真正的、而非 `FileToWordsRegexp.java` 中基于集合存储的流,我们每次使用都必须从头创建,因为流不能被复用:
+
+在 `System.out.format()` 中的 `%s` 表明参数为 **String** 类型。
+
+## Optional类
+若在一个空流取元素会发生什么?我们喜欢为了“happy path”而将流连接起来,并假设流不会被中断。在流中放置 `null` 就是个很好的中断方法。那么是否有某种对象,可作为流元素的持有者,即使查看的元素不存在也能友好地提示我们(即不会粗暴地抛异常)?
+
+**Optional** 就可以。一些标准流操作返回 **Optional** 对象,因为它们**并不能保证预期结果一定存在**:
+- `findFirst()`
+返回一个包含第一个元素的 **Optional** 对象,若流为空则返回 **Optional.empty**
+- `findAny()`
+返回包含任意元素的 **Optional** 对象,若流为空则返回 **Optional.empty**
+- `max()` 和 `min()`
+返回一个包含最大值或者最小值的 **Optional** 对象,若流为空则返回 **Optional.empty**
+
+ `reduce()` 不再以 `identity` 形式开头,而是将其返回值包装在 **Optional** 中。(`identity` 对象成为其他形式的 `reduce()` 的默认结果,因此不存在空结果的风险)
+
+对于数字流 **IntStream**、**LongStream** 和 **DoubleStream**,`average()` 会将结果包装在 **Optional** 以防止流为空。
+
+以下是对空流进行所有这些操作的简单测试:
+```java
+class OptionalsFromEmptyStreams {
+ public static void main(String[] args) {
+ System.out.println(Stream.empty()
+ .findFirst());
+ System.out.println(Stream.empty()
+ .findAny());
+ System.out.println(Stream.empty()
+ .max(String.CASE_INSENSITIVE_ORDER));
+ System.out.println(Stream.empty()
+ .min(String.CASE_INSENSITIVE_ORDER));
+ System.out.println(Stream.empty()
+ .reduce((s1, s2) -> s1 + s2));
+ System.out.println(IntStream.empty()
+ .average());
+ }
+}
+
+Optional.empty
+Optional.empty
+Optional.empty
+Optional.empty
+Optional.empty
+OptionalDouble.empty
+```
+
+当流为空的时候你会获得一个 **Optional.empty** 对象,而不是抛异常。**Optional** 的 `toString()` 方法可以用于展示有用信息。
+
+空流是通过 `Stream.empty()` 创建的。如果你在没有任何上下文环境的情况下调用 `Stream.empty()`,Java 并不知道它的数据类型;这个语法解决了这个问题。如果编译器拥有了足够的上下文信息,比如:
+```java
+Stream s = Stream.empty();
+```
+就可以在调用 `empty()` 时推断类型。
+
+**Optional** 的两个基本用法:
+```java
+class OptionalBasics {
+ static void test(Optional optString) {
+ if(optString.isPresent())
+ System.out.println(optString.get());
+ else
+ System.out.println("Nothing inside!");
+ }
+ public static void main(String[] args) {
+ test(Stream.of("Epithets").findFirst());
+ test(Stream.empty().findFirst());
+ }
+}
+
+Epithets
+Nothing inside!
+```
+
+当你接收到 **Optional** 对象时,应首先调用 `isPresent()` 检查其中是否包含元素。如果存在,可使用 `get()` 获取。
+
+### 便利函数
+有许多便利函数可以解包 **Optional** ,这简化了上述“对所包含的对象的检查和执行操作”的过程:
+
+- `ifPresent(Consumer)`:当值存在时调用 **Consumer**,否则什么也不做。
+- `orElse(otherObject)`:如果值存在则直接返回,否则生成 **otherObject**。
+- `orElseGet(Supplier)`:如果值存在则直接返回,否则使用 **Supplier** 函数生成一个可替代对象。
+- `orElseThrow(Supplier)`:如果值存在直接返回,否则使用 **Supplier** 函数生成一个异常。
+
+如下是针对不同便利函数的简单演示:
+```java
+public class Optionals {
+ static void basics(Optional optString) {
+ if(optString.isPresent())
+ System.out.println(optString.get());
+ else
+ System.out.println("Nothing inside!");
+ }
+ static void ifPresent(Optional optString) {
+ optString.ifPresent(System.out::println);
+ }
+ static void orElse(Optional optString) {
+ System.out.println(optString.orElse("Nada"));
+ }
+ static void orElseGet(Optional optString) {
+ System.out.println(
+ optString.orElseGet(() -> "Generated"));
+ }
+ static void orElseThrow(Optional optString) {
+ try {
+ System.out.println(optString.orElseThrow(
+ () -> new Exception("Supplied")));
+ } catch(Exception e) {
+ System.out.println("Caught " + e);
+ }
+ }
+ static void test(String testName, Consumer> cos) {
+ System.out.println(" === " + testName + " === ");
+ cos.accept(Stream.of("Epithets").findFirst());
+ cos.accept(Stream.empty().findFirst());
+ }
+ public static void main(String[] args) {
+ test("basics", Optionals::basics);
+ test("ifPresent", Optionals::ifPresent);
+ test("orElse", Optionals::orElse);
+ test("orElseGet", Optionals::orElseGet);
+ test("orElseThrow", Optionals::orElseThrow);
+ }
+}
+
+=== basics ===
+Epithets
+Nothing inside!
+=== ifPresent ===
+Epithets
+=== orElse ===
+Epithets
+Nada
+=== orElseGet ===
+Epithets
+Generated
+=== orElseThrow ===
+Epithets
+Caught java.lang.Exception: Supplied
+```
+
+`test()` 通过传入所有方法都适用的 **Consumer** 来避免重复代码。
+
+`orElseThrow()` 通过 **catch** 关键字来捕获抛出的异常。
+### 创建 Optional
+当我们在自己的代码中加入 **Optional** 时,可以使用下面 3 个静态方法:
+- `empty()`:生成一个空 **Optional**。
+- `of(value)`:将一个非空值包装到 **Optional** 里。
+- `ofNullable(value)`:针对一个可能为空的值,为空时自动生成 **Optional.empty**,否则将值包装在 **Optional** 中。
+
+代码示例:
+```java
+class CreatingOptionals {
+ static void test(String testName, Optional opt) {
+ System.out.println(" === " + testName + " === ");
+ System.out.println(opt.orElse("Null"));
+ }
+ public static void main(String[] args) {
+ test("empty", Optional.empty());
+ test("of", Optional.of("Howdy"));
+ try {
+ test("of", Optional.of(null));
+ } catch(Exception e) {
+ System.out.println(e);
+ }
+ test("ofNullable", Optional.ofNullable("Hi"));
+ test("ofNullable", Optional.ofNullable(null));
+ }
+}
+
+=== empty ===
+Null
+=== of ===
+Howdy
+java.lang.NullPointerException
+=== ofNullable ===
+Hi
+=== ofNullable ===
+Null
+```
+
+我们不能通过传递 `null` 到 `of()` 来创建 `Optional` 对象。最安全的方法是, 使用 `ofNullable()` 来优雅地处理 `null`。
+
+### Optional 对象操作
+当我们的流管道生成了 **Optional** 对象,如下方法可使得 **Optional** 的后续能做更多操作:
+
+- `filter(Predicate)`:将 **Predicate** 应用于 **Optional** 中的内容并返回结果。当 **Optional** 不满足 **Predicate** 时返回空。如果 **Optional** 为空,则直接返回。
+
+- `map(Function)`:如果 **Optional** 不为空,应用 **Function** 于 **Optional** 中的内容,并返回结果。否则直接返回 **Optional.empty**。
+
+- `flatMap(Function)`:同 `map()`,但是提供的映射函数将结果包装在 **Optional** 对象中,因此 `flatMap()` 不会在最后进行任何包装。
+
+以上方法都不适用于数值型 **Optional**。
+一般来说,流的 `filter()` 会在 **Predicate** 返回 `false` 时移除流元素。
+而 `Optional.filter()` 在失败时不会删除 **Optional**,而是将其保留下来,并转化为空。
+
+```java
+class OptionalFilter {
+ static String[] elements = {
+ "Foo", "", "Bar", "Baz", "Bingo"
+ };
+ static Stream testStream() {
+ return Arrays.stream(elements);
+ }
+ static void test(String descr, Predicate pred) {
+ System.out.println(" ---( " + descr + " )---");
+ for(int i = 0; i <= elements.length; i++) {
+ System.out.println(
+ testStream()
+ .skip(i)
+ .findFirst()
+ .filter(pred));
+ }
+ }
+ public static void main(String[] args) {
+ test("true", str -> true);
+ test("false", str -> false);
+ test("str != \"\"", str -> str != "");
+ test("str.length() == 3", str -> str.length() == 3);
+ test("startsWith(\"B\")",
+ str -> str.startsWith("B"));
+ }
+}
+```
+即使输出看起来像流,特别是 `test()` 中的 for 循环。每一次的 for 循环时重新启动流,然后根据 for 循环的索引跳过指定个数的元素,这就是它最终在流中的每个连续元素上的结果。接下来调用 `findFirst()` 获取剩余元素中的第一个元素,结果会包装在 **Optional** 中。
+
+**注意**,不同于普通 for 循环,这里的索引值范围并不是 `i < elements.length`, 而是 `i <= elements.length`。所以最后一个元素实际上超出了流。方便的是,这将自动成为 **Optional.empty**。
+
+同 `map()` 一样 , `Optional.map()` 应用于函数。它仅在 **Optional** 不为空时才应用映射函数,并将 **Optional** 的内容提取到映射函数。代码示例:
+
+```java
+class OptionalMap {
+ static String[] elements = {"12", "", "23", "45"};
+
+ static Stream testStream() {
+ return Arrays.stream(elements);
+ }
+
+ static void test(String descr, Function func) {
+ System.out.println(" ---( " + descr + " )---");
+ for (int i = 0; i <= elements.length; i++) {
+ System.out.println(
+ testStream()
+ .skip(i)
+ .findFirst() // Produces an Optional
+ .map(func));
+ }
+ }
+
+ public static void main(String[] args) {
+ // If Optional is not empty, map() first extracts
+ // the contents which it then passes
+ // to the function:
+ test("Add brackets", s -> "[" + s + "]");
+ test("Increment", s -> {
+ try {
+ return Integer.parseInt(s) + 1 + "";
+ } catch (NumberFormatException e) {
+ return s;
+ }
+ });
+ test("Replace", s -> s.replace("2", "9"));
+ test("Take last digit", s -> s.length() > 0 ?
+ s.charAt(s.length() - 1) + "" : s);
+ }
+ // After the function is finished, map() wraps the
+ // result in an Optional before returning it:
+}
+```
+映射函数的返回结果会自动包装成为 **Optional**。**Optional.empty** 会被直接跳过。
+
+**Optional** 的 `flatMap()` 应用于已生成 **Optional** 的映射函数,所以 `flatMap()` 不会像 `map()` 那样将结果封装在 **Optional** 中。代码示例:
+
+```java
+// streams/OptionalFlatMap.java
+import java.util.Arrays;
+import java.util.Optional;
+import java.util.function.Function;
+import java.util.stream.Stream;
+
+class OptionalFlatMap {
+ static String[] elements = {"12", "", "23", "45"};
+
+ static Stream testStream() {
+ return Arrays.stream(elements);
+ }
+
+ static void test(String descr,
+ Function> func) {
+ System.out.println(" ---( " + descr + " )---");
+ for (int i = 0; i <= elements.length; i++) {
+ System.out.println(
+ testStream()
+ .skip(i)
+ .findFirst()
+ .flatMap(func));
+ }
+ }
+
+ public static void main(String[] args) {
+ test("Add brackets",
+ s -> Optional.of("[" + s + "]"));
+ test("Increment", s -> {
+ try {
+ return Optional.of(
+ Integer.parseInt(s) + 1 + "");
+ } catch (NumberFormatException e) {
+ return Optional.of(s);
+ }
+ });
+ test("Replace",
+ s -> Optional.of(s.replace("2", "9")));
+ test("Take last digit",
+ s -> Optional.of(s.length() > 0 ?
+ s.charAt(s.length() - 1) + ""
+ : s));
+ }
+}
+```
+同 `map()`,`flatMap()` 将提取非空 **Optional** 的内容并将其应用在映射函数。唯一的区别就是 `flatMap()` 不会把结果包装在 **Optional** 中,因为映射函数已经被包装过了。在如上示例中,我们已经在每一个映射函数中显式地完成了包装,但是很显然 `Optional.flatMap()` 是为那些自己已经生成 **Optional** 的函数而设计的。
+
+### Optional 流
+假设你的生成器可能产生 `null` 值,那么当用它来创建流时,你会想到用 **Optional** 包装元素:
+
+使用这个流时,必须清楚如何解包 **Optional**:
+
+
+输出结果:
+
+由于每种情况都需要定义“空值”的含义,所以通常我们要为每个应用程序采用不同的方法。
+
+## 终端操作
+以下操作将会获取流的最终结果。至此我们无法再继续往后传递流。可以说,终端操作总是我们在流管道中所做的最后一件事。
+
+### 数组
+- `toArray()`:将流转换成适当类型的数组
+- `toArray(generator)`:在特殊情况下,生成自定义类型的数组
+
+假设需复用流产生的随机数:
+
+这样每次调用 `rands()` 的时候可以重复获取相同的整数流。
+
+### 循环
+- `forEach(Consumer)`常见如 `System.out::println` 作为 **Consumer** 函数。
+- `forEachOrdered(Consumer)`: 保证 `forEach` 按照原始流顺序操作。
+
+第一种形式:无序操作,仅在引入并行流时才有意义。 `parallel()`:可实现多处理器并行操作。实现原理为将流分割为多个(通常数目为 CPU 核心数)并在不同处理器上分别执行操作。因为我们采用的是内部迭代,而不是外部迭代,所以这是可能实现的。
+
+下例引入 `parallel()` 来帮助理解 `forEachOrdered(Consumer)` 的作用和使用场景:
+```java
+// streams/ForEach.java
+import java.util.*;
+import java.util.stream.*;
+import static streams.RandInts.*;
+public class ForEach {
+ static final int SZ = 14;
+ public static void main(String[] args) {
+ rands().limit(SZ)
+ .forEach(n -> System.out.format("%d ", n));
+ System.out.println();
+ rands().limit(SZ)
+ .parallel()
+ .forEach(n -> System.out.format("%d ", n));
+ System.out.println();
+ rands().limit(SZ)
+ .parallel()
+ .forEachOrdered(n -> System.out.format("%d ", n));
+ }
+}
+```
+为了方便测试不同大小的数组,我们抽离出了 `SZ` 变量。结果很有趣:在第一个流中,未使用 `parallel()` ,所以 `rands()` 按照元素迭代出现的顺序显示结果;在第二个流中,引入`parallel()` ,即便流很小,输出的结果顺序也和前面不一样。这是由于多处理器并行操作的原因。多次运行测试,结果均不同。多处理器并行操作带来的非确定性因素造成了这样的结果。
+
+在最后一个流中,同时使用了 `parallel()` 和 `forEachOrdered()` 来强制保持原始流顺序。因此,对非并行流使用 `forEachOrdered()` 是没有任何影响的。
+
+### 集合
+- `collect(Collector)`:使用 **Collector** 收集流元素到结果集合中。
+- `collect(Supplier, BiConsumer, BiConsumer)`:同上,第一个参数 **Supplier** 创建了一个新结果集合,第二个参数 **BiConsumer** 将下一个元素包含到结果中,第三个参数 **BiConsumer** 用于将两个值组合起来。
+
+假设我们现在为保证元素有序,将元素存储在 **TreeSet**。**Collectors** 没有特定的 `toTreeSet()`,但可以通过将集合的构造器引用传递给 `Collectors.toCollection()`,从而构建任意类型的集合。
+
+比如,将一个文件中的单词收集到 **TreeSet**:
+
+
+我们也可以在流中生成 **Map**。代码示例:
+
+```java
+// streams/MapCollector.java
+import java.util.*;
+import java.util.stream.*;
+class Pair {
+ public final Character c;
+ public final Integer i;
+ Pair(Character c, Integer i) {
+ this.c = c;
+ this.i = i;
+ }
+ public Character getC() { return c; }
+ public Integer getI() { return i; }
+ @Override
+ public String toString() {
+ return "Pair(" + c + ", " + i + ")";
+ }
+}
+class RandomPair {
+ Random rand = new Random(47);
+ // An infinite iterator of random capital letters:
+ Iterator capChars = rand.ints(65,91)
+ .mapToObj(i -> (char)i)
+ .iterator();
+ public Stream stream() {
+ return rand.ints(100, 1000).distinct()
+ .mapToObj(i -> new Pair(capChars.next(), i));
+ }
+}
+public class MapCollector {
+ public static void main(String[] args) {
+ Map map =
+ new RandomPair().stream()
+ .limit(8)
+ .collect(
+ Collectors.toMap(Pair::getI, Pair::getC));
+ System.out.println(map);
+ }
+}
+```
+
+输出结果:
+
+```
+{688=W, 309=C, 293=B, 761=N, 858=N, 668=G, 622=F, 751=N}
+```
+
+**Pair** 只是一个基础的数据对象。**RandomPair** 创建了随机生成的 **Pair** 对象流。在 Java 中,我们不能直接以某种方式组合两个流。所以这里创建了一个整数流,并且使用 `mapToObj()` 将其转化成为 **Pair** 流。 **capChars** 随机生成的大写字母迭代器从流开始,然后 `iterator()` 允许我们在 `stream()` 中使用它。就我所知,这是组合多个流以生成新的对象流的唯一方法。
+
+在这里,我们只使用最简单形式的 `Collectors.toMap()`,这个方法值需要一个可以从流中获取键值对的函数。还有其他重载形式,其中一种形式是在遇到键值冲突时,需要一个函数来处理这种情况。
+
+大多数情况下,`java.util.stream.Collectors` 中预设的 **Collector** 就能满足我们的要求。
+还可以使用第二种形式的 `collect()`。
+```java
+// streams/SpecialCollector.java
+import java.util.*;
+import java.util.stream.*;
+public class SpecialCollector {
+ public static void main(String[] args) throws Exception {
+ ArrayList words =
+ FileToWords.stream("Cheese.dat")
+ .collect(ArrayList::new,
+ ArrayList::add,
+ ArrayList::addAll);
+ words.stream()
+ .filter(s -> s.equals("cheese"))
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+cheese
+cheese
+```
+
+在这里, **ArrayList** 的方法已经执行了你所需要的操作,但是似乎更有可能的是,如果你必须使用这种形式的 `collect()`,则必须自己创建特殊的定义。
+
+#### 对List根据一个或多个字段分组
+项目中遇到了需要对list进行分组的场景,根据List中entity的某字段或者多个字段进行分组,形成Map,然后根据map进行相关的业务操作。
+##### 根据一个字段进行分组
+```java
+public class ListGroupBy {
+ public static void main(String[] args) {
+ List scoreList = new ArrayList<>();
+ scoreList.add(new Score().setStudentId("001").setScoreYear("2018").setScore(100.0));
+ scoreList.add(new Score().setStudentId("001").setScoreYear("2019").setScore(59.5));
+ scoreList.add(new Score().setStudentId("001").setScoreYear("2019").setScore(99.0));
+ scoreList.add(new Score().setStudentId("002").setScoreYear("2018").setScore(99.6));
+ //根据scoreYear字段进行分组
+ Map> map = scoreList.stream().collect(
+ Collectors.groupingBy(
+ score -> score.getScoreYear()
+ ));
+ System.out.println(JSONUtil.toJsonPrettyStr(map));
+ }
+}
+```
+结果:
+
+```java
+{
+ "2019": [
+ {
+ "studentId": "001",
+ "score": 59.5,
+ "scoreYear": "2019"
+ },
+ {
+ "studentId": "001",
+ "score": 99,
+ "scoreYear": "2019"
+ }
+ ],
+ "2018": [
+ {
+ "studentId": "001",
+ "score": 100,
+ "scoreYear": "2018"
+ },
+ {
+ "studentId": "002",
+ "score": 99.6,
+ "scoreYear": "2018"
+ }
+ ]
+}
+```
+##### 根据多个字段进行分组
+将
+
+```java
+//根据scoreYear字段进行分组
+Map> map = scoreList.stream().collect(
+ Collectors.groupingBy(
+ score -> score.getScoreYear()
+ ));
+```
+ 改为
+
+
+```java
+//根据scoreYear和studentId字段进行分组
+ Map> map = scoreList.stream().collect(
+ Collectors.groupingBy(
+ score -> score.getScoreYear()+'-'+score.getStudentId()
+ ));
+```
+结果:
+
+```java
+{
+ "2019-001": [
+ {
+ "studentId": "001",
+ "score": 59.5,
+ "scoreYear": "2019"
+ },
+ {
+ "studentId": "001",
+ "score": 99,
+ "scoreYear": "2019"
+ }
+ ],
+ "2018-001": [
+ {
+ "studentId": "001",
+ "score": 100,
+ "scoreYear": "2018"
+ }
+ ],
+ "2018-002": [
+ {
+ "studentId": "002",
+ "score": 99.6,
+ "scoreYear": "2018"
+ }
+ ]
+}
+```
+
+
+
+
+
+### 组合
+
+- `reduce(BinaryOperator)`:使用 **BinaryOperator** 来组合所有流中的元素。因为流可能为空,其返回值为 **Optional**。
+- `reduce(identity, BinaryOperator)`:功能同上,但是使用 **identity** 作为其组合的初始值。因此如果流为空,**identity** 就是结果。
+- `reduce(identity, BiFunction, BinaryOperator)`:更复杂的使用形式(暂不介绍),这里把它包含在内,因为它可以提高效率。通常,我们可以显式地组合 `map()` 和 `reduce()` 来更简单的表达它。
+
+下面来看下 `reduce` 的代码示例:
+
+```java
+// streams/Reduce.java
+import java.util.*;
+import java.util.stream.*;
+class Frobnitz {
+ int size;
+ Frobnitz(int sz) { size = sz; }
+ @Override
+ public String toString() {
+ return "Frobnitz(" + size + ")";
+ }
+ // Generator:
+ static Random rand = new Random(47);
+ static final int BOUND = 100;
+ static Frobnitz supply() {
+ return new Frobnitz(rand.nextInt(BOUND));
+ }
+}
+public class Reduce {
+ public static void main(String[] args) {
+ Stream.generate(Frobnitz::supply)
+ .limit(10)
+ .peek(System.out::println)
+ .reduce((fr0, fr1) -> fr0.size < 50 ? fr0 : fr1)
+ .ifPresent(System.out::println);
+ }
+}
+```
+
+输出结果:
+
+```
+Frobnitz(58)
+Frobnitz(55)
+Frobnitz(93)
+Frobnitz(61)
+Frobnitz(61)
+Frobnitz(29)
+Frobnitz(68)
+Frobnitz(0)
+Frobnitz(22)
+Frobnitz(7)
+Frobnitz(29)
+```
+
+**Frobnitz** 包含了一个名为 `supply()` 的生成器;因为这个方法对于 `Supplier` 是签名兼容的,我们可以将其方法引用传递给 `Stream.generate()`(这种签名兼容性被称作结构一致性)。无“初始值”的 `reduce()`方法返回值是 **Optional** 类型。`Optional.ifPresent()` 只有在结果非空的时候才会调用 `Consumer` (`println` 方法可以被调用是因为 **Frobnitz** 可以通过 `toString()` 方法转换成 **String**)。
+
+Lambda 表达式中的第一个参数 `fr0` 是上一次调用 `reduce()` 的结果。而第二个参数 `fr1` 是从流传递过来的值。
+
+`reduce()` 中的 Lambda 表达式使用了三元表达式来获取结果,当其长度小于 50 的时候获取 `fr0` 否则获取序列中的下一个值 `fr1`。当取得第一个长度小于 50 的 `Frobnitz`,只要得到结果就会忽略其他。这是个非常奇怪的约束, 也确实让我们对 `reduce()` 有了更多的了解。
+
+
+### 匹配
+
+- `allMatch(Predicate)` :如果流的每个元素根据提供的 **Predicate** 都返回 true 时,结果返回为 true。在第一个 false 时,则停止执行计算。
+- `anyMatch(Predicate)`:如果流中的任意一个元素根据提供的 **Predicate** 返回 true 时,结果返回为 true。在第一个 false 是停止执行计算。
+- `noneMatch(Predicate)`:如果流的每个元素根据提供的 **Predicate** 都返回 false 时,结果返回为 true。在第一个 true 时停止执行计算。
+
+我们已经在 `Prime.java` 中看到了 `noneMatch()` 的示例;`allMatch()` 和 `anyMatch()` 的用法基本上是等同的。下面我们来探究一下短路行为。为了消除冗余代码,我们创建了 `show()`。首先我们必须知道如何统一地描述这三个匹配器的操作,然后再将其转换为 **Matcher** 接口。代码示例:
+
+```java
+// streams/Matching.java
+// Demonstrates short-circuiting of *Match() operations
+import java.util.stream.*;
+import java.util.function.*;
+import static streams.RandInts.*;
+
+interface Matcher extends BiPredicate, Predicate> {}
+
+public class Matching {
+ static void show(Matcher match, int val) {
+ System.out.println(
+ match.test(
+ IntStream.rangeClosed(1, 9)
+ .boxed()
+ .peek(n -> System.out.format("%d ", n)),
+ n -> n < val));
+ }
+ public static void main(String[] args) {
+ show(Stream::allMatch, 10);
+ show(Stream::allMatch, 4);
+ show(Stream::anyMatch, 2);
+ show(Stream::anyMatch, 0);
+ show(Stream::noneMatch, 5);
+ show(Stream::noneMatch, 0);
+ }
+}
+```
+
+输出结果:
+
+```
+1 2 3 4 5 6 7 8 9 true
+1 2 3 4 false
+1 true
+1 2 3 4 5 6 7 8 9 false
+1 false
+1 2 3 4 5 6 7 8 9 true
+```
+
+**BiPredicate** 是一个二元谓词,它只能接受两个参数且只返回 true 或者 false。它的第一个参数是我们要测试的流,第二个参数是一个谓词 **Predicate**。**Matcher** 适用于所有的 **Stream::\*Match** 方法,所以我们可以传递每一个到 `show()` 中。`match.test()` 的调用会被转换成 **Stream::\*Match** 函数的调用。
+
+`show()` 获取两个参数,**Matcher** 匹配器和用于表示谓词测试 **n < val** 中最大值的 **val**。这个方法生成一个1-9之间的整数流。`peek()` 是用于向我们展示测试在短路之前的情况。从输出中可以看到每次都发生了短路。
+
+### 查找
+
+- `findFirst()`:返回第一个流元素的 **Optional**,如果流为空返回 **Optional.empty**。
+- `findAny(`:返回含有任意流元素的 **Optional**,如果流为空返回 **Optional.empty**。
+
+代码示例:
+
+```java
+// streams/SelectElement.java
+import java.util.*;
+import java.util.stream.*;
+import static streams.RandInts.*;
+public class SelectElement {
+ public static void main(String[] args) {
+ System.out.println(rands().findFirst().getAsInt());
+ System.out.println(
+ rands().parallel().findFirst().getAsInt());
+ System.out.println(rands().findAny().getAsInt());
+ System.out.println(
+ rands().parallel().findAny().getAsInt());
+ }
+}
+```
+
+输出结果:
+
+```
+258
+258
+258
+242
+```
+
+`findFirst()` 无论流是否为并行化的,总是会选择流中的第一个元素。对于非并行流,`findAny()`会选择流中的第一个元素(即使从定义上来看是选择任意元素)。在这个例子中,我们使用 `parallel()` 来并行流从而引入 `findAny()` 选择非第一个流元素的可能性。
+
+如果必须选择流中最后一个元素,那就使用 `reduce()`。代码示例:
+
+```java
+// streams/LastElement.java
+import java.util.*;
+import java.util.stream.*;
+public class LastElement {
+ public static void main(String[] args) {
+ OptionalInt last = IntStream.range(10, 20)
+ .reduce((n1, n2) -> n2);
+ System.out.println(last.orElse(-1));
+ // Non-numeric object:
+ Optional lastobj =
+ Stream.of("one", "two", "three")
+ .reduce((n1, n2) -> n2);
+ System.out.println(
+ lastobj.orElse("Nothing there!"));
+ }
+}
+```
+
+输出结果:
+
+```
+19
+three
+```
+
+`reduce()` 的参数只是用最后一个元素替换了最后两个元素,最终只生成最后一个元素。如果为数字流,你必须使用相近的数字 **Optional** 类型( numeric optional type),否则使用 **Optional** 类型,就像上例中的 `Optional`。
+
+
+
+### 信息
+
+- `count()`:流中的元素个数。
+- `max(Comparator)`:根据所传入的 **Comparator** 所决定的“最大”元素。
+- `min(Comparator)`:根据所传入的 **Comparator** 所决定的“最小”元素。
+
+**String** 类型有预设的 **Comparator** 实现。代码示例:
+
+```java
+// streams/Informational.java
+import java.util.stream.*;
+import java.util.function.*;
+public class Informational {
+ public static void
+ main(String[] args) throws Exception {
+ System.out.println(
+ FileToWords.stream("Cheese.dat").count());
+ System.out.println(
+ FileToWords.stream("Cheese.dat")
+ .min(String.CASE_INSENSITIVE_ORDER)
+ .orElse("NONE"));
+ System.out.println(
+ FileToWords.stream("Cheese.dat")
+ .max(String.CASE_INSENSITIVE_ORDER)
+ .orElse("NONE"));
+ }
+}
+```
+
+输出结果:
+
+```
+32
+a
+you
+```
+
+`min()` 和 `max()` 的返回类型为 **Optional**,这需要我们使用 `orElse()`来解包。
+
+
+### 数字流信息
+
+- `average()` :求取流元素平均值。
+- `max()` 和 `min()`:数值流操作无需 **Comparator**。
+- `sum()`:对所有流元素进行求和。
+- `summaryStatistics()`:生成可能有用的数据。目前并不太清楚这个方法存在的必要性,因为我们其实可以用更直接的方法获得需要的数据。
+
+```java
+// streams/NumericStreamInfo.java
+import java.util.stream.*;
+import static streams.RandInts.*;
+public class NumericStreamInfo {
+ public static void main(String[] args) {
+ System.out.println(rands().average().getAsDouble());
+ System.out.println(rands().max().getAsInt());
+ System.out.println(rands().min().getAsInt());
+ System.out.println(rands().sum());
+ System.out.println(rands().summaryStatistics());
+ }
+}
+```
+
+输出结果:
+
+```
+507.94
+998
+8
+50794
+IntSummaryStatistics{count=100, sum=50794, min=8, average=507.940000, max=998}
+```
+
+上例操作对于 **LongStream** 和 **DoubleStream** 同样适用。
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\346\227\245\346\234\237\346\227\266\351\227\264API.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\346\227\245\346\234\237\346\227\266\351\227\264API.md"
new file mode 100644
index 0000000000..04f7e94b16
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\346\227\245\346\234\237\346\227\266\351\227\264API.md"
@@ -0,0 +1,135 @@
+# 1 背景
+Java8前,处理日期时间时,使用的“三大件”
+- Date
+- Calender
+- SimpleDateFormat
+
+以声明时间戳、使用日历处理日期和格式化解析日期时间。但这些类的API可读性差、使用繁琐,且非线程安全,如同设计的翔一样的IO,也是Java让人诟病的一大原因。
+
+于是Java8推出全新日期时间类。这些类的API功能强大简便、线程安全。
+
+但毕竟Java8刚出这些类,诸如序列化、数据访问等类库都不支持Java8日期时间类,需在新老类中来回切换。比如,在业务逻辑层使用**LocalDateTime**,存入数据库或者返回前端的时候还要切换回**Date**。因此,还不如沿用老的日期时间类。
+
+不过我们生活在最好的时代,基本主流类库都支持新日期时间类型,但还有项目因还是用祖传日期时间类,出现很多古今交错的错误实践。
+比如
+- 通过随意修改时区,使读取到的数据匹配当前时钟
+- 直接对读取到的数据做加、减几个小时的操作,来“修正数据”
+
+本文旨在分析古今时间错乱的本质原因,看看使用遗留日期时间类,来处理日期时间初始化、格式化、解析、计算等可能会遇到的问题,以及如何使用新日期时间类解决。
+
+# 2 初始化日期时间
+- 初始化**2020年11月11日11点11分11秒**时间,这样可行吗?
+
+- 日志输出时间是**3029年12月11日11点11分11秒**:
+```bash
+date : Sat Dec 11 11:11:11 CST 3920
+```
+
+这明显是彩笔才会写的垃圾代码,因为
+- **年应该是和1900差值**
+- **月应该是 0~11 而非 1~12**
+- **时应该是 0~23,而非 1~24**
+
+- 修正上述代码如下:
+```java
+Date date = new Date(2020 - 1900, 10, 11, 11, 11, 11);
+```
+- 日志输出:
+```bash
+Mon Nov 11 11:11:11 CST 2019
+```
+
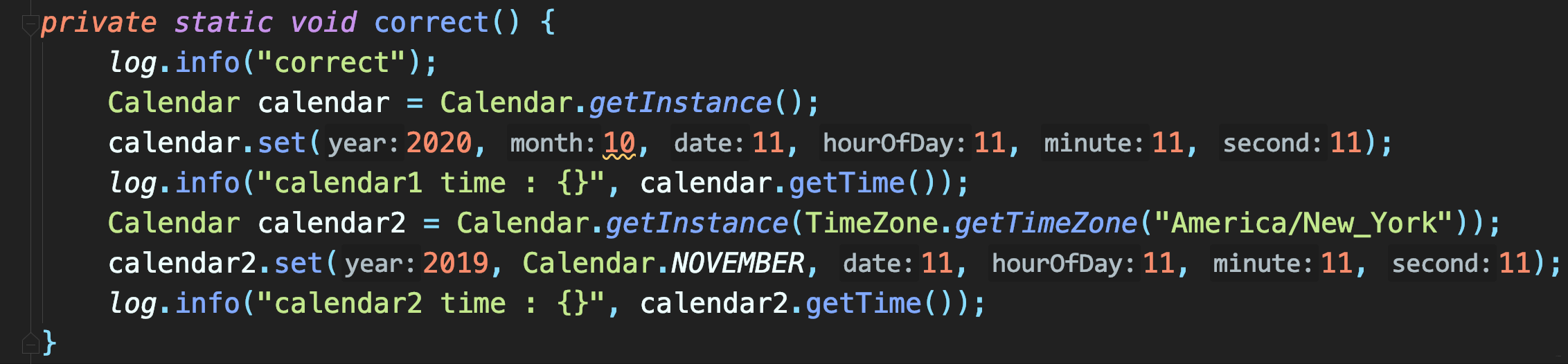
+当有国际化需求时,又得使用**Calendar**类初始化时间。
+
+使用Calendar改造后,初始化时年参数直接使用当前年即可,月**0~11**。亦可直接使用**Calendar.DECEMBER**初始化月份,肯定不会犯错。
+
+- 分别使用当前时区和纽约时区初始化两个相同日期:
+
+- 日志输出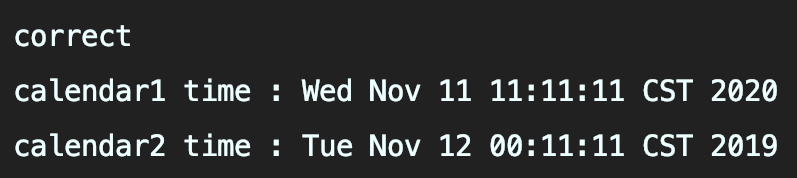
+显示两个不同时间,说明时区发生作用。但更习惯**年/月/日 时:分:秒**日期时间格式,对现在输出的日期格式还不满意,那就格式化日期时间
+
+# 3 时区问题
+全球有24个时区,同一个时刻不同时区(比如中国上海和美国纽约)的时间不同。全球化项目,若初始化时间时未提供时区,那就不是真正意义上的时间,只能认为是我看到的当前时间的一个表示。
+
+## 3.1 Date类
+- Date无时区概念,任一机器使用`new Date()`初始化得到时间相同。因为,Date中保存的是UTC时间,其为以原子钟为基础的统一时间,不以太阳参照计时,无时区划分
+- Date中保存的是一个时间戳,代表从1970年1月1日0点(Epoch时间)到现在的毫秒数。尝试输出Date(0):
+
+```java
+System.out.println(new Date(0));
+System.out.println(TimeZone.getDefault().getID() + ":" +
+ TimeZone.getDefault().getRawOffset()/3600000);
+```
+
+得到1970年1月1日8点。我的机器在中国上海,相比UTC时差+8小时:
+
+```bash
+Thu Jan 01 08:00:00 CST 1970
+Asia/Shanghai:8
+```
+
+对于国际化项目,处理好时间和时区问题首先就是要正确保存日期时间。
+这里有两种
+## 3.2 如何正确保存日期时间
+- 保存UTC
+保存的时间无时区属性,不涉及时区时间差问题的世界统一时间。常说的时间戳或Java中的Date类就是这种方式,也是**推荐方案**
+- 保存字面量
+比如**年/月/日 时:分:秒**,务必同时保存时区信息。有了时区,才能知道该字面量时间真正的时间点,否则它只是一个给人看的时间表示且只在当前时区有意义。
+而**Calendar**才具有时区概念,所以通过使用不同时区初始化**Calendar**,才能得到不同时间。
+
+正确地保存日期时间后,就是**正确展示**,即要使用正确时区,将时间点展示为符合当前时区的时间表示。至此也就能理解为何会发生“时间错乱”。
+
+## 从字面量解析成时间 & 从时间格式化为字面量
+### 对同一时间表示,不同时区转换成Date会得到不同时间戳
+- 比如**2020-11-11 11:11:11**
+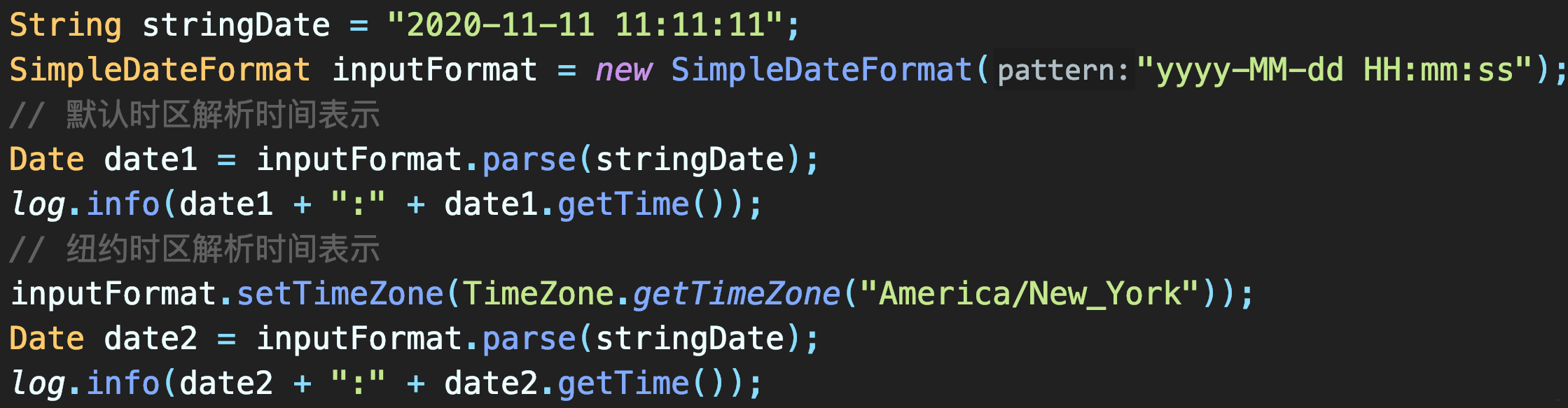
+
+- 对当前上海时区/纽约时区,转化为UTC时间戳不同
+
+```bash
+Wed Nov 11 11:11:11 CST 2020:1605064271000
+Thu Nov 12 00:11:11 CST 2020:1605111071000
+```
+这就是UTC的意义,并非时间错乱。对同一本地时间的表示,不同时区的人解析得到的UTC时间必定不同,反过来不同本地时间可能对应同一UTC。
+
+### 格式化后出现的错乱
+即同一Date,在不同时区下格式化得到不同时间表示。
+
+- 在当前时区和纽约时区格式化**2020-11-11 11:11:11**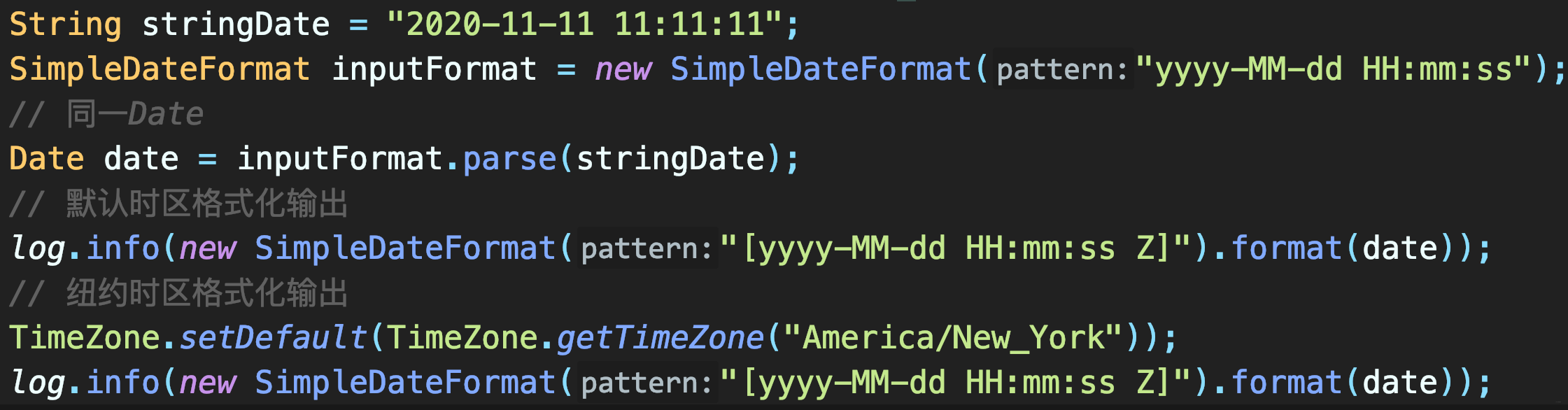
+
+- 输出如下,当前时区Offset(时差)是+8小时,对于-5小时的纽约
+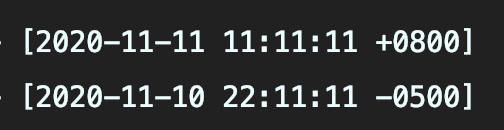
+因此,有时数据库中相同时间,由于服务器时区设置不同,读取到的时间表示不同。这不是时间错乱,而是时区作用,因为`UTC时间需根据当前时区解析为正确的本地时间`。
+
+所以要正确处理时区,在于存和读两阶段
+- 存,需使用正确的当前时区来保存,这样UTC时间才会正确
+- 读,也须正确设置本地时区,才能把UTC时间转换为正确当地时间
+
+# Java8处理时区问题
+时间日期类ZoneId、ZoneOffset、LocalDateTime、ZonedDateTime和DateTimeFormatter,使用起来更简单清晰。
+
+## 初始化上海、纽约和东京三时区
+可使用`ZoneId.of`初始化一个标准时区,也可使用`ZoneOffset.ofHours`通过一个offset初始化一个具有指定时间差的自定义时区。
+
+
+## 日期时间表示
+- `LocalDateTime`无时区属性,所以命名为本地时区的日期时间
+- `ZonedDateTime=LocalDateTime+ZoneId`,带时区属性
+
+因此,`LocalDateTime`仅是一个时间表示,`ZonedDateTime`才是一个有效时间。这里将把2020-01-02 22:00:00这个时间表示,使用东京时区解析得到一个`ZonedDateTime`。
+
+## DateTimeFormatter格式化时间
+可直接通过`withZone`直接设置格式化使用的时区。最后,分别以上海、纽约和东京三个时区来格式化这个时间输出:
+
+
+日志输出:
+- 相同时区,经过解析存和读的时间表示一样(比如最后一行)
+- 不同时区,比如上海/纽约,输出本地时间不同。
+ +9小时时区的晚上10点,对上海时区+8小时,所以上海本地时间为早10点
+ 而纽约时区-5小时,差14小时,为晚上9点
+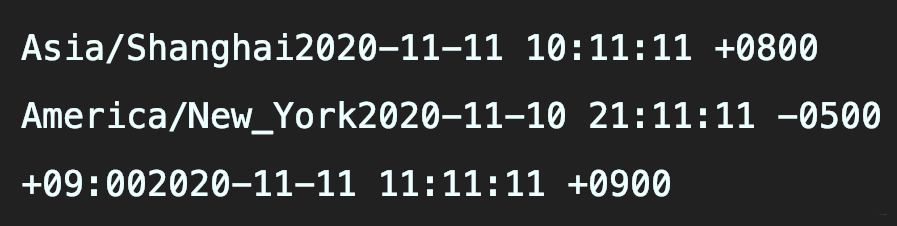
+
+## 小结
+要正确处理国际化时间问题,推荐Java8的日期时间类,即
+1. 使用`ZonedDateTime`保存时间
+2. 然后使用设置了`ZoneId`的`DateTimeFormatter`配合`ZonedDateTime`进行时间格式化得到本地时间表示
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\347\232\204NIO\346\226\260\346\226\207\344\273\266IO\345\210\260\345\272\225\346\234\211\345\244\232\345\245\275\347\224\250\357\274\237.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\347\232\204NIO\346\226\260\346\226\207\344\273\266IO\345\210\260\345\272\225\346\234\211\345\244\232\345\245\275\347\224\250\357\274\237.md"
new file mode 100644
index 0000000000..83bacedc44
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\347\232\204NIO\346\226\260\346\226\207\344\273\266IO\345\210\260\345\272\225\346\234\211\345\244\232\345\245\275\347\224\250\357\274\237.md"
@@ -0,0 +1,161 @@
+>在丑陋的 Java I/O 编程方式诞生多年以后,Java终于简化了文件读写的基本操作。
+
+打开并读取文件对于大多数编程语言来是非常常用的,由于 I/O 糟糕的设计以至于很少有人能够在不依赖其他参考代码的情况下完成打开文件的操作。
+
+在 Java7 中对此引入了巨大的改进。这些新元素被放在 **java.nio.file** 包下面,过去人们通常把 **nio** 中的 **n** 理解为 **new** 即新的 **io**,现在更应该当成是 **non-blocking** 非阻塞 **io**(**io**就是*input/output输入/输出*)。**java.nio.file** 库终于将 Java 文件操作带到与其他编程语言相同的水平。最重要的是 Java8 新增的 streams 与文件结合使得文件操作编程变得更加优雅。
+看一下文件操作的两个基本组件:
+
+1. 文件或者目录的路径;
+2. 文件本身。
+
+# 文件和目录路径
+一个 **Path** 对象表示一个文件或者目录的路径,是一个跨操作系统(OS)和文件系统的抽象,目的是在构造路径时不必关注底层操作系统,代码可以在不进行修改的情况下运行在不同的操作系统上。**java.nio.file.Paths** 类包含一个重载方法 **static get()**,该方法接受一系列 **String** 字符串或一个*统一资源标识符*(URI)作为参数,并且进行转换返回一个 **Path** 对象。
+
+当 **toString()** 方法生成完整形式的路径, **getFileName()** 方法总是返回当前文件名。
+通过使用 **Files** 工具类,可以测试一个文件是否存在,测试是否是一个"普通"文件还是一个目录等等。"Nofile.txt"这个示例展示我们描述的文件可能并不在指定的位置;这样可以允许你创建一个新的路径。"PathInfo.java"存在于当前目录中,最初它只是没有路径的文件名,但它仍然被检测为"存在"。一旦我们将其转换为绝对路径,我们将会得到一个从"C:"盘(因为我们是在Windows机器下进行测试)开始的完整路径,现在它也拥有一个父路径。
+“真实”路径的定义在文档中有点模糊,因为它取决于具体的文件系统。例如,如果文件名不区分大小写,即使路径由于大小写的缘故而不是完全相同,也可能得到肯定的匹配结果。在这样的平台上,**toRealPath()** 将返回实际情况下的 **Path**,并且还会删除任何冗余元素。
+
+这里你会看到 **URI** 看起来只能用于描述文件,实际上 **URI** 可以用于描述更多的东西;通过 [维基百科](https://en.wikipedia.org/wiki/Uniform_Resource_Identifier) 可以了解更多细节。现在我们成功地将 **URI** 转为一个 **Path** 对象。
+
+**Path** 中看到一些有点欺骗的东西,这就是调用 **toFile()** 方法会生成一个 **File** 对象。听起来似乎可以得到一个类似文件的东西(毕竟被称为 **File** ),但是这个方法的存在仅仅是为了向后兼容。虽然看上去应该被称为"路径",实际上却应该表示目录或者文件本身。这是个非常草率并且令人困惑的命名,但是由于 **java.nio.file** 的存在我们可以安全地忽略它的存在。
+
+## 选取路径部分片段
+**Path** 对象可以非常容易地生成路径的某一部分:
+
+
+可以通过 **getName()** 来索引 **Path** 的各个部分,直到达到上限 **getNameCount()**。**Path** 也实现了 **Iterable** 接口,因此我们也可以通过增强的 for-each 进行遍历。请注意,即使路径以 **.java** 结尾,使用 **endsWith()** 方法也会返回 **false**。这是因为使用 **endsWith()** 比较的是整个路径部分,而不会包含文件路径的后缀。通过使用 **startsWith()** 和 **endsWith()** 也可以完成路径的遍历。但是我们可以看到,遍历 **Path** 对象并不包含根路径,只有使用 **startsWith()** 检测根路径时才会返回 **true**。
+
+## 路径分析
+**Files** 工具类包含一系列完整的方法用于获得 **Path** 相关的信息。
+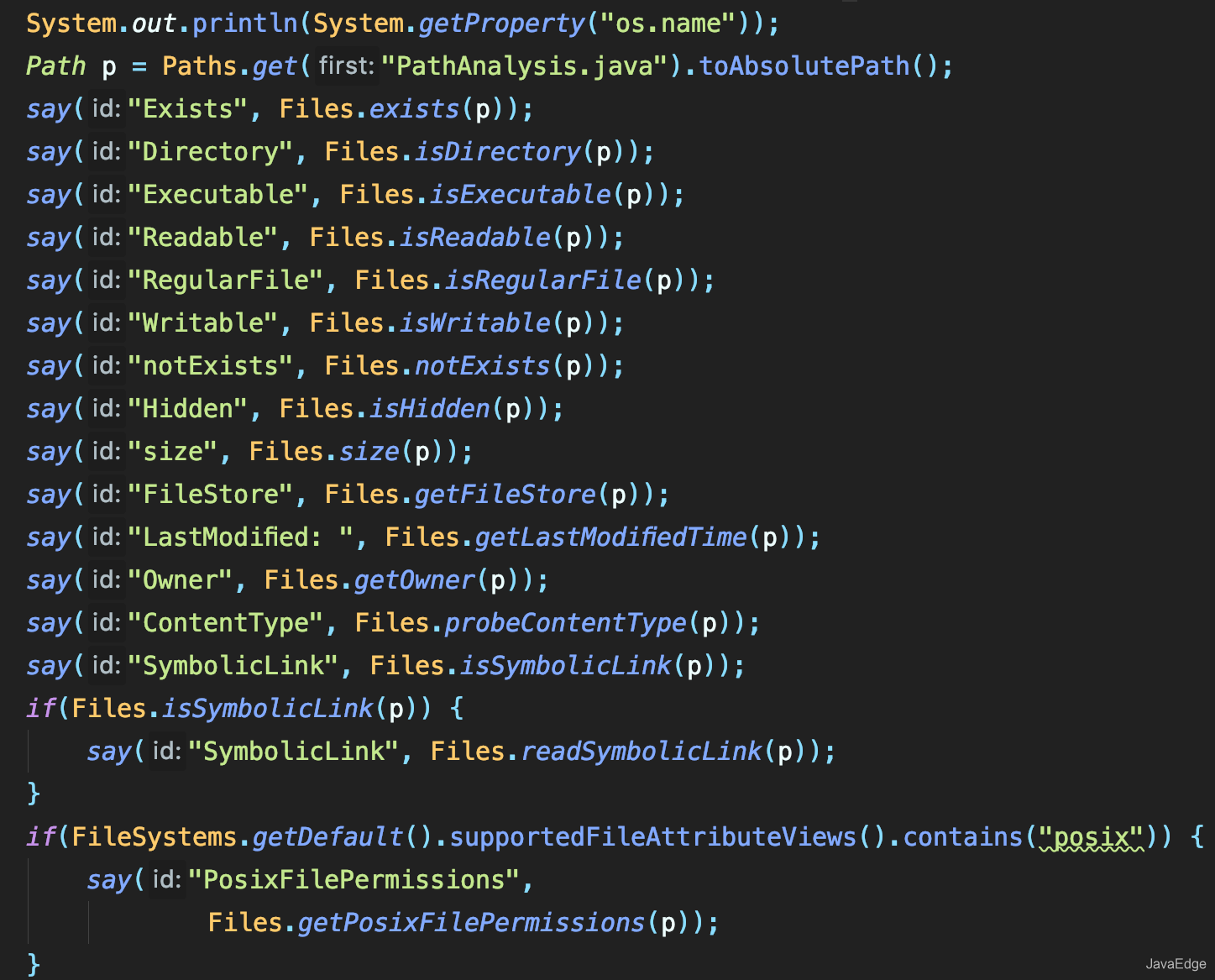
+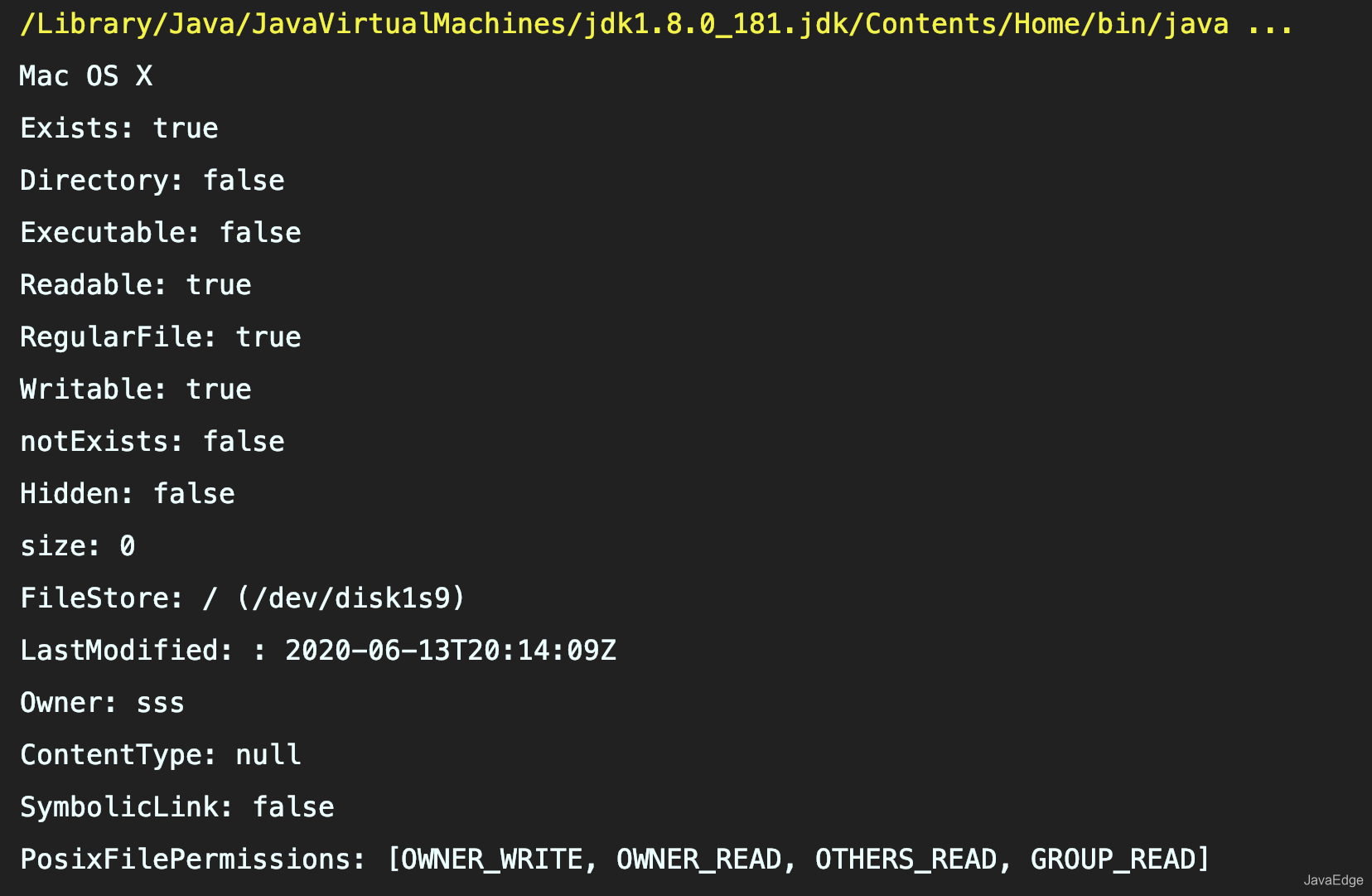
+在调用最后一个测试方法 **getPosixFilePermissions()** 之前我们需要确认一下当前文件系统是否支持 **Posix** 接口,否则会抛出运行时异常。
+
+## **Paths**的增减修改
+我们必须能通过对 **Path** 对象增加或者删除一部分来构造一个新的 **Path** 对象。我们使用 **relativize()** 移除 **Path** 的根路径,使用 **resolve()** 添加 **Path** 的尾路径(不一定是“可发现”的名称)。
+
+对于下面代码中的示例,我使用 **relativize()** 方法从所有的输出中移除根路径,部分原因是为了示范,部分原因是为了简化输出结果,这说明你可以使用该方法将绝对路径转为相对路径。
+这个版本的代码中包含 **id**,以便于跟踪输出结果:
+
+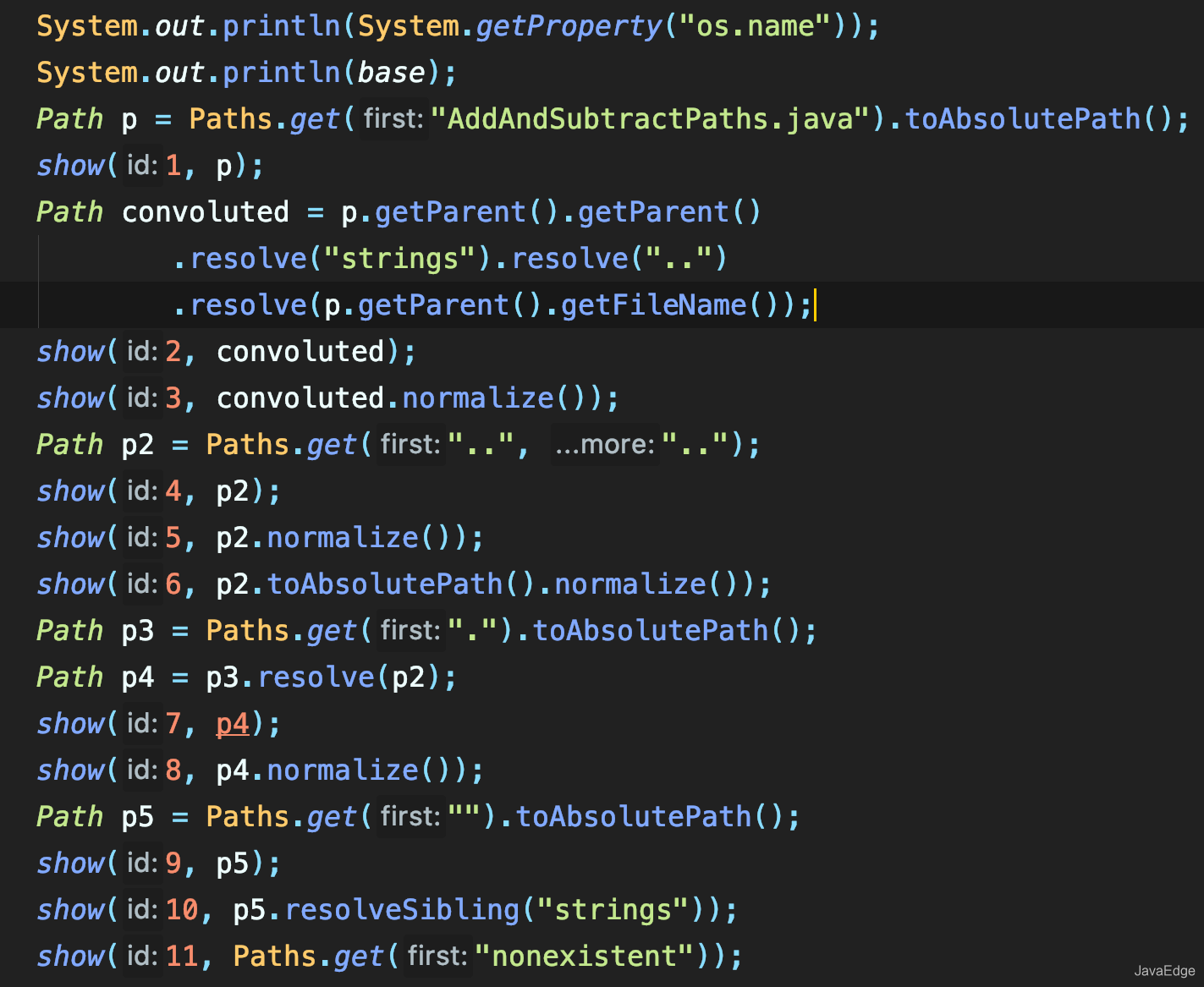
+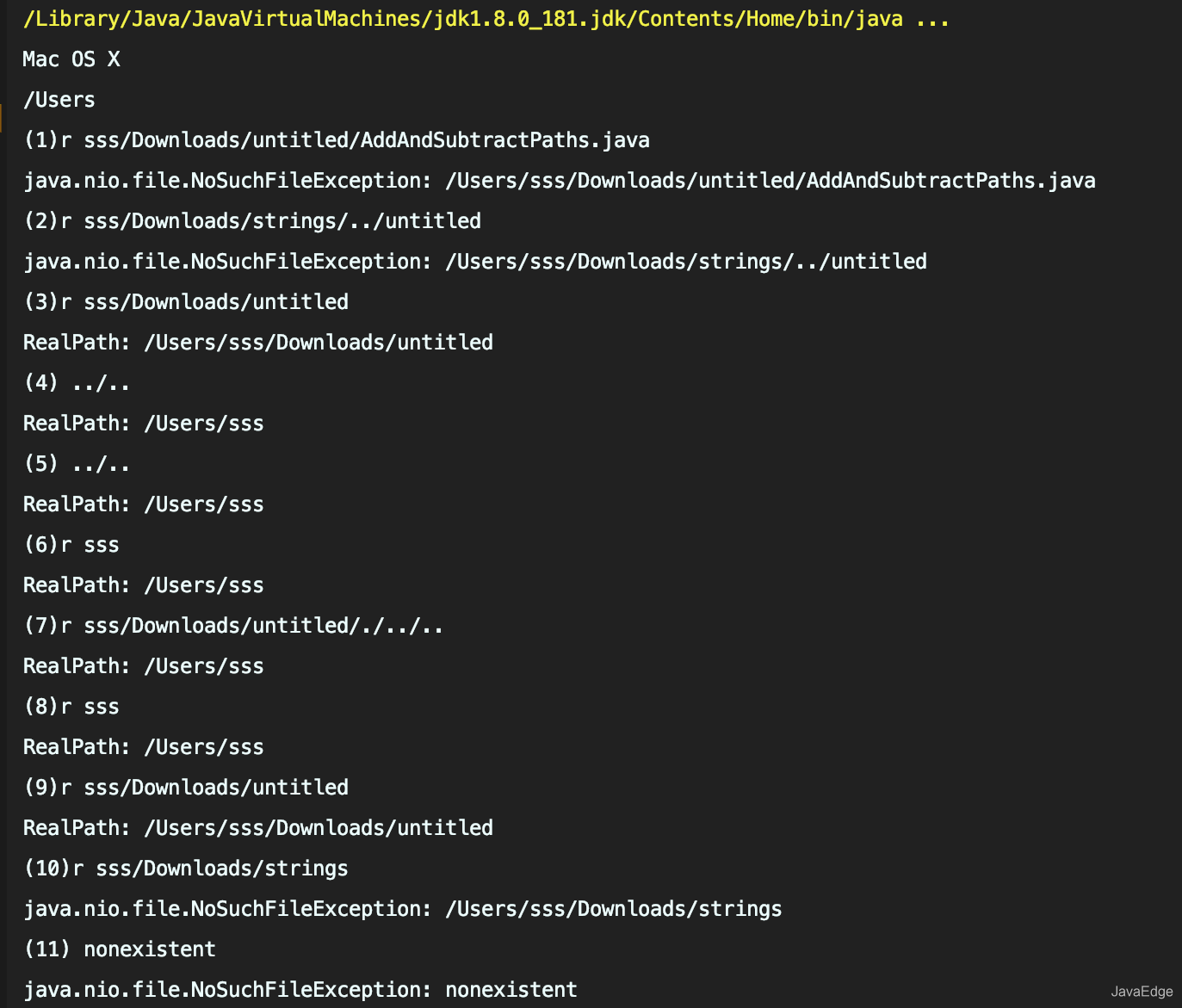
+
+# 目录
+**Files** 工具类包含大部分我们需要的目录操作和文件操作方法。出于某种原因,它们没有包含删除目录树相关的方法
+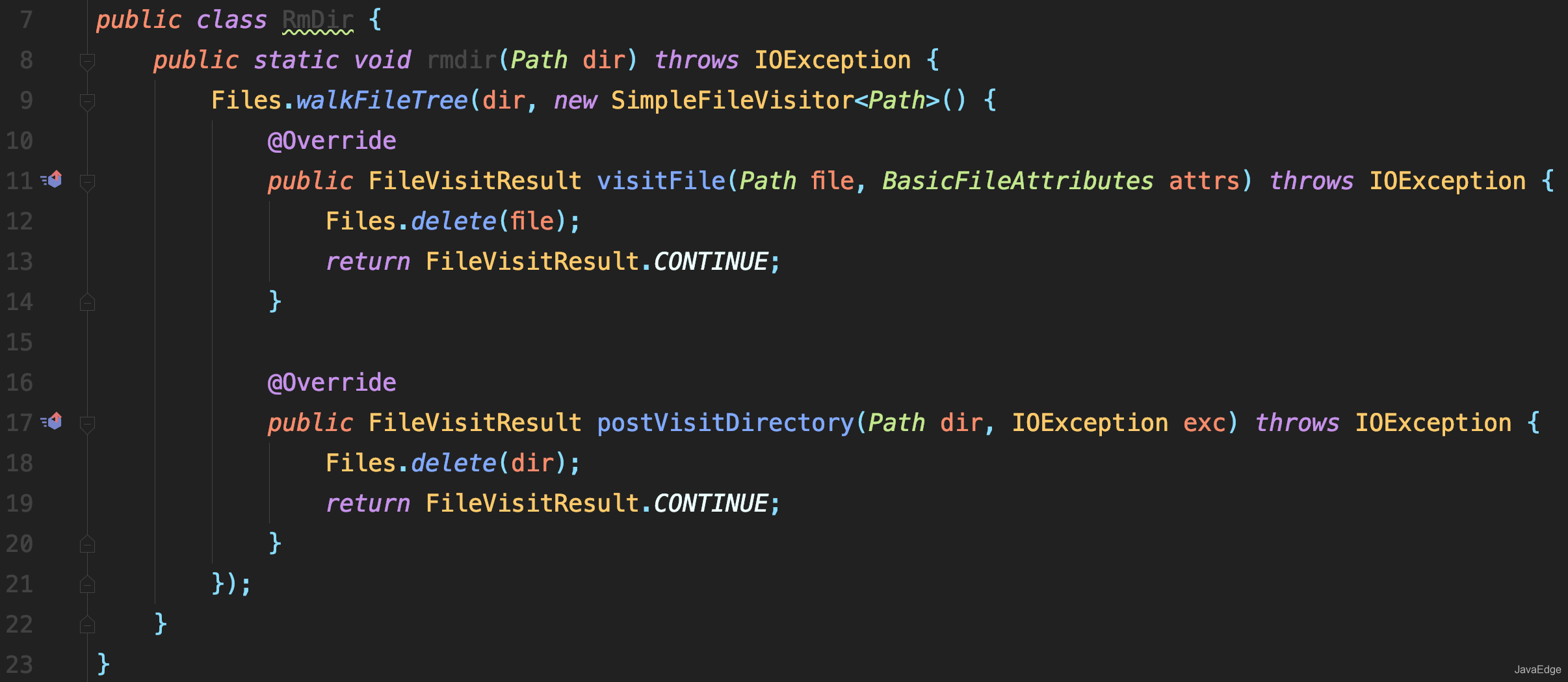
+删除目录树的方法实现依赖于 **Files.walkFileTree()**,"walking" 目录树意味着遍历每个子目录和文件。*Visitor* 设计模式提供了一种标准机制来访问集合中的每个对象,然后你需要提供在每个对象上执行的操作。
+此操作的定义取决于实现的 **FileVisitor** 的四个抽象方法,包括:
+
+- **preVisitDirectory()**
+在访问目录中条目之前在目录上运行。
+- **visitFile()**:调用目录中的文件
+
+
+- **visitFileFailed()**
+ 调用无法被访问的文件。如果该文件的属性不能被读取,该文件是无法打开一个目录,以及其他原因,该方法被调用。
+- **postVisitDirectory()**
+在访问目录中条目之后在目录上运行,包括所有的子目录。
+
+为了简化,**java.nio.file.SimpleFileVisitor** 提供了所有方法的默认实现
+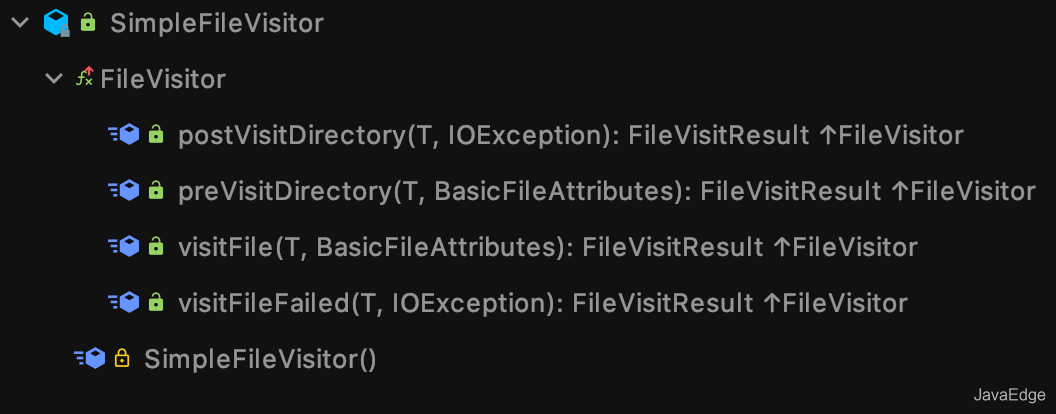
+
+在自己的匿名内部类中,只需要重写非标准行为的方法:**visitFile()** 和 **postVisitDirectory()** 实现删除文件和删除目录。两者都应该返回标志位决定是否继续访问
+作为探索目录操作的一部分,现在我们可以有条件地删除已存在的目录。在以下例子中,**makeVariant()** 接受基本目录测试,并通过旋转部件列表生成不同的子目录路径。这些旋转与路径分隔符 **sep** 使用 **String.join()** 贴在一起,然后返回一个 **Path** 对象。
+
+如果你对于已经存在的目录调用 **createDirectory()** 将会抛出异常。**createFile()** 使用参数 **Path** 创建一个空文件; **resolve()** 将文件名添加到 **test Path** 的末尾。
+
+我们尝试使用 **createDirectory()** 来创建多级路径,但是这样会抛出异常,因为这个方法只能创建单级路径。我已经将 **populateTestDir()** 作为一个单独的方法,因为它将在后面的例子中被重用。对于每一个变量 **variant**,我们都能使用 **createDirectories()** 创建完整的目录路径,然后使用此文件的副本以不同的目标名称填充该终端目录。然后我们使用 **createTempFile()** 生成一个临时文件。
+
+在调用 **populateTestDir()** 之后,我们在 **test** 目录下面下面创建一个临时目录。请注意,**createTempDirectory()** 只有名称的前缀选项。与 **createTempFile()** 不同,我们再次使用它将临时文件放入新的临时目录中。你可以从输出中看到,如果未指定后缀,它将默认使用".tmp"作为后缀。
+
+为了展示结果,我们首次使用看起来很有希望的 **newDirectoryStream()**,但事实证明这个方法只是返回 **test** 目录内容的 Stream 流,并没有更多的内容。要获取目录树的全部内容的流,请使用 **Files.walk()**。
+
+
+
+## 文件系统
+为了完整起见,我们需要一种方法查找文件系统相关的其他信息。在这里,我们使用静态的 **FileSystems** 工具类获取"默认"的文件系统,但也可以在 **Path** 对象上调用 **getFileSystem()** 以获取创建该 **Path** 的文件系统。
+可以获得给定 *URI* 的文件系统,还可以构建新的文件系统(对于支持它的操作系统)。
+
+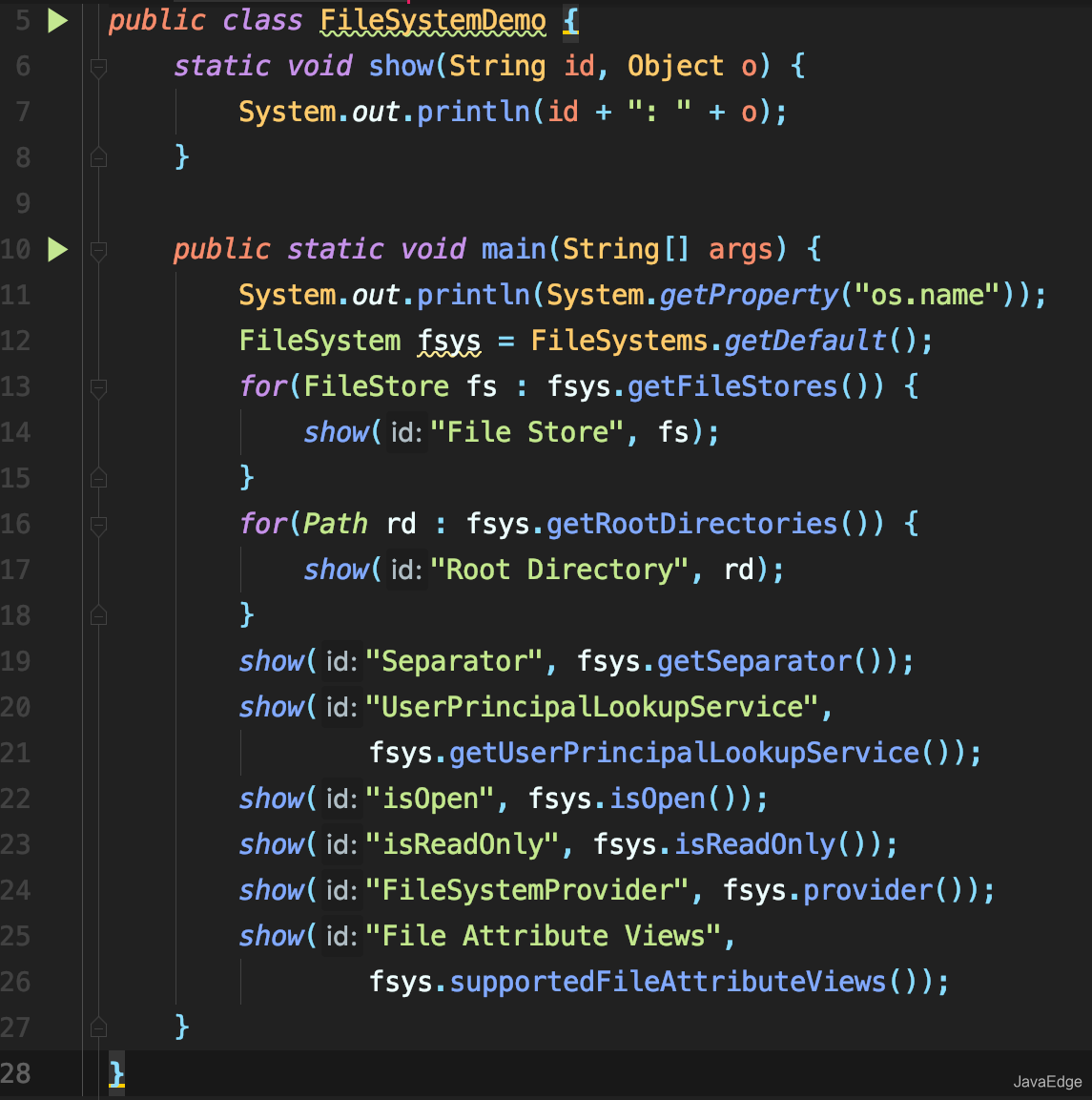
+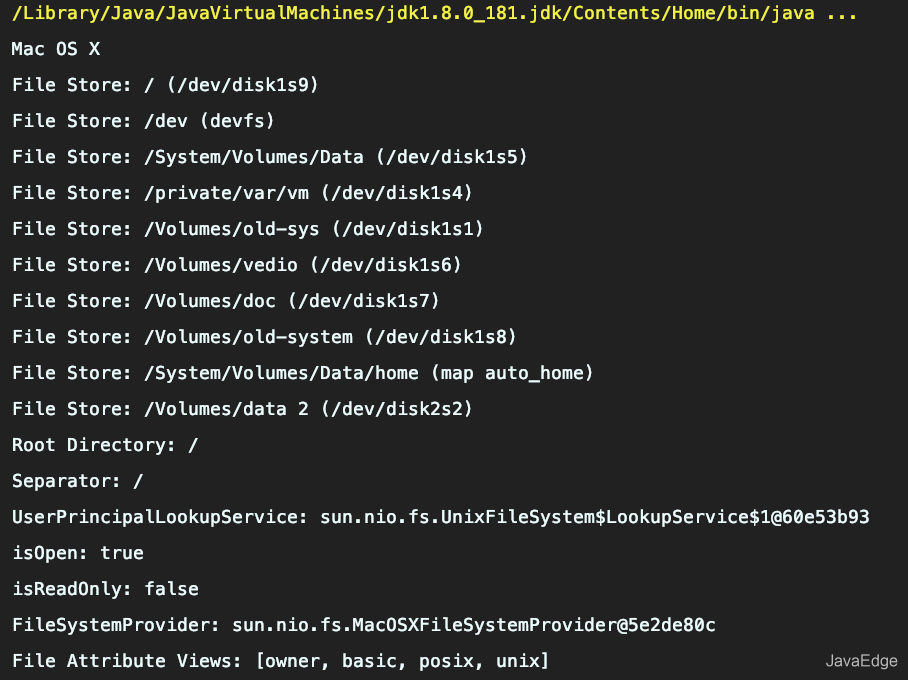
+
+
+
+# 路径监听
+通过 **WatchService** 可以设置一个进程对目录中的更改做出响应。
+
+一旦我们从 **FileSystem** 中得到了 **WatchService** 对象,我们将其注册到 **test** 路径以及我们感兴趣的项目的变量参数列表中,可以选择
+**ENTRY_CREATE**
+
+**ENTRY_DELETE**
+
+**ENTRY_MODIFY**(其中创建和删除不属于修改)。
+
+
+接下来对 **watcher.take()** 的调用会在发生某些事情之前停止所有操作,所以我们希望 **deltxtfiles()** 能够并行运行以便生成我们感兴趣的事件。为了实现这个目的,通过调用 **Executors.newSingleThreadScheduledExecutor()** 产生一个 **ScheduledExecutorService** 对象,然后调用 **schedule()** 方法传递所需函数的方法引用,并且设置在运行之前应该等待的时间。
+
+此时,**watcher.take()** 将等待并阻塞在这里。当目标事件发生时,会返回一个包含 **WatchEvent** 的 **Watchkey** 对象。
+
+
+如果说"监视这个目录",自然会包含整个目录和下面子目录,但实际上的:只会监视给定的目录,而不是下面的所有内容。如果需要监视整个树目录,必须在整个树的每个子目录上放置一个 **Watchservice**。
+
+# 文件查找
+粗糙的方法,在 `path` 上调用 `toString()`,然后使用 `string` 操作查看结果。
+
+`java.nio.file` 有更好的解决方案:通过在 `FileSystem` 对象上调用 `getPathMatcher()` 获得一个 `PathMatcher`,然后传入感兴趣的模式。
+
+## 模式
+### `glob`
+`glob` 比较简单,实际上功能非常强大,因此可以使用 `glob` 解决许多问题。
+
+
+在 `matcher` 中,`glob` 表达式开头的 `**/` 表示“当前目录及所有子目录”,这在当你不仅仅要匹配当前目录下特定结尾的 `Path` 时非常有用。
+单 `*` 表示“任何东西”,然后是一个点,然后大括号表示一系列的可能性---我们正在寻找以 `.tmp` 或 `.txt` 结尾的东西
+
+
+### `regex`
+如果问题更复杂,可以使用 `regex`
+
+# 文件读写
+如果一个文件很“小”,即“它运行得足够快且占用内存小”,那 `java.nio.file.Files` 类中的实用程序将帮助你轻松读写文本和二进制文件。
+
+- `Files.readAllLines()` 一次读取整个文件(因此,“小”文件很有必要),产生一个`List`
+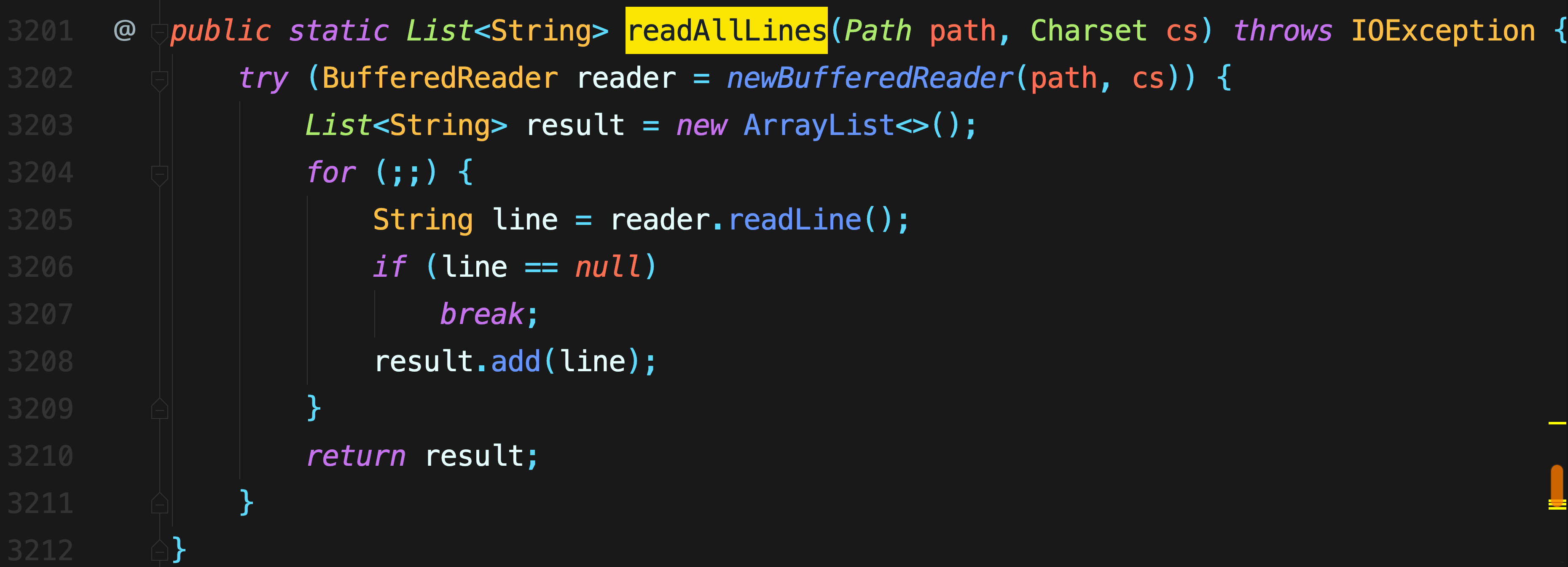
+- 只需将 `Path` 传递给 `readAllLines()` 
+
+- `readAllLines()` 有一个重载版本,包含一个 `Charset` 参数来存储文件的 Unicode 编码
+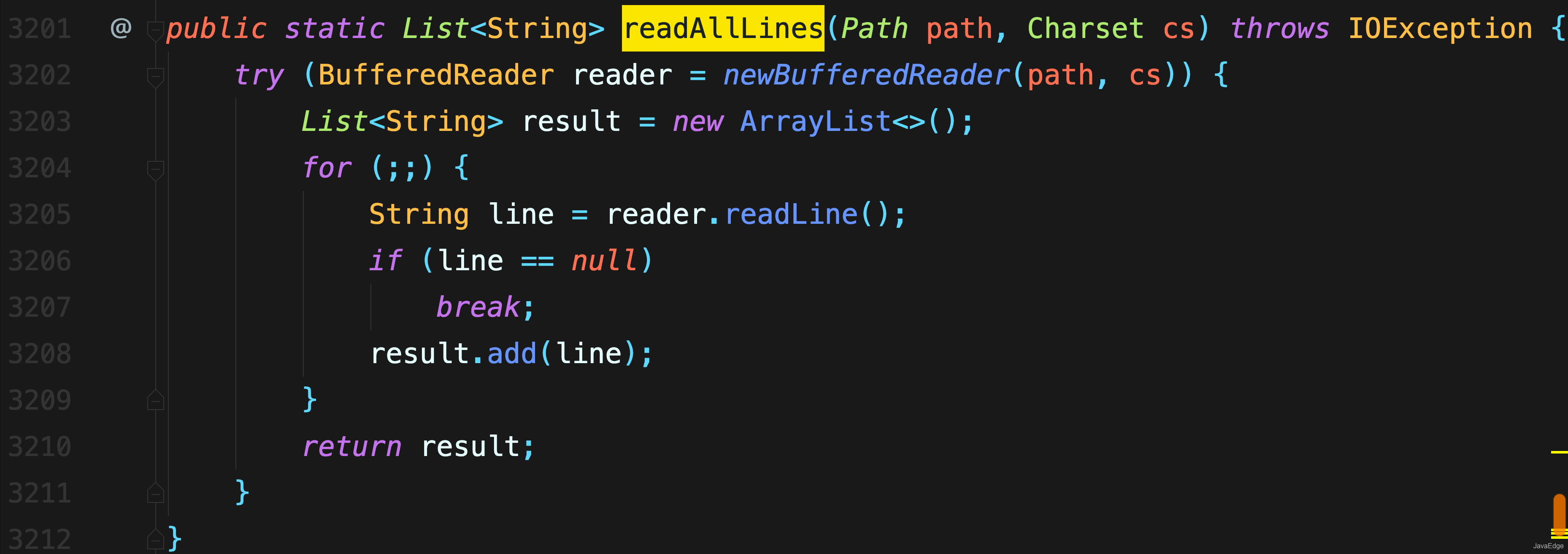
+
+- `Files.write()` 被重载以写入 `byte` 数组或任何 `Iterable` 对象(它也有 `Charset` 选项):
+
+
+```java
+ClassReader cr = new ClassReader("com/javaedge/asm/TestAsm");
+ClassWriter cw = new ClassWriter(ClassWriter.COMPUTE_MAXS);
+ClassVisitor cv = new MyClassVisitor(cw);
+cr.accept(cv, ClassReader.SKIP_DEBUG);
+
+byte[] data = cw.toByteArray();
+Files.write(Paths.get("src/main/java/com/javaedge/asm/out.class"), data);
+System.out.println("generate success!");
+```
+
+如果文件大小有问题怎么办? 比如说:
+
+1. 文件太大,如果你一次性读完整个文件,你可能会耗尽内存。
+
+2. 您只需要在文件的中途工作以获得所需的结果,因此读取整个文件会浪费时间。
+
+`Files.lines()` 方便地将文件转换为行的 `Stream`:
+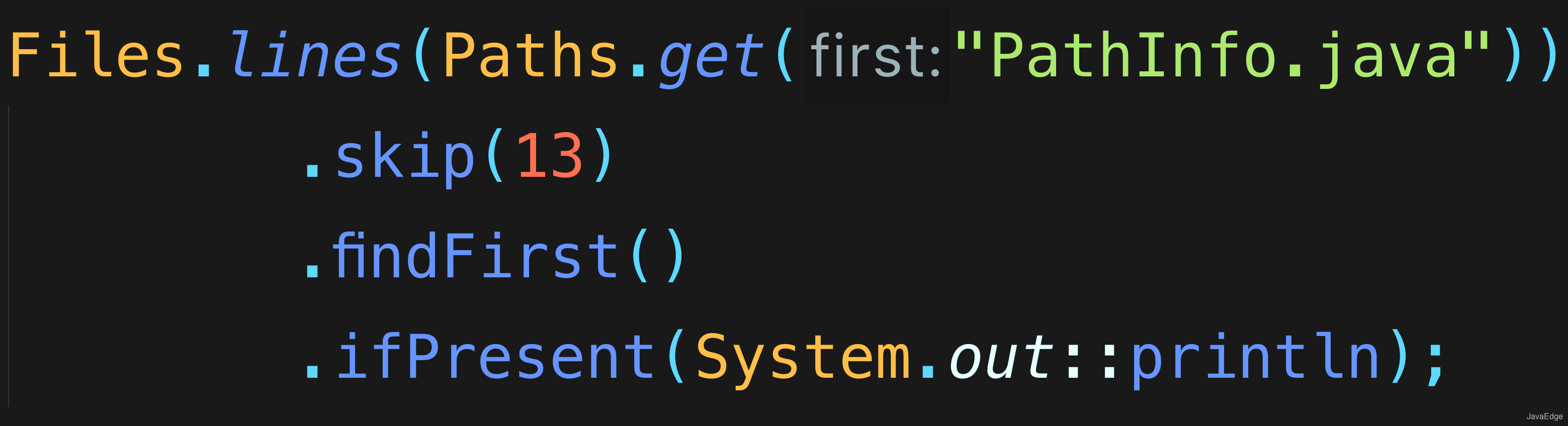
+流式处理,跳过 13 行,然后选择下一行并将其打印出来。
+
+`Files.lines()` 对于把文件处理行的传入流时非常有用,但是如果你想在 `Stream` 中读取,处理或写入怎么办?这就需要稍微复杂的代码:
+
+因为我们在同一个块中执行所有操作,所以这两个文件都可以在相同的 try-with-resources 语句中打开。
+`PrintWriter` 是一个旧式的 `java.io` 类,允许你“打印”到一个文件,所以它是这个应用的理想选择
+
+# 总结
+虽然本章对文件和目录操作做了相当全面的介绍,但是仍然有没被介绍的类库中的功能——一定要研究 `java.nio.file` 的 Javadocs,尤其是 `java.nio.file.Files` 这个类。
+
+Java 7 和 8 对于处理文件和目录的类库做了大量改进。如果您刚刚开始使用 Java,那么您很幸运。在过去,它令人非常不愉快,Java 设计者以前对于文件操作不够重视才没做简化。对于初学者来说这是一件很棒的事,对于教学者来说也一样。我不明白为什么花了这么长时间来解决这个明显的问题,但不管怎么说它被解决了,我很高兴。使用文件现在很简单,甚至很有趣,这是你以前永远想不到的。
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\347\232\204\346\226\260\346\227\245\346\234\237API.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\347\232\204\346\226\260\346\227\245\346\234\237API.md"
new file mode 100644
index 0000000000..ac8029e012
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\347\232\204\346\226\260\346\227\245\346\234\237API.md"
@@ -0,0 +1,212 @@
+# 1 为什么需要新的日期和时间库?
+Java开发人员的一个长期烦恼是对普通开发人员的日期和时间用例的支持不足。
+
+例如,现有的类(例如java.util.Date和SimpleDateFormatter)是非线程安全的,从而导致用户潜在的并发问题,这不是一般开发人员在编写日期处理代码时会期望处理的问题。
+一些日期和时间类还表现出相当差的API设计。例如,年份java.util.Date从1900开始,月份从1开始,天从0开始,这不是很直观。
+
+这些问题以及其他一些问题导致第三方日期和时间库(例如Joda-Time)的欣欣向荣。
+
+为了解决这些问题并在JDK内核中提供更好的支持,针对Java SE 8设计了一个新的没有这些问题的日期和时间API。该项目由Joda-Time(Stephen Colebourne)和Oracle的作者在JSR 310下共同领导,出现在Java SE 8软件包中java.time。
+
+
+# 2 核心思想
+
+## 不可变值类
+Java现有格式化程序的严重缺陷之一是它们不是线程安全的。这给开发人员带来了负担,使其需要以线程安全的方式使用它们并在其日常处理日期处理代码的过程中考虑并发问题。新的API通过确保其所有核心类都是不可变的并表示定义明确的值来避免此问题。
+
+## 域驱动
+新的API模型与代表不同的用例类域非常精确Date和Time严密。这与以前的Java库不同,后者在这方面很差。例如,java.util.Date在时间轴上表示一个时刻(一个自UNIX纪元以来的毫秒数的包装器),但如果调用toString(),结果表明它具有时区,从而引起开发人员之间的困惑。
+
+这种对域驱动设计的重视在清晰度和易理解性方面提供了长期利益,但是当从以前的API移植到Java SE 8时,您可能需要考虑应用程序的域日期模型。
+
+## 按时间顺序分隔
+新的API使人们可以使用不同的日历系统来满足世界某些地区(例如日本或泰国)用户的需求,而这些用户不一定遵循ISO-8601。这样做不会给大多数开发人员带来额外负担,他们只需要使用标准的时间顺序即可。
+
+
+# 3 LocalDate、LocalTime、LocalDateTime
+## 3.1 相比 Date 的优势
+- Date 和 SimpleDateFormatter 非线程安全,而 LocalDate 和 LocalTime 和 String 一样,是final类型 - 线程安全且不能被修改。
+- Date 月份从0开始,一月是0,十二月是11。LocalDate 月份和星期都改成了 enum ,不会再用错。
+- Date是一个“万能接口”,它包含日期、时间,还有毫秒数。如果你只需要日期或时间那么有一些数据就没啥用。在新的Java 8中,日期和时间被明确划分为 LocalDate 和 LocalTime,LocalDate无法包含时间,LocalTime无法包含日期。当然,LocalDateTime才能同时包含日期和时间。
+- Date 推算时间(比如往前推几天/ 往后推几天/ 计算某年是否闰年/ 推算某年某月的第一天、最后一天、第一个星期一等等)要结合Calendar要写好多代码,十分恶心!
+
+两个都是本地的,因为它们从观察者的角度表示日期和时间,例如桌子上的日历或墙上的时钟。
+
+还有一种称为复合类`LocalDateTime`,这是一个LocalDate和LocalTime的配对。
+
+
+时区将不同观察者的上下文区分开来,在这里放在一边;不需要上下文时,应使用这些本地类。这些类甚至可以用于表示具有一致时区的分布式系统上的时间。
+
+
+## 常用 API
+### now()
+获取在默认的时区系统时钟内的当前日期。该方法将查询默认时区内的系统时钟,以获取当前日期。
+使用该方法将防止使用测试用的备用时钟,因为时钟是硬编码的。
+
+
+方便的加减年月日,而不必亲自计算!
+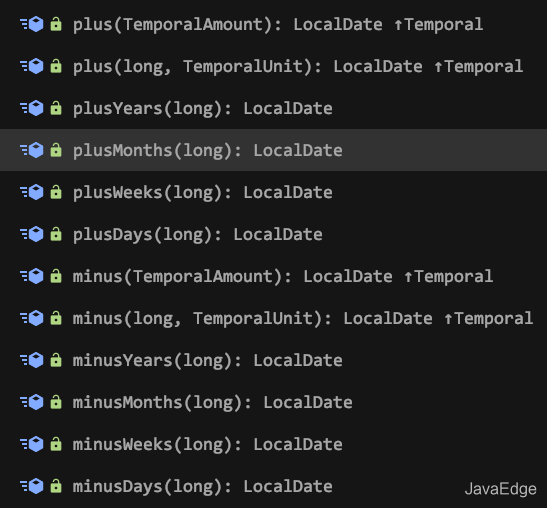
+
+### plusMonths
+返回此副本LocalDate添加了几个月的指定数目。
+此方法将分三步指定金额的几个月字段:
+- 将输入的月数加到month-of-year字段
+- 校验结果日期是否无效
+- 调整 day-of-month ,如果有必要的最后有效日期
+
+例如,2007-03-31加一个月会导致无效日期2007年4月31日。并非返回一个无效结果,而是 2007-04-30才是最后有效日期。调用实例的不可变性不会被该方法影响。
+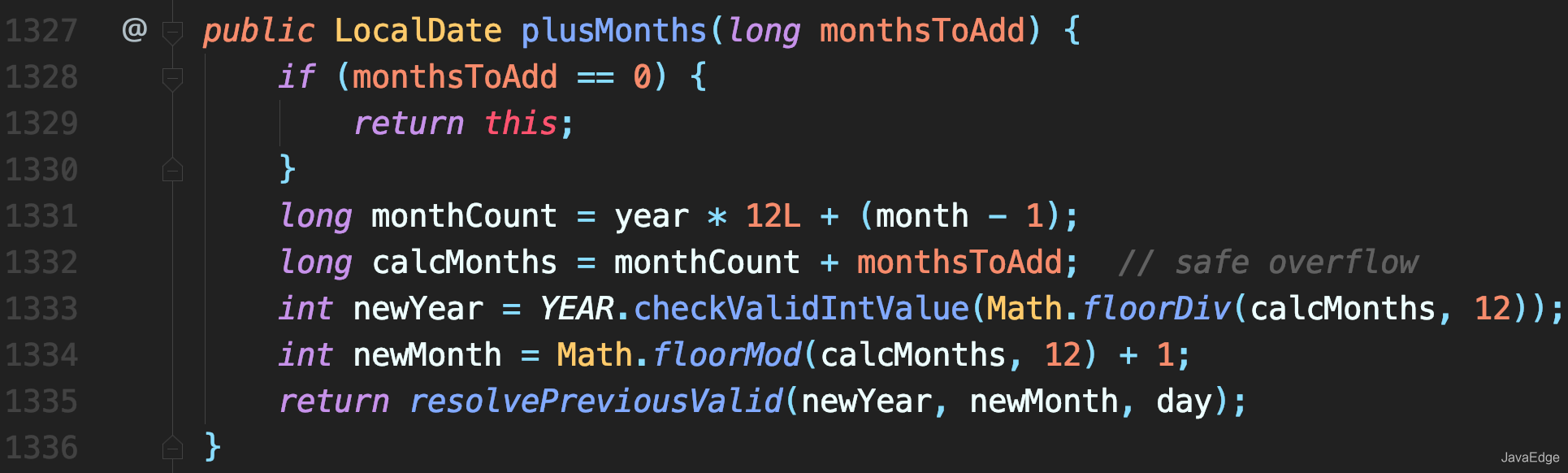
+
+# 4 创建对象
+## 工厂方法
+新API中的所有核心类都是通过熟练的工厂方法构造。
+- 当通过其构成域构造值时,称为工厂of
+- 从其他类型转换时,工厂称为from
+- 也有将字符串作为参数的解析方法。
+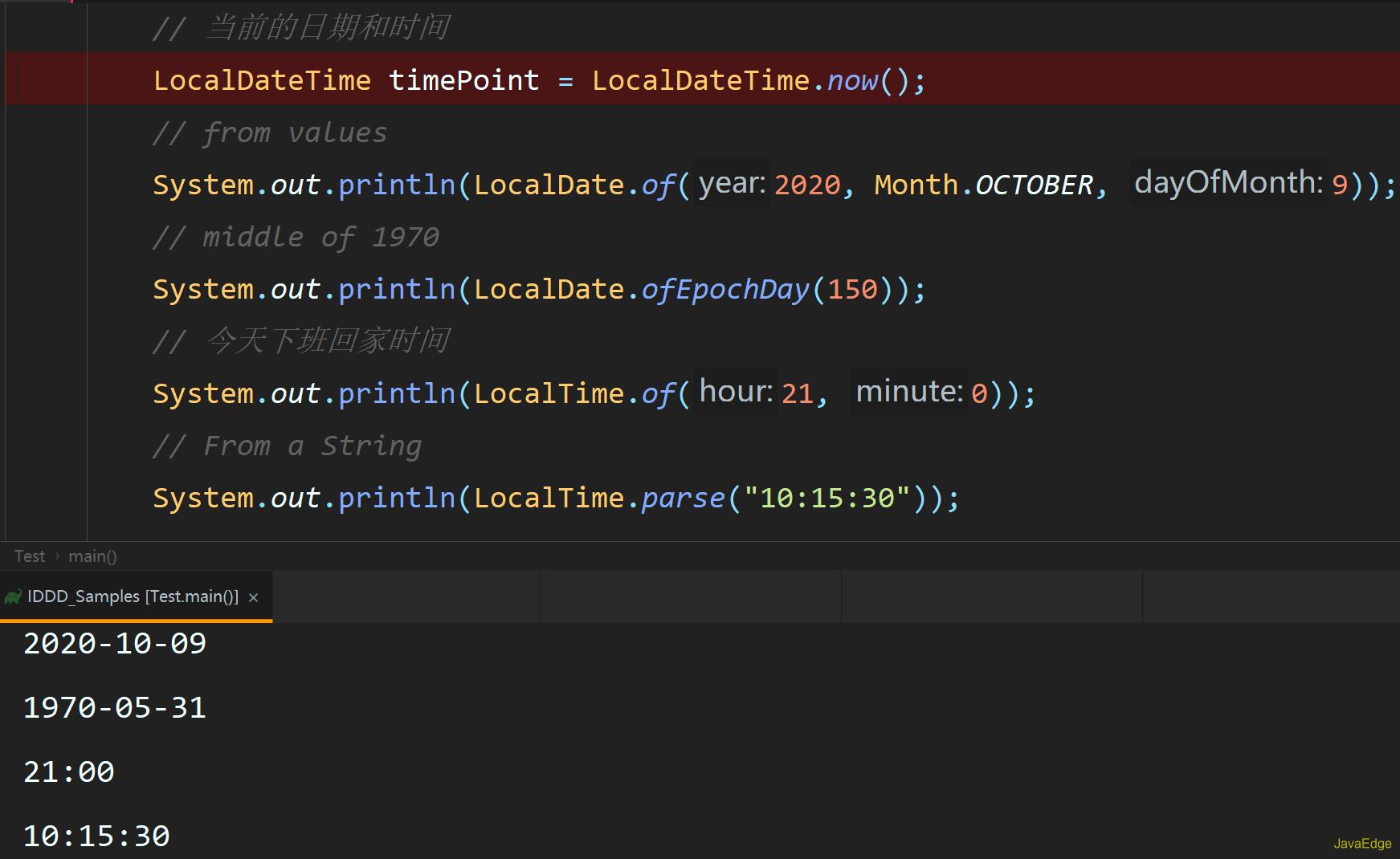
+## getter约定
+- 为了从Java SE 8类获取值,使用了标准的Java getter约定,如下:
+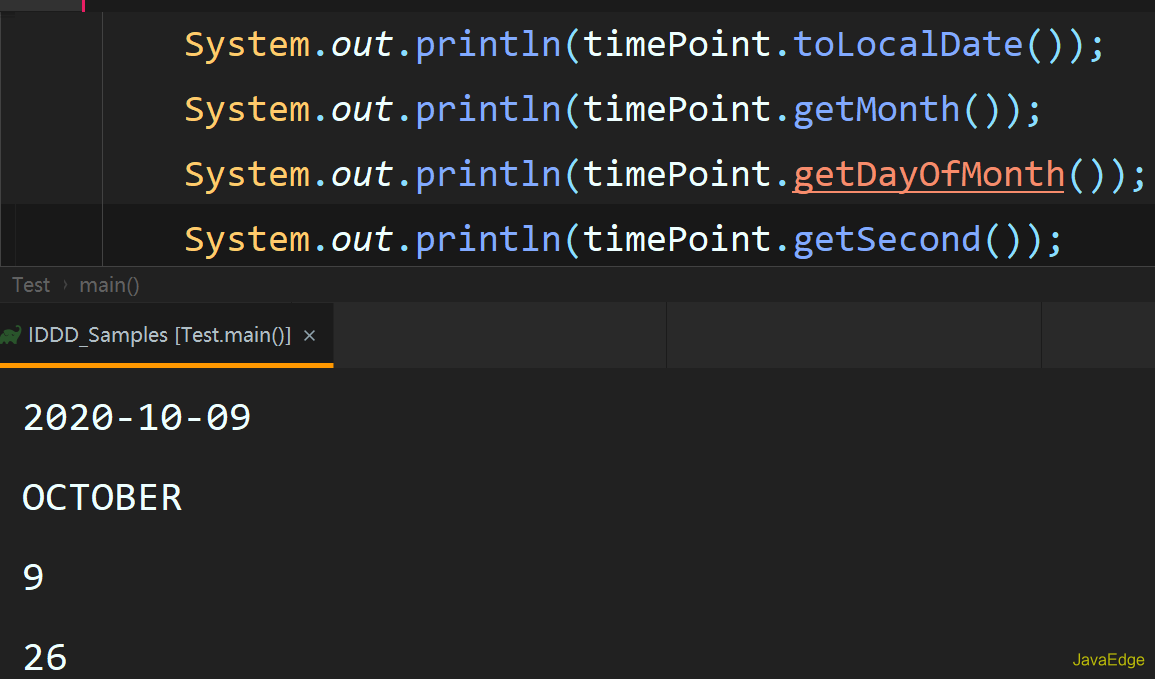
+## 更改对象值
+也可以更改对象值以执行计算。因为新API中所有核心类都是不可变的,所以将调用这些方法with并返回新对象,而不是使用setter。也有基于不同字段的计算方法。
+
+## 调整器
+新的API还具有调整器的概念—一块代码块,可用于包装通用处理逻辑。可以编写一个WithAdjuster,用于设置一个或多个字段,也可编写一个PlusAdjuster用于添加或减去某些字段。值类还可以充当调节器,在这种情况下,它们将更新它们表示的字段的值。内置调节器由新的API定义,但是如果您有想要重用的特定业务逻辑,则可以编写自己的调节器。
+
+```java
+import static java.time.temporal.TemporalAdjusters.*;
+
+LocalDateTime timePoint = ...
+foo = timePoint.with(lastDayOfMonth());
+bar = timePoint.with(previousOrSame(ChronoUnit.WEDNESDAY));
+
+// 使用值类作为调整器
+timePoint.with(LocalTime.now());
+```
+
+# 5 截断
+新的API通过提供表示日期,时间和带时间的日期的类型来支持不同的精确度时间点,但是显然,精确度的概念比此精确度更高。
+
+该truncatedTo方法存在支持这种使用情况下,它可以让你的值截断到字段,如下
+
+```java
+LocalTime truncatedTime = time.truncatedTo(ChronoUnit.SECONDS);
+```
+
+# 6 时区
+我们之前查看的本地类抽象了时区引入的复杂性。时区是一组规则,对应于标准时间相同的区域。大约有40个。时区由它们相对于协调世界时(UTC,Coordinated Universal Time)的偏移量定义。它们大致同步移动,但有一定差异。
+
+时区可用两个标识符来表示:缩写,例如“ PLT”,更长的例如“ Asia / Karachi”。在设计应用程序时,应考虑哪种情况适合使用时区,什么时候需要偏移量。
+
+- `ZoneId`是区域的标识符。每个ZoneId规则都对应一些规则,这些规则定义了该位置的时区。在设计软件时,如果考虑使用诸如“ PLT”或“ Asia / Karachi”之类的字符串,则应改用该域类。一个示例用例是存储用户对其时区的偏好。
+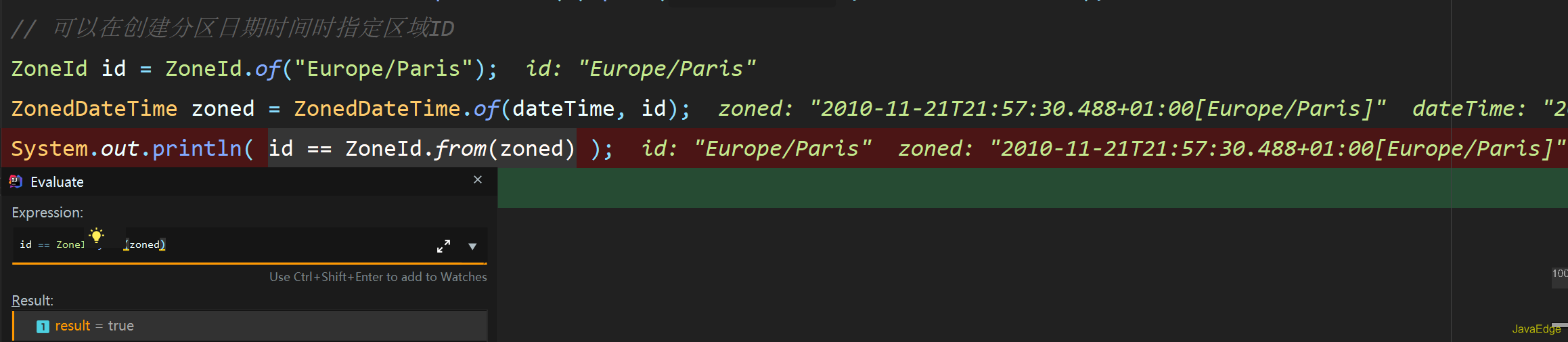
+
+- `ZoneOffset`是格林威治/ UTC与时区之间的差异的时间段。可在特定的`ZoneId`,在特定时间被解析,如清单7所示。
+
+```java
+ZoneOffset offset = ZoneOffset.of("+2:00");
+```
+
+# 7 时区类
+`ZonedDateTime`是具有完全限定时区的日期和时间。这样可以解决任何时间点的偏移。
+最佳实践:若要表示日期和时间而不依赖特定服务器的上下文,则应使用`ZonedDateTime`。
+
+```java
+ZonedDateTime.parse("2007-12-03T10:15:30+01:00[Europe/Paris]");
+```
+
+`OffsetDateTime`是具有已解决偏移量的日期和时间。这对于将数据序列化到数据库中很有用,如果服务器在不同时区,则还应该用作记录时间戳的序列化格式。
+
+`OffsetTime` 是具有确定的偏移量的时间,如下:
+
+
+```java
+OffsetTime time = OffsetTime.now();
+// changes offset, while keeping the same point on the timeline
+OffsetTime sameTimeDifferentOffset = time.withOffsetSameInstant(
+ offset);
+// changes the offset, and updates the point on the timeline
+OffsetTime changeTimeWithNewOffset = time.withOffsetSameLocal(
+ offset);
+// Can also create new object with altered fields as before
+changeTimeWithNewOffset
+ .withHour(3)
+ .plusSeconds(2);
+OffsetTime time = OffsetTime.now();
+// changes offset, while keeping the same point on the timeline
+OffsetTime sameTimeDifferentOffset = time.withOffsetSameInstant(
+ offset);
+// changes the offset, and updates the point on the timeline
+OffsetTime changeTimeWithNewOffset = time.withOffsetSameLocal(
+ offset);
+// Can also create new object with altered fields as before
+changeTimeWithNewOffset
+ .withHour(3)
+ .plusSeconds(2);
+```
+
+Java中已有一个时区类,java.util.TimeZone但Java SE 8并没有使用它,因为所有JSR 310类都是不可变的并且时区是可变的。
+
+# 8 时间段(period)
+Period代表诸如“ 3个月零一天”的值,它是时间线上的距离。这与到目前为止我们讨论过的其他类形成了鲜明的对比,它们是时间轴上的重点。
+
+```java
+// 3 年, 2 月, 1 天
+Period period = Period.of(3, 2, 1);
+
+// 使用 period 修改日期值
+LocalDate newDate = oldDate.plus(period);
+ZonedDateTime newDateTime = oldDateTime.minus(period);
+// Components of a Period are represented by ChronoUnit values
+assertEquals(1, period.get(ChronoUnit.DAYS));
+// 3 years, 2 months, 1 day
+Period period = Period.of(3, 2, 1);
+
+// You can modify the values of dates using periods
+LocalDate newDate = oldDate.plus(period);
+ZonedDateTime newDateTime = oldDateTime.minus(period);
+// Components of a Period are represented by ChronoUnit values
+assertEquals(1, period.get(ChronoUnit.DAYS));
+```
+
+# 9 持续时间(Duration)
+Duration是时间线上按时间度量的距离,它实现了与相似的目的Period,但精度不同:
+
+```java
+// 3 s 和 5 ns 的 Duration
+Duration duration = Duration.ofSeconds(3, 5);
+Duration oneDay = Duration.between(today, yesterday);
+// A duration of 3 seconds and 5 nanoseconds
+Duration duration = Duration.ofSeconds(3, 5);
+Duration oneDay = Duration.between(today, yesterday);
+```
+
+可以对Duration实例执行常规的加,减和“ with”运算,还可以使用修改日期或时间的值Duration。
+
+# 10 年表
+为了满足使用非ISO日历系统的开发人员的需求,Java SE 8引入了Chronology,代表日历系统,并充当日历系统中时间点的工厂。也有一些接口对应于核心时间点类,但通过
+
+
+```java
+Chronology:
+ChronoLocalDate
+ChronoLocalDateTime
+ChronoZonedDateTime
+Chronology:
+ChronoLocalDate
+ChronoLocalDateTime
+ChronoZonedDateTime
+```
+
+这些类仅适用于正在开发高度国际化的应用程序且需要考虑本地日历系统的开发人员,没有这些要求的开发人员不应使用它们。有些日历系统甚至没有一个月或一周的概念,因此需要通过非常通用的字段API进行计算。
+
+# 11 其余的API
+Java SE 8还具有一些其他常见用例的类。有一个MonthDay类,其中包含一对Month和Day,对于表示生日非常有用。该YearMonth类涵盖了信用卡开始日期和到期日期的用例以及人们没有指定日期的场景。
+
+Java SE 8中的JDBC将支持这些新类型,但不会更改公共JDBC API。现有的泛型setObject和getObject方法就足够了。
+
+这些类型可以映射到特定于供应商的数据库类型或ANSI SQL类型。
+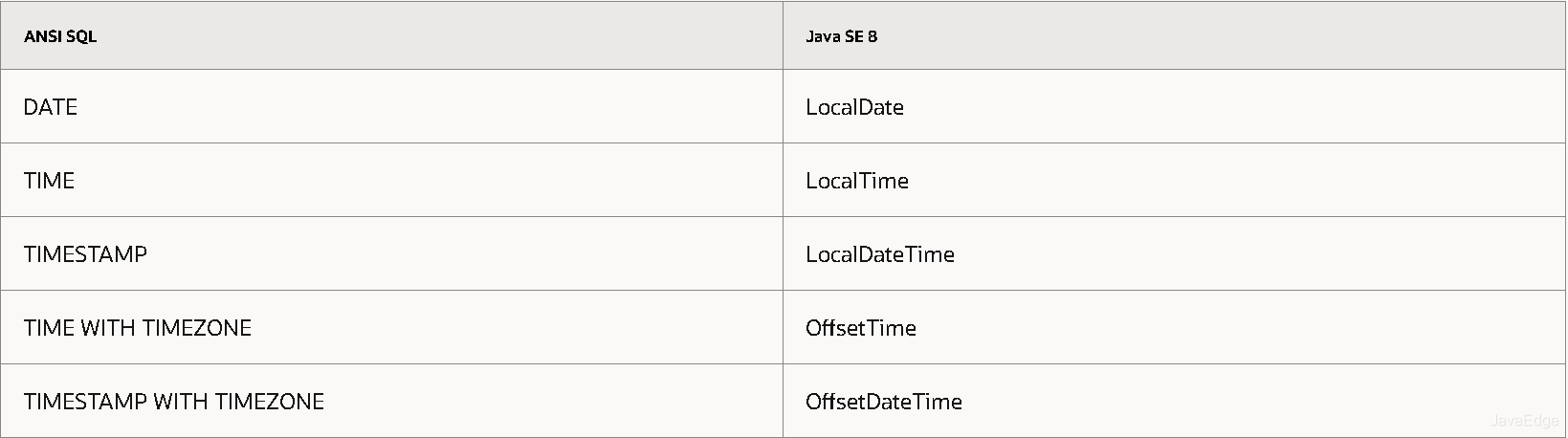
+# 12 总结
+
+Java SE 8在java.time中附带一个新的日期和时间API,为开发人员提供了大大改善的安全性和功能。新的API很好地建模了该领域,并提供了用于对各种开发人员用例进行建模的大量类。
\ No newline at end of file
diff --git "a/Java/Java8\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220-Hashtable\346\272\220\347\240\201\345\211\226\346\236\220.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220-Hashtable\346\272\220\347\240\201\345\211\226\346\236\220.md"
similarity index 99%
rename from "Java/Java8\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220-Hashtable\346\272\220\347\240\201\345\211\226\346\236\220.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220-Hashtable\346\272\220\347\240\201\345\211\226\346\236\220.md"
index 47eb49416a..a4a829979c 100644
--- "a/Java/Java8\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220-Hashtable\346\272\220\347\240\201\345\211\226\346\236\220.md"
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java8\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220-Hashtable\346\272\220\347\240\201\345\211\226\346\236\220.md"
@@ -16,7 +16,7 @@ NOTE: This class is obsolete. New implementations should
```
这个类的方法如下(全是抽象方法):
-```
+```java
public abstract
class Dictionary {
@@ -33,7 +33,7 @@ class Dictionary {
```
##成员变量
-```
+```java
//存储键值对的桶数组
private transient Entry[] table;
@@ -52,7 +52,7 @@ class Dictionary {
成员变量跟HashMap基本类似,但是HashMap更加规范,HashMap内部还定义了一些常量,比如默认的负载因子,默认的容量,最大容量等等。
##构造方法
-```
+```java
//可指定初始容量和加载因子
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
diff --git "a/Java/Java\344\270\216\347\272\277\347\250\213.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\216\347\272\277\347\250\213.md"
similarity index 56%
rename from "Java/Java\344\270\216\347\272\277\347\250\213.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\216\347\272\277\347\250\213.md"
index eb873095d4..44310f6ea2 100644
--- "a/Java/Java\344\270\216\347\272\277\347\250\213.md"
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\216\347\272\277\347\250\213.md"
@@ -1,16 +1,16 @@
-并发不一定要依赖多线程(如PHP的多进程并发),但在Java中谈论并发,大多数都与线程脱不开关系
+并发不一定要依赖多线程(如PHP的多进程并发),但在Java中谈论并发,大多数都与线程脱不开关系。
# 线程的实现
线程是CPU调度的基本单位。
Thread类与大部分的Java API有显著的差别,它的所有关键方法都是声明为Native的。
意味着这个方法没有使用或无法使用平台无关的手段来实现。
-# 内核线程(Kernel-Lever Thread,KLT)
+# 内核线程(Kernel-Level Thread,KLT)
直接由操作系统内核(Kermel,下称内核)支持的线程
由内核来完成线程切换,内核通过操纵调度器(Sheduler) 对线程进行调度,并负责将线程的任务映射到各个处理器上。
每个内核线程可以视为内核的一个分身,这样OS就有能力同时处理多件事情,支持多线程的内核就叫做多线程内核(Multi-Threads Kernel )。
-程序一般不会直接去使用KLT,而使用KLT的一种高级接口即轻量级进程(Light Weight Process,LWP),即我们通常意义上所讲的线程,由于每个LWP都由一个KLT支持,因此只有先支持KLT,才能有LWP。这1:1的关系称为`一对一的线程模型`。
-
+程序一般不会直接去使用KLT,而使用KLT的一种高级接口即轻量级进程(Light Weight Process,LWP),即我们通常意义上所讲的线程,由于每个LWP都由一个KLT支持,因此只有先支持KLT,才能有LWP。这1:1的关系称为`一对一的线程模型`。
+
- 局限性
由于是基于KLT实现的,所以各种线程操作,如创建、析构及同步,都需要进行系统调用。而系统调用的代价相对较高,需要在用户态和内核态中来回切换
其次,每个LWP都需要有一个KLT的支持,因此LWP要消耗一定的内核资源(如KLT的栈空间),因此一个系统支持LWP的数量是有限的
@@ -19,23 +19,26 @@ Thread类与大部分的Java API有显著的差别,它的所有关键方法都
# 用户线程混合轻量级进程
# Java线程的实现
-用户线程还是完全建立在用户空间中,因此用户线程的创建、切换、析构等操作依然廉价,并
-且可以支持大规模的用户线程并发
-操作系统提供支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核提供的线程调度功能及处理器映射,并且用户线程的系统调用要通过轻量级线程来完成,大大降低了整个进程被完全阻塞的风险。
+用户线程还是完全建立在用户空间中,因此用户线程的创建、切换、析构等操作依然廉价,并且可以支持大规模的用户线程并发。
+
+os提供支持的轻量级进程则作为用户线程和内核线程之间的桥梁,这样可以使用内核提供的线程调度功能及处理器映射,并且用户线程的系统调用要通过轻量级线程来完成,大大降低了整个进程被完全阻塞的风险。
在这种混合模式中,用户线程与轻量级进程的数量比是不定的,即为N :M 的关系
-
-许多UN1X 系列的操作系统,如Solaris、HP-UX 等都提供了N: M 的线程模型实现。
-#.Java 线程
+
+许多Unix 系列的os,如Solaris、HP-UX 等都提供了N: M 的线程模型实现。
+# Java 线程
JDK 1.2 之前是基于称为“绿色线程”(Green-Threads )的用户线程实现
在JDK 1.2 中替换为基于操作系统原生线程模型来实现
因此,在目前的JDK 版本中,操作系统支持怎样的线程模型,在很大程度上决定了Java 虚拟机的线程是怎样映射的,这点在不同的平台上没有办法达成一致,虚拟机规范中也并未限定Java 线程需要使用哪种线程模型来实现。
线程模型只对线程的并发规模和操作成本产生影响,对Java 程序的编码和运行过程来说,这些差异都是透明的。
-对于Siun JDK 来说,它的Windows 版与Linux版都是使用一对一的线程模型实现的,一条Java线程就映射到一条轻量级进程之中,因为Windows 和Linux系统提供的线程模型就是一对一的
+对于Sun JDK 来说,它的Windows 版与Linux版都是使用一对一的线程模型实现的,一条Java线程就映射到一条轻量级进程之中,因为Windows 和Linux系统提供的线程模型就是一对一的。
而在Solaris 平台中,由于操作系统的线程特性可以同时支持一对一(通过Bound
-Threaids或Alternate Libthread实现)及多对多( 通过LWP/Thread Based Synchronization
-实现) 的线程模型,因此在Solaris 版的JDK 中也对应提供了两个平台专有的虚拟桃参数:
--XX:+UseLWPSynchronization (默认值) 和-XX:+UseBoyndThreads 来明确指定虚拟
-机使用哪种线程模型。
+Threads或Alternate Libthread实现)及多对多( 通过LWP/Thread Based Synchronization实现) 的线程模型,因此在Solaris 版的JDK 中也对应提供了两个平台专有的虚拟机参数:
+```java
+-XX:+UseLWPSynchronization (默认值)
+-XX:+UseBoyndThreads
+```
+
+明确指定虚拟机使用哪种线程模型。
# Java线程调度
- 线程调度
系统为线程分配处理器使用权的过程,主要调度方式有两种
@@ -45,17 +48,15 @@ Threaids或Alternate Libthread实现)及多对多( 通过LWP/Thread Based Synchr
使用协同式调度的多线程系统,线程执行时间由线程本身控制,线程把自己工作执行完后,要主动通知系统切换到另外一个线程上。
协同式多线程
- 最大好处
-实现简单,而且由于线程要把自己的事情干完后才进行线程切换,切换操作对线程白己是可知的,所以没有什么线程同步的问题
+实现简单,而且由于线程要把自己的事情干完后才进行线程切换,切换操作对线程自己是可知的,所以没有什么线程同步的问题
- 坏处也很明显
线程执行时间不可控制
-使用抢占式调度的多线程系统,那么每个线程将由系统来分配执行时间,线程的切换不由线程本身决定,在这种实现线程调度的方式下,线程执行时间系统可控的
-Java使用的线程调度方式就是抢占式调度
+使用抢占式调度的多线程系统,那么每个线程将由系统来分配执行时间,线程的切换不由线程本身决定,在这种实现线程调度的方式下,线程执行时间系统可控的。Java使用的线程调度方式就是抢占式调度。
-虽然Java线程调度是系统自动完成的,但是我们还是可“建议”系统给某些线程多分配一点执行时间,可以通过设置线程优先级来完成。Java 语言一共设置了10个级别的线程优先级(Thread.MIN_PRIORITY 至Thread.MAX_PRIORITY ),在两个线程同时处于Ready 状态时,优先级越高的线程越容易被系统选择执行。
+虽然Java线程调度是系统自动完成的,但是我们还是可以“建议”系统给某些线程多分配一点执行时间,可以通过设置线程优先级来完成。Java 语言一共设置了10个级别的线程优先级(Thread.MIN_PRIORITY 至Thread.MAX_PRIORITY ),在两个线程同时处于Ready 状态时,优先级越高的线程越容易被系统选择执行。
-Java 的线程是通过映射到系统的原生线程上来实现的,所以线程调度最终还是取决于OS,虽然现在很多OS都提供线程优先级的概念,但是并不见得能与Java线程的优先级对应,如Solaris中有2147483648 (232 )种优先级,但Windows中就只有7种,比Java 线程优先级多的系统还好说,中间留下一点空位就可以了,但比Java线程优先级少的系统,就不得不出现几个优先级相同的情况了
+Java 的线程是通过映射到系统的原生线程上来实现的,所以线程调度最终还是取决于OS,虽然现在很多OS都提供线程优先级的概念,但是并不见得能与Java线程的优先级对应,如Solaris中有2147483648 (2^32 )种优先级,但Windows中就只有7种,比Java 线程优先级多的系统还好说,中间留下一点空位就可以了,但比Java线程优先级少的系统,就不得不出现几个优先级相同的情况了
不仅仅是说在一些平台上不同的优先级实际会变得相同这一点,还有其他情况让我们不能太依赖优先级:优先级可能会被系统自行改变。
-例如,在Windows 系统中存在一个称为“优先级推进器”(Priority Boosting,当然它可以被
-关闭掉) 的功能,它的大致作用就是当系统发现一个线程执行得特别“勤奋努力”的话,可能会越过线程优先级去为它分配执行时间。因此,我们不能在程序中通过优先级完全准确地判断一组状态都为Ready 的线程将会先执行哪一个
+例如,在Windows 系统中存在一个称为“优先级推进器”(Priority Boosting,当然它可以被关闭掉) 的功能,它的大致作用就是当系统发现一个线程执行得特别“勤奋努力”的话,可能会越过线程优先级去为它分配执行时间。因此,我们不能在程序中通过优先级完全准确地判断一组状态都为Ready 的线程将会先执行哪一个。
\ No newline at end of file
diff --git "a/Java/Java\344\270\255Collections-sort()\346\226\271\346\263\225\347\232\204\346\274\224\345\217\230.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255Collections-sort()\346\226\271\346\263\225\347\232\204\346\274\224\345\217\230.md"
similarity index 100%
rename from "Java/Java\344\270\255Collections-sort()\346\226\271\346\263\225\347\232\204\346\274\224\345\217\230.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255Collections-sort()\346\226\271\346\263\225\347\232\204\346\274\224\345\217\230.md"
diff --git "a/Java/Java\344\270\255\346\255\243\345\210\231\350\241\250\350\276\276\345\274\217.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\346\255\243\345\210\231\350\241\250\350\276\276\345\274\217.md"
similarity index 100%
rename from "Java/Java\344\270\255\346\255\243\345\210\231\350\241\250\350\276\276\345\274\217.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\346\255\243\345\210\231\350\241\250\350\276\276\345\274\217.md"
diff --git "a/Java/Java\344\270\255\347\232\204BlockingQueue.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\347\232\204BlockingQueue.md"
similarity index 100%
rename from "Java/Java\344\270\255\347\232\204BlockingQueue.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\347\232\204BlockingQueue.md"
diff --git "a/Java/Java\344\270\255\347\232\204VO,PO\347\255\211.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\347\232\204VO,PO\347\255\211.md"
similarity index 100%
rename from "Java/Java\344\270\255\347\232\204VO,PO\347\255\211.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\347\232\204VO,PO\347\255\211.md"
diff --git "a/Java/Java\344\270\255\347\232\204\351\224\201\344\274\230\345\214\226.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\347\232\204\351\224\201\344\274\230\345\214\226.md"
similarity index 100%
rename from "Java/Java\344\270\255\347\232\204\351\224\201\344\274\230\345\214\226.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\347\232\204\351\224\201\344\274\230\345\214\226.md"
diff --git "a/Java/Java\344\270\255\347\261\273\345\236\213\345\217\202\346\225\260\342\200\234-T-\342\200\235\345\222\214\346\227\240\347\225\214\351\200\232\351\205\215\347\254\246\342\200\234---\342\200\235\347\232\204\345\214\272\345\210\253.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\347\261\273\345\236\213\345\217\202\346\225\260\342\200\234-T-\342\200\235\345\222\214\346\227\240\347\225\214\351\200\232\351\205\215\347\254\246\342\200\234---\342\200\235\347\232\204\345\214\272\345\210\253.md"
similarity index 100%
rename from "Java/Java\344\270\255\347\261\273\345\236\213\345\217\202\346\225\260\342\200\234-T-\342\200\235\345\222\214\346\227\240\347\225\214\351\200\232\351\205\215\347\254\246\342\200\234---\342\200\235\347\232\204\345\214\272\345\210\253.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\344\270\255\347\261\273\345\236\213\345\217\202\346\225\260\342\200\234-T-\342\200\235\345\222\214\346\227\240\347\225\214\351\200\232\351\205\215\347\254\246\342\200\234---\342\200\235\347\232\204\345\214\272\345\210\253.md"
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\212\250\346\200\201\344\273\243\347\220\206\346\250\241\345\274\217\344\271\213JDK\345\222\214Cglib.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\212\250\346\200\201\344\273\243\347\220\206\346\250\241\345\274\217\344\271\213JDK\345\222\214Cglib.md"
new file mode 100644
index 0000000000..7b266e94e1
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\212\250\346\200\201\344\273\243\347\220\206\346\250\241\345\274\217\344\271\213JDK\345\222\214Cglib.md"
@@ -0,0 +1,273 @@
+# 动态代理 V.S 静态代理
+- Proxy类的代码被固定下来,不会因为业务的逐渐庞大而庞大
+- 可以实现AOP编程,这是静态代理无法实现的
+- 解耦,如果用在web业务下,可以实现数据层和业务层的分离
+- 动态代理的优势就是实现无侵入式的代码扩展。
+
+静态代理这个模式本身有个大问题,若类方法数量越来越多的时候,代理类的代码量十分庞大的。所以引入动态代理
+
+# 动态代理
+Java中动态代理的实现的关键:
+- Proxy
+- InvocationHandler
+
+### InvocationHandler#invoke
+- method
+调用的方法,即需要执行的方法
+- args
+方法的参数
+- proxy
+代理类的实例
+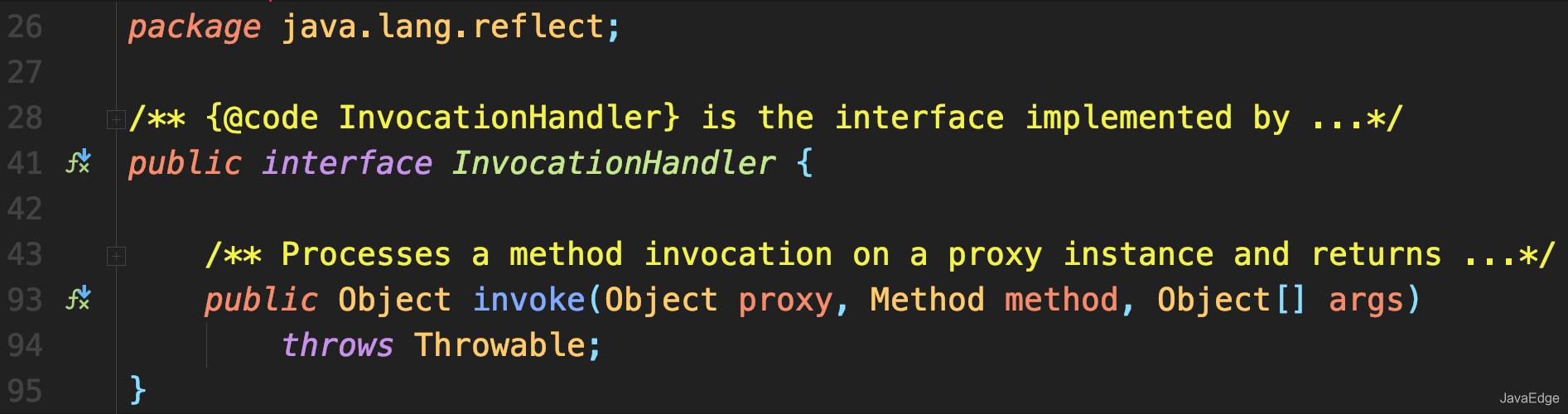
+
+# JDK动态代理
+JDK动态代理模式里有个拦截器,在JDK中,只要实现了**InvocationHandler**接口的类就是一个**拦截器类**。
+
+假如写了个请求到action,经过拦截器,然后才会到action,执行后续操作。
+拦截器就像一个过滤网,一层层过滤,只有满足一定条件,才能继续向后执行。
+**拦截器的作用**:控制目标对象的目标方法的执行。
+
+拦截器的具体操作步骤:
+1. 引入类
+目标类和一些扩展方法相关的类
+2. 赋值
+调用构造器,给相关对象赋值
+3. 合并逻辑处理
+在invoke方法中把所有的逻辑结合在一起。最终决定目标方法是否被调用
+
+## 示例
+
+
+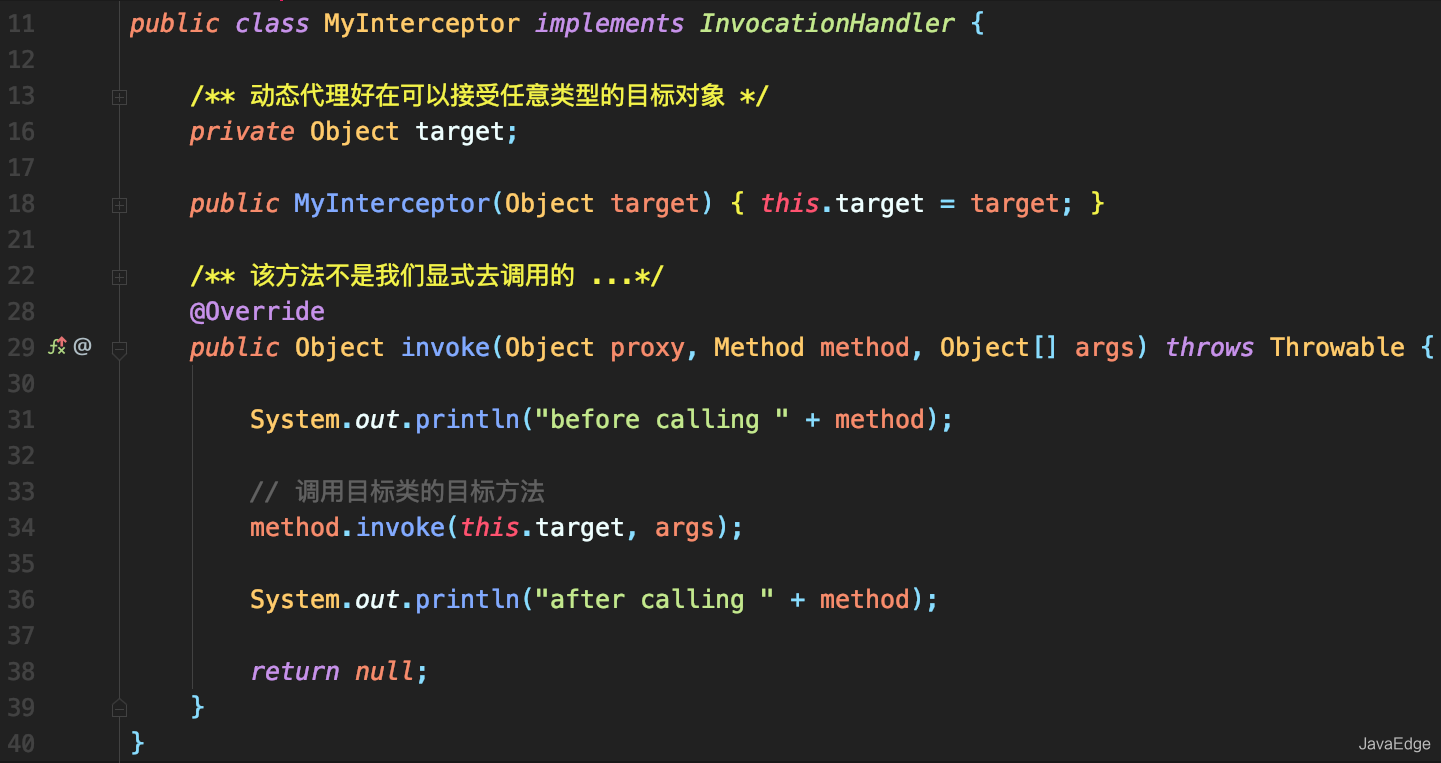
+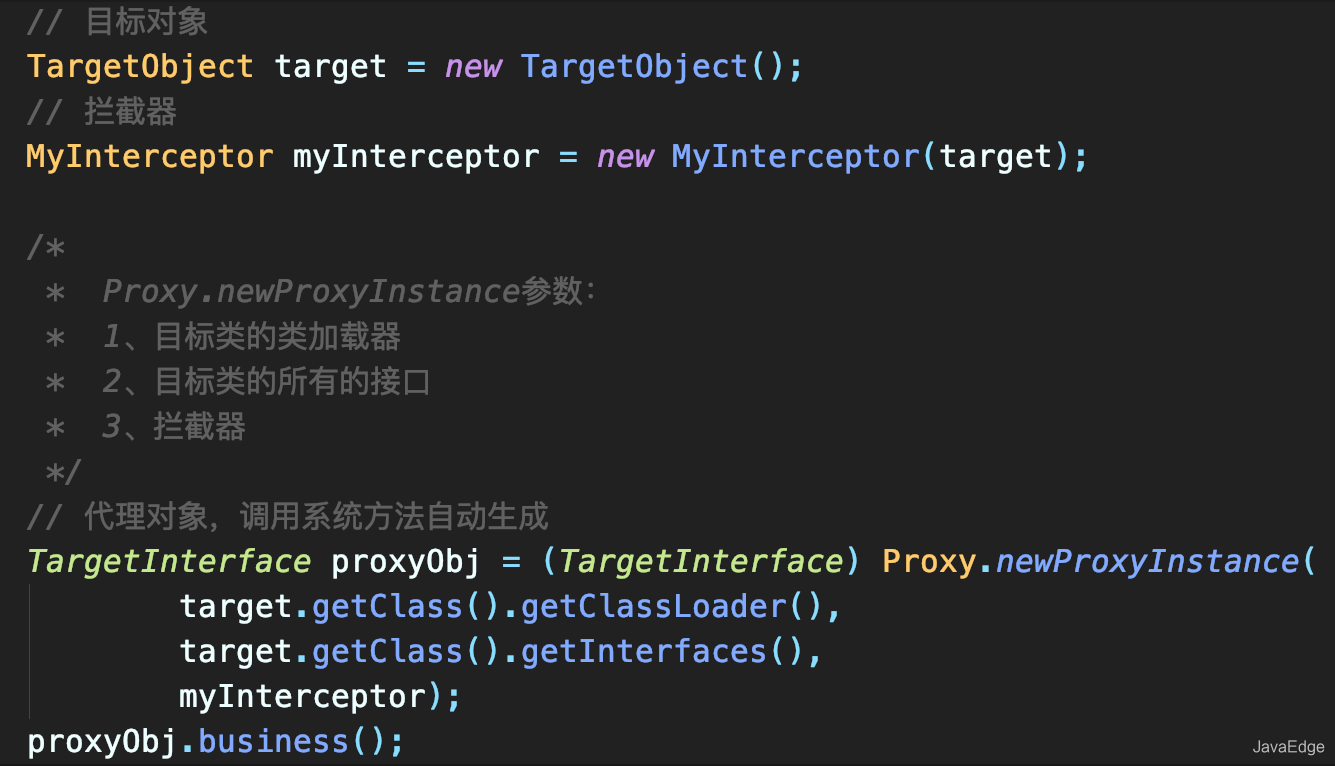
+思考如下问题:
+#### 代理对象由谁产生
+JVM,不像静态代理,我们得自己new个代理对象。
+#### 代理对象实现了什么接口
+实现的接口是目标对象实现的接口。
+同静态代理中代理对象实现的接口。那个继承关系图还是相同的。
+代理对象和目标对象都实现一个共同的接口。就是这个接口。
+所以Proxy.newProxyInstance()方法返回的类型就是这个接口类型。
+#### 代理对象的方法体是什么
+代理对象的方法体中的内容就是拦截器中invoke方法中的内容。
+
+所有代理对象的处理逻辑,控制是否执行目标对象的目标方法。都是在这个方法里面处理的。
+
+#### 拦截器中的invoke方法中的method参数是在什么时候赋值的
+在客户端,代理对象调用目标方法的时候,此实例中为:
+```java
+proxyObj.business();
+```
+
+实际上进入的是拦截器中的invoke方法,这时拦截器中的invoke方法中的method参数会被赋值。
+
+#### 为啥这叫JDK动态代理
+因为该动态代理对象是用JDK相关代码生成。
+
+很多同学对动态代理迷糊,在于`proxyObj.business();`理解错了,至少是被表面所迷惑,没有发现这个proxyObj和Proxy之间的联系,一度纠结最后调用的这个`business()`是怎么和`invoke()`联系上的,而invoke又怎么知道business存在的。
+
+其实上面的true和class $Proxy0就能解决很多的疑问,再加上下面将要说的$Proxy0的源码,完全可以解决动态代理的疑惑了。
+
+我们并没有显式调用invoke(),但是这个方法确实执行了。下面分析:
+
+从Client中的代码看,可以从newProxyInstance这个方法作为突破口,我们先来看一下Proxy类中newProxyInstance方法的源代码:
+```java
+public static Object newProxyInstance(ClassLoader loader,
+ Class[] interfaces,
+ InvocationHandler h) {
+ final Class[] intfs = interfaces.clone();
+ final SecurityManager sm = System.getSecurityManager();
+ if (sm != null) {
+ checkProxyAccess(Reflection.getCallerClass(), loader, intfs);
+ }
+
+ /*
+ * 查找或生成指定的代理类
+ * 创建代理类$Proxy0
+ * $Proxy0类实现了interfaces的接口,并继承了Proxy类
+ */
+ Class cl = getProxyClass0(loader, intfs);
+
+ /*
+ * 使用指定的调用处理程序调用其构造器
+ */
+ try {
+ if (sm != null) {
+ checkNewProxyPermission(Reflection.getCallerClass(), cl);
+ }
+ // 形参为InvocationHandler类型的构造器
+ final Constructor cons = cl.getConstructor(constructorParams);
+ final InvocationHandler ih = h;
+ if (!Modifier.isPublic(cl.getModifiers())) {
+ AccessController.doPrivileged(new PrivilegedAction() {
+ public Void run() {
+ cons.setAccessible(true);
+ return null;
+ }
+ });
+ }
+ return cons.newInstance(new Object[]{h});
+ } ...
+}
+```
+
+Proxy.newProxyInstance做了如下事:
+- 根据参数loader和interfaces调用方法 getProxyClass(loader, interfaces)创建代理类`$Proxy0`。`$Proxy0`类 实现了interfaces的接口,并继承了Proxy类
+- 实例化`$Proxy0`,并在构造器把DynamicSubject传过去,接着`$Proxy0`调用父类Proxy的构造器,为h赋值
+
+$Proxy0的源码:
+```java
+package com.sun.proxy;
+
+public final class $Proxy0 extends Proxy implements TargetInterface {
+ private static Method m1;
+ private static Method m3;
+ private static Method m2;
+ private static Method m0;
+
+ public $Proxy0(InvocationHandler var1) throws {
+ super(var1);
+ }
+
+ public final boolean equals(Object var1) throws {
+ try {
+ return (Boolean)super.h.invoke(this, m1, new Object[]{var1});
+ }...
+ }
+
+ public final void business() throws {
+ try {
+ super.h.invoke(this, m3, (Object[])null);
+ }...
+ }
+
+ public final String toString() throws {
+ try {
+ return (String)super.h.invoke(this, m2, (Object[])null);
+ }...
+ }
+
+ public final int hashCode() throws {
+ try {
+ return (Integer)super.h.invoke(this, m0, (Object[])null);
+ }...
+ }
+
+ static {
+ try {
+ m1 = Class.forName("java.lang.Object").getMethod("equals", Class.forName("java.lang.Object"));
+ m3 = Class.forName("com.javaedge.design.pattern.structural.proxy.dynamicproxy.jdkdynamicproxy.TargetInterface").getMethod("business");
+ m2 = Class.forName("java.lang.Object").getMethod("toString");
+ m0 = Class.forName("java.lang.Object").getMethod("hashCode");
+ }...
+ }
+}
+
+```
+接着把得到的`$Proxy0`实例强转成TargetInterface,并将引用赋给TargetInterface。当执行proxyObj.business(),就调用了`$Proxy0`类中的business()方法,进而调用父类Proxy中的h的invoke()方法。即`InvocationHandler.invoke()`。
+
+Proxy#getProxyClass返回的是Proxy的Class类,而非“被代理类的Class类”!
+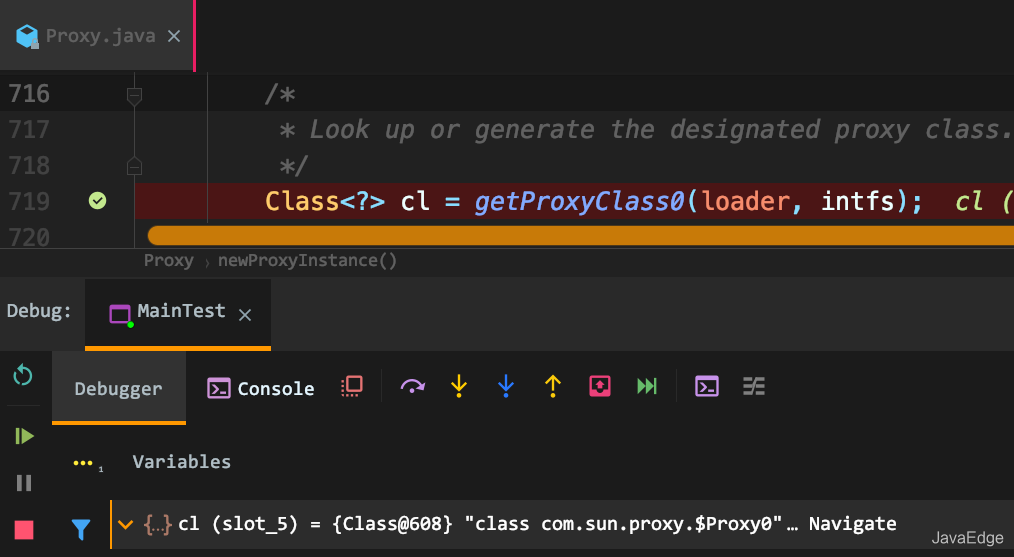
+
+# cglib动态代理
+就是因为要用到cglib的jar包,所以叫**cglib动态代理**。
+
+为什么要使用这个**cglib来实现这个动态代理**呢?因为spring框架要用。
+
+具体的代码实现如下:
+```java
+目标对象类:
+package com.sss.designPattern.proxy.dynamicProxy.cglbDynamicProxy;
+
+/**
+ * 被代理的类
+ * 目标对象类
+ */
+public class TargetObject {
+
+ /**
+ * 目标方法(即目标操作)
+ */
+ public void business() {
+ System.out.println("business");
+ }
+
+}
+
+拦截器类:
+package com.sss.designPattern.proxy.dynamicProxy.cglbDynamicProxy;
+
+import net.sf.cglib.proxy.Enhancer;
+import net.sf.cglib.proxy.MethodInterceptor;
+import net.sf.cglib.proxy.MethodProxy;
+
+import java.lang.reflect.Method;
+
+/**
+ * 动态代理-拦截器
+ */
+public class MyInterceptor implements MethodInterceptor {
+ private Object target;//目标类
+
+ public MyInterceptor(Object target) {
+ this.target = target;
+ }
+
+ /**
+ * 返回代理对象
+ * 具体实现,暂时先不追究。
+ */
+ public Object createProxy() {
+ Enhancer enhancer = new Enhancer();
+ enhancer.setCallback(this);//回调函数 拦截器
+ //设置代理对象的父类,可以看到代理对象是目标对象的子类。所以这个接口类就可以省略了。
+ enhancer.setSuperclass(this.target.getClass());
+ return enhancer.create();
+ }
+
+ /**
+ * args 目标方法的参数
+ * method 目标方法
+ */
+ @Override
+ public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
+ System.out.println("aaaaa");//切面方法a();
+ //。。。
+ method.invoke(this.target, objects);//调用目标类的目标方法
+ //。。。
+ System.out.println("bbbbb");//切面方法f();
+ return null;
+ }
+}
+
+测试类:
+package com.sss.designPattern.proxy.dynamicProxy.cglbDynamicProxy;
+
+public class MainTest {
+ public static void main(String[] args) {
+ //目标对象
+ TargetObject target = new TargetObject();
+ //拦截器
+ MyInterceptor myInterceptor = new MyInterceptor(target);
+ //代理对象,调用cglib系统方法自动生成
+ //注意:代理类是目标类的子类。
+ TargetObject proxyObj = (TargetObject) myInterceptor.createProxy();
+ proxyObj.business();
+ }
+}
+```
+区别:
+首先从文件数上来说,cglib比jdk实现的少了个接口类。因为cglib返回的代理对象是目标对象的子类。而jdk产生的代理对象和目标对象都实现了一个公共接口。
+
+动态代理分为两种:
+ * jdk的动态代理
+ * 代理对象和目标对象实现了共同的接口
+ * 拦截器必须实现InvocationHanlder接口
+
+ * cglib的动态代理
+ * 代理对象是目标对象的子类
+ * 拦截器必须实现MethodInterceptor接口
+ * hibernate中session.load采用的是cglib实现的
+
+> 参考
+> - https://blog.csdn.net/zcc_0015/article/details/22695647
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\217\215\345\260\204\351\201\207\345\210\260\346\263\233\345\236\213\346\227\266\347\232\204bug.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\217\215\345\260\204\351\201\207\345\210\260\346\263\233\345\236\213\346\227\266\347\232\204bug.md"
new file mode 100644
index 0000000000..c16c89e15f
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\217\215\345\260\204\351\201\207\345\210\260\346\263\233\345\236\213\346\227\266\347\232\204bug.md"
@@ -0,0 +1,125 @@
+# 1 当反射遇见重载
+重载**level**方法,入参分别是**int**和**Integer**。
+若不使用反射,选用哪个重载方法很清晰,比如:
+- 传入**666**就走int参数重载
+- 传入`Integer.valueOf(“666”)`走Integer重载
+
+那反射调用方法也是根据入参类型确定使用哪个重载方法吗?
+使用`getDeclaredMethod`获取 `grade`方法,然后传入`Integer.valueOf(“36”)`
+
+结果是:
+
+因为反射进行方法调用是通过
+## 方法签名
+来确定方法。本例的`getDeclaredMethod`传入的参数类型`Integer.TYPE`其实代表`int`。
+
+所以不管传包装类型还是基本类型,最终都是调用int入参重载方法。
+
+将`Integer.TYPE`改为`Integer.class`,则实际执行的参数类型就是Integer了。且无论传包装类型还是基本类型,最终都调用Integer入参重载方法。
+
+综上,反射调用方法,是以反射获取方法时传入的方法名和参数类型来确定调用的方法。
+
+# 2 泛型的类型擦除
+泛型允许SE使用类型参数替代精确类型,实例化时再指明具体类型。利于代码复用,将一套代码应用到多种数据类型。
+
+泛型的类型检测,可以在编译时检查很多泛型编码错误。但由于历史兼容性而妥协的泛型类型擦除方案,在运行时还有很多坑。
+
+## 案例
+现在期望在类的字段内容变动时记录日志,于是SE想到定义一个泛型父类,并在父类中定义一个统一的日志记录方法,子类可继承该方法。上线后总有日志重复记录。
+
+- 父类
+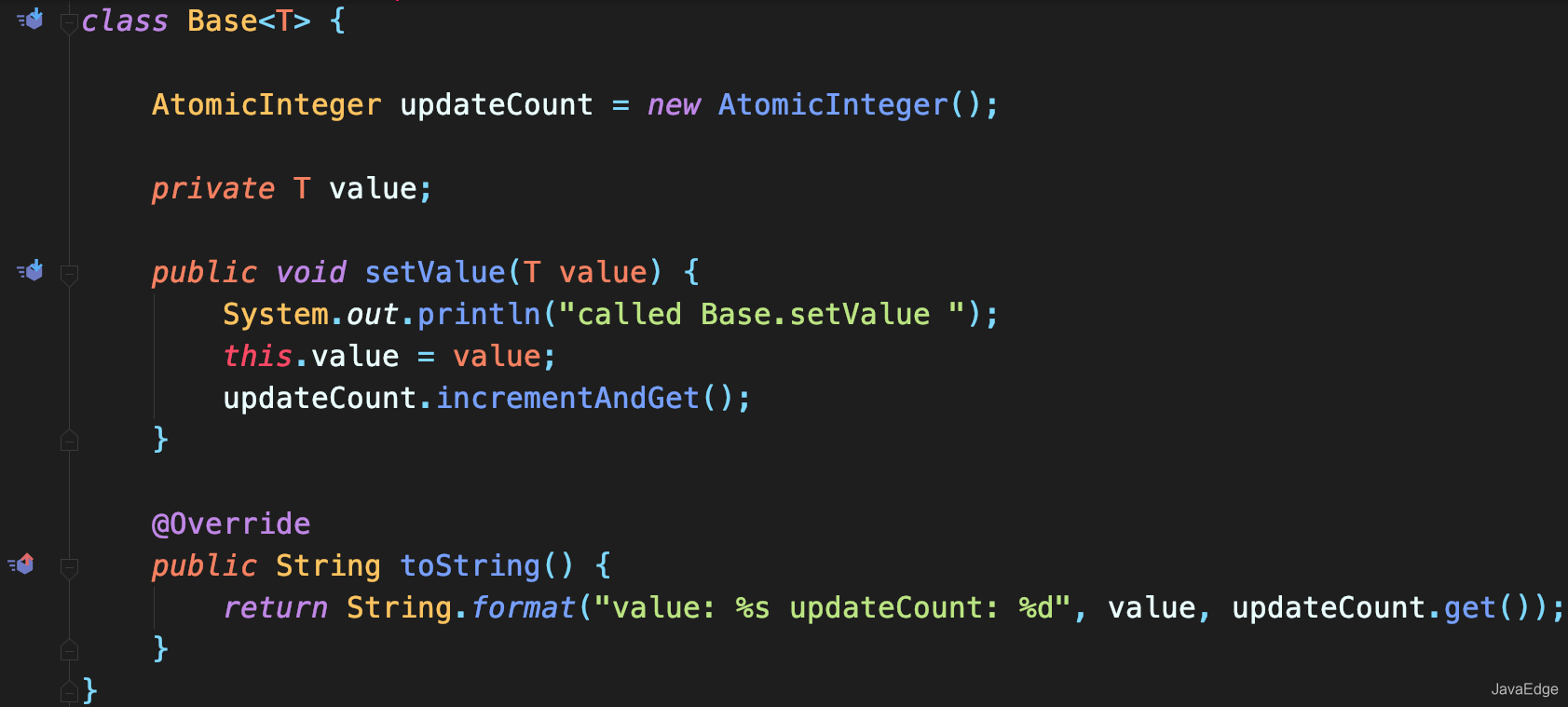
+- 子类1
+
+- 通过反射调用子类方法:
+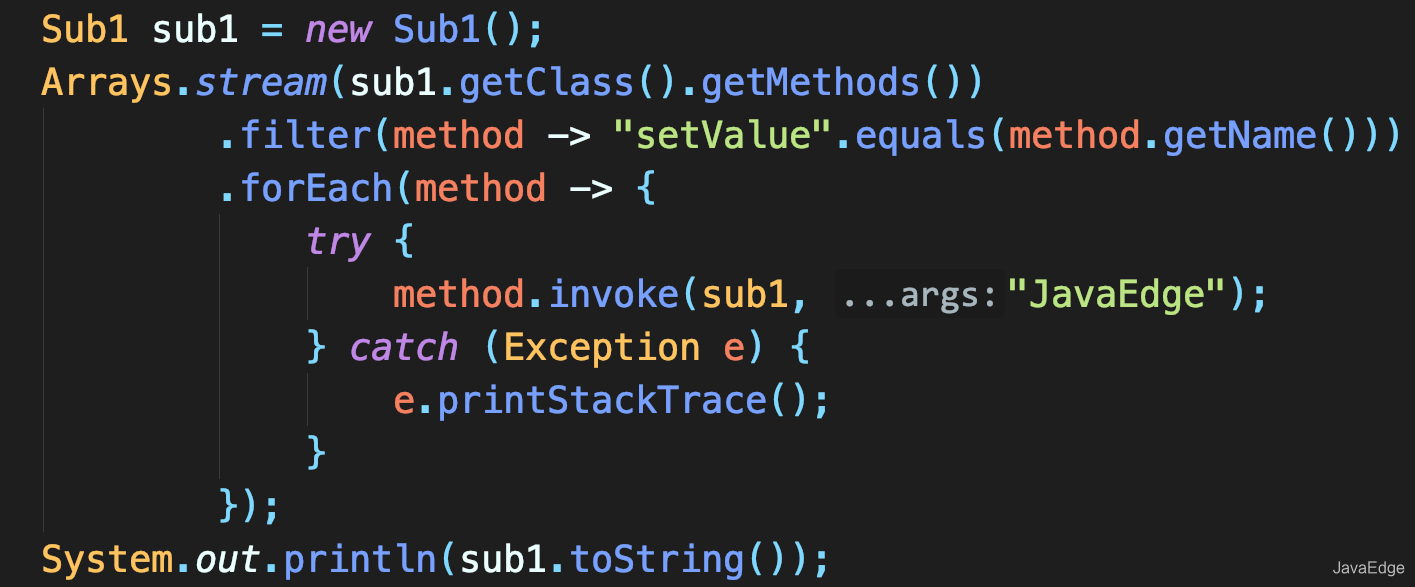
+
+虽Base.value正确设置为了JavaEdge,但父类setValue调用了两次,计数器显示2
+
+
+两次调用Base.setValue,是因为getMethods找到了两个`setValue`:
+
+
+
+### 子类重写父类方法失败原因
+- 子类未指定String泛型参数,父类的泛型方法`setValue(T value)`泛型擦除后是`setValue(Object value)`,于是子类入参String的`setValue`被当作新方法
+- 子类的`setValue`未加`@Override`注解,编译器未能检测到重写失败
+
+
+有的同学会认为是因为反射API使用错误导致而非重写失败:
+- `getMethods`
+得到**当前类和父类**的所有`public`方法
+- `getDeclaredMethods`
+获得**当前类**所有的public、protected、package和private方法
+
+于是用`getDeclaredMethods`替换`getMethods`:
+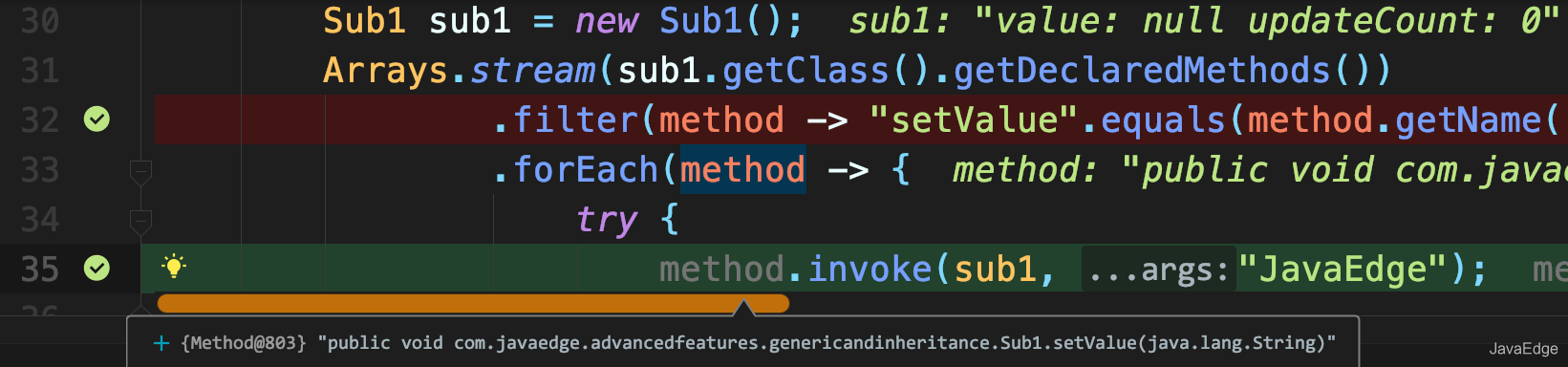
+虽然这样做可以规避重复记录日志,但未解决子类重写父类方法失败的问题
+- 使用Sub1时还是会发现有俩个`setValue`
+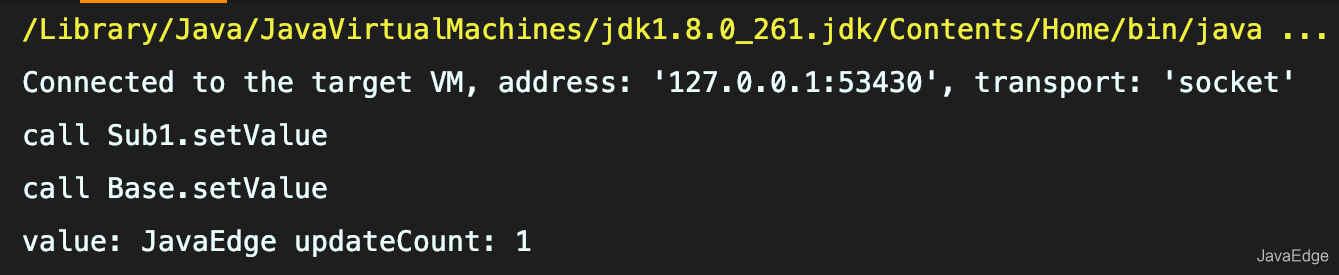
+
+于是,终于明白还得重新实现**Sub2**,继承Base时将**String**作为泛型T类型,并使用 **@Override** 注解 **setValue**
+
+
+- 但还是出现重复日志
+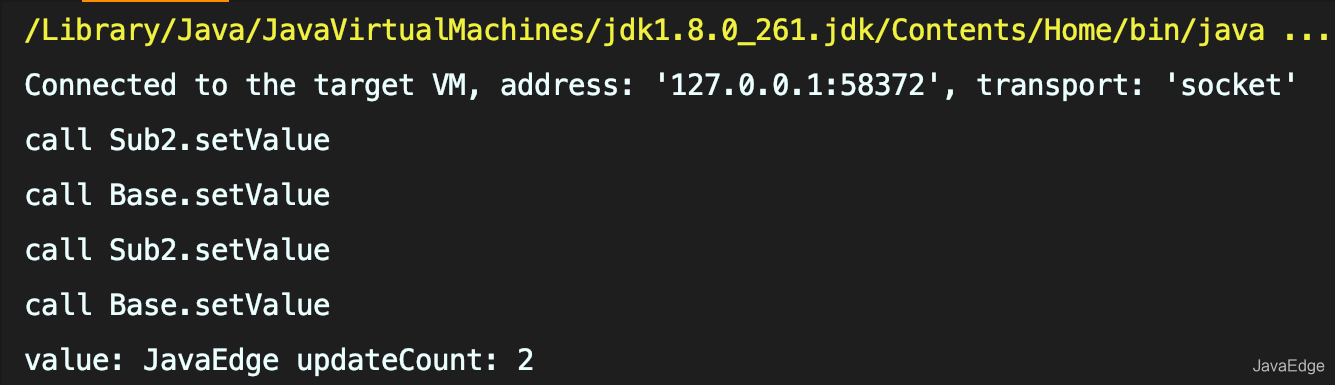
+Sub2的`setValue`竟然调用了两次,难道是JDK反射有Bug!`getDeclaredMethods`查找到的方法肯定来自`Sub2`;而且Sub2看起来也就一个setValue,怎么会重复?
+
+调试发现,Child2类其实有俩`setValue`:入参分别是String、Object。
+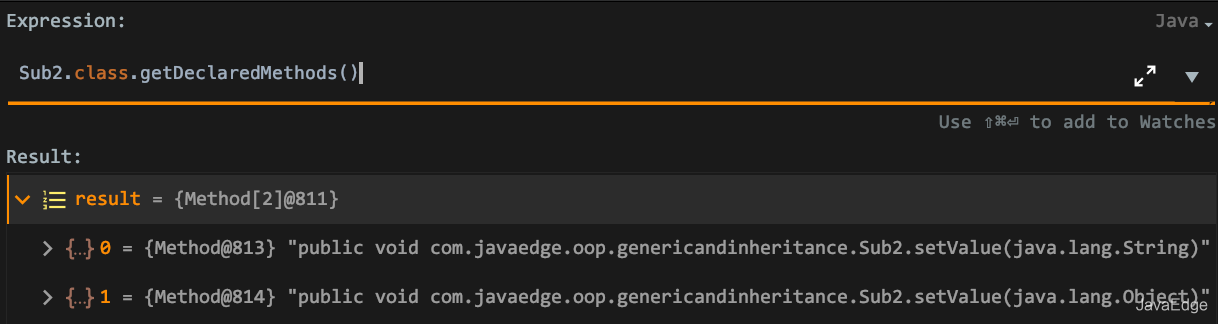
+这就是因为**泛型类型擦除**。
+
+## 反射下的泛型擦除“天坑”
+Java泛型类型在编译后被擦除为**Object**。子类虽指定父类泛型T类型是**String**,但编译后T会被擦除成为Object,所以父类`setValue`入参是**Object**,value也是**Object**。
+若**Sub2.setValue**想重写父类,那入参也须为**Object**。所以,编译器会为我们生成一个桥接方法。
+Sub2类的class字节码:
+```bash
+➜ genericandinheritance git:(master) ✗ javap -c Sub2.class
+Compiled from "GenericAndInheritanceApplication.java"
+class com.javaedge.oop.genericandinheritance.Sub2 extends com.javaedge.oop.genericandinheritance.Base {
+ com.javaedge.oop.genericandinheritance.Sub2();
+ Code:
+ 0: aload_0
+ 1: invokespecial #1 // Method com/javaedge/oop/genericandinheritance/Base."":()V
+ 4: return
+
+ public void setValue(java.lang.String);
+ Code:
+ 0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
+ 3: ldc #3 // String call Sub2.setValue
+ 5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
+ 8: aload_0
+ 9: aload_1
+ 10: invokespecial #5 // Method com/javaedge/oop/genericandinheritance/Base.setValue:(Ljava/lang/Object;)V
+ 13: return
+
+ public void setValue(java.lang.Object);
+ Code:
+ 0: aload_0
+ 1: aload_1
+ 2: checkcast #6 // class java/lang/String
+ // 入参为Object的setValue在内部调用了入参为String的setValue方法
+ 5: invokevirtual #7 // Method setValue:(Ljava/lang/String;)V
+ 8: return
+}
+```
+若编译器未帮我们实现该桥接方法,则Sub2重写的是父类泛型类型擦除后、入参是Object的setValue。这两个方法的参数,一个String一个Object,显然不符Java重写。
+
+入参为Object的桥接方法上标记了`public synthetic bridge`:
+- synthetic代表由编译器生成的不可见代码
+- bridge代表这是泛型类型擦除后生成的桥接代码
+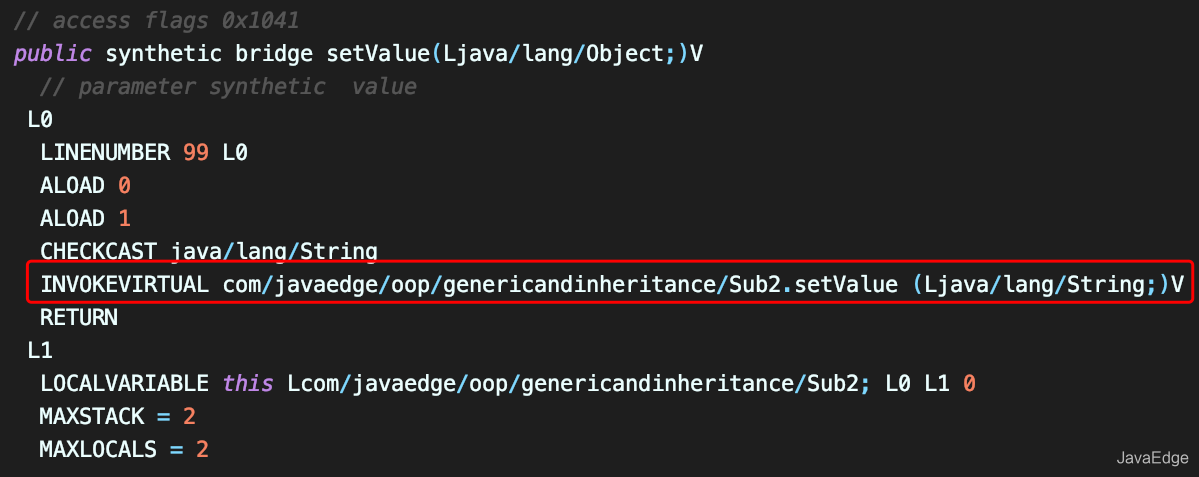
+
+## 修正
+知道了桥接方法的存在,现在就该知道如何修正代码了。
+- 通过**getDeclaredMethods**获取所有方法后,还得加上非isBridge这个过滤条件:
+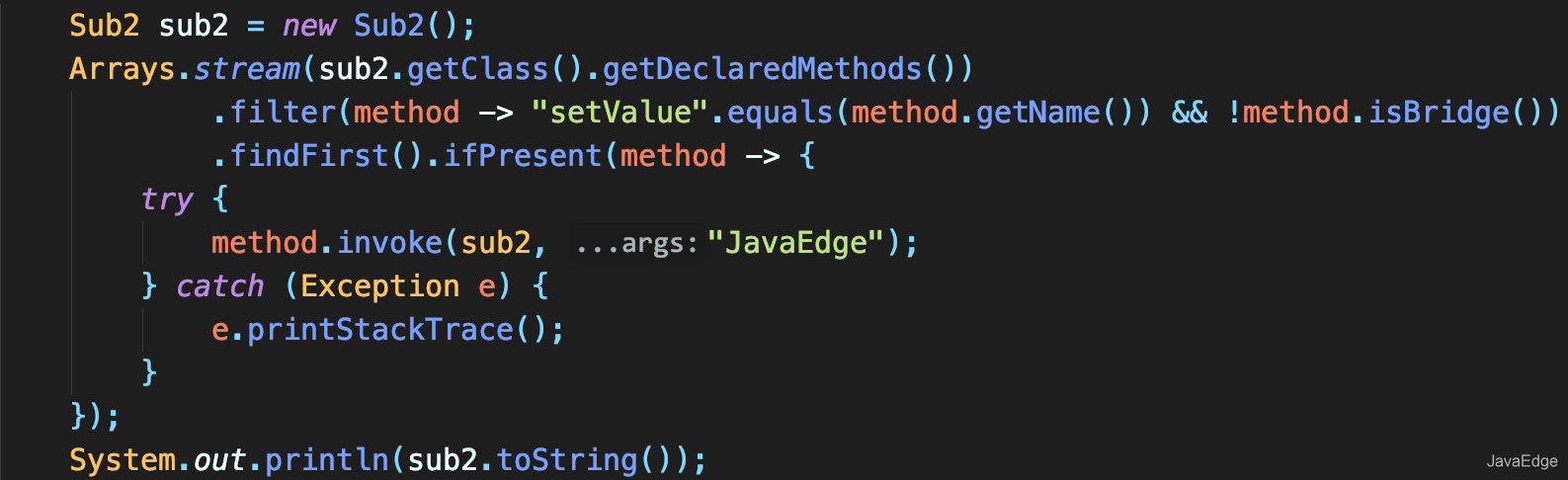
+- 结果
+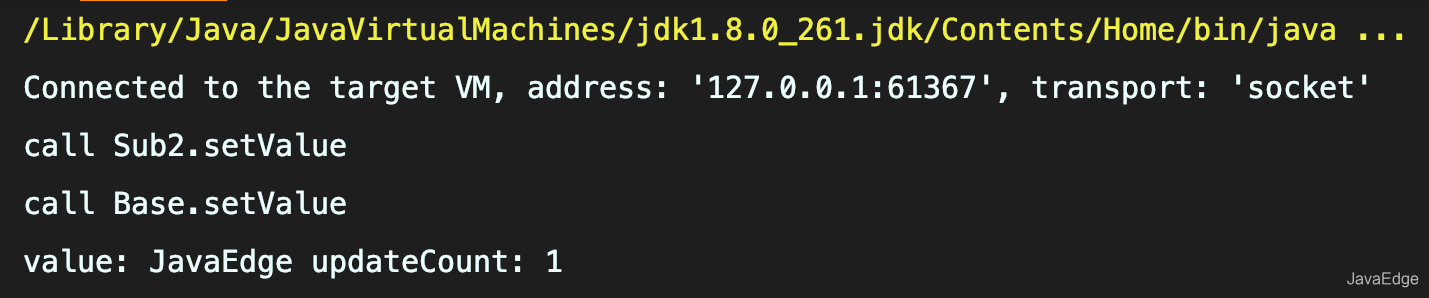
+> 参考
+> - https://docs.oracle.com/javase/8/docs/technotes/guides/reflection/index.html
+> - https://docs.oracle.com/javase/tutorial/reflect/index.html
+> - https://docs.oracle.com/javase/8/docs/technotes/guides/language/annotations.html
+> - https://docs.oracle.com/javase/tutorial/java/annotations/index.html
+> - https://docs.oracle.com/javase/8/docs/technotes/guides/language/generics.html
+> - https://docs.oracle.com/javase/tutorial/java/generics/index.html
\ No newline at end of file
diff --git "a/Java/Java\345\244\232\347\272\277\347\250\213\344\270\255join\346\226\271\346\263\225\347\232\204\347\220\206\350\247\243.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\244\232\347\272\277\347\250\213\344\270\255join\346\226\271\346\263\225\347\232\204\347\220\206\350\247\243.md"
similarity index 100%
rename from "Java/Java\345\244\232\347\272\277\347\250\213\344\270\255join\346\226\271\346\263\225\347\232\204\347\220\206\350\247\243.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\244\232\347\272\277\347\250\213\344\270\255join\346\226\271\346\263\225\347\232\204\347\220\206\350\247\243.md"
diff --git "a/Java/Java\345\257\271\350\261\241\345\272\217\345\210\227\345\214\226\345\272\225\345\261\202\345\216\237\347\220\206\346\272\220\347\240\201\350\247\243\346\236\220.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\257\271\350\261\241\345\272\217\345\210\227\345\214\226\345\272\225\345\261\202\345\216\237\347\220\206\346\272\220\347\240\201\350\247\243\346\236\220.md"
similarity index 99%
rename from "Java/Java\345\257\271\350\261\241\345\272\217\345\210\227\345\214\226\345\272\225\345\261\202\345\216\237\347\220\206\346\272\220\347\240\201\350\247\243\346\236\220.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\257\271\350\261\241\345\272\217\345\210\227\345\214\226\345\272\225\345\261\202\345\216\237\347\220\206\346\272\220\347\240\201\350\247\243\346\236\220.md"
index 9897731976..18d6d00333 100644
--- "a/Java/Java\345\257\271\350\261\241\345\272\217\345\210\227\345\214\226\345\272\225\345\261\202\345\216\237\347\220\206\346\272\220\347\240\201\350\247\243\346\236\220.md"
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\257\271\350\261\241\345\272\217\345\210\227\345\214\226\345\272\225\345\261\202\345\216\237\347\220\206\346\272\220\347\240\201\350\247\243\346\236\220.md"
@@ -15,7 +15,7 @@ package test;
import java.io.*;
/**
- * @author v_shishusheng
+ * @author v_JavaEdge
* @date 2018/2/7
*/
public class SerializableTest {
@@ -597,7 +597,7 @@ d3c6 7e1c 4f13 2afe 序列号
70 标志位:TC_NULL,Null object reference.
0000 00c8 innervalue的值:200
```
-##3. 反序列化:readObject()
+## 3. 反序列化:readObject()
反序列化过程就是按照前面介绍的序列化算法来解析二进制数据。
有一个需要注意的问题就是,如果子类实现了Serializable接口,但是父类没有实现Serializable接口,这个时候进行反序列化会发生什么情况?
diff --git "a/Java/Java\345\274\200\345\217\221\344\272\272\345\221\230\345\277\205\345\244\207linux\345\221\275\344\273\244.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\274\200\345\217\221\344\272\272\345\221\230\345\277\205\345\244\207linux\345\221\275\344\273\244.md"
similarity index 100%
rename from "Java/Java\345\274\200\345\217\221\344\272\272\345\221\230\345\277\205\345\244\207linux\345\221\275\344\273\244.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\274\200\345\217\221\344\272\272\345\221\230\345\277\205\345\244\207linux\345\221\275\344\273\244.md"
diff --git "a/Java/Java\345\274\202\345\270\270\344\271\213IllegalMonitorStateException.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\274\202\345\270\270\344\271\213IllegalMonitorStateException.md"
similarity index 100%
rename from "Java/Java\345\274\202\345\270\270\344\271\213IllegalMonitorStateException.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\274\202\345\270\270\344\271\213IllegalMonitorStateException.md"
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\274\202\345\270\270\346\234\272\345\210\266\347\232\204\346\234\200\344\275\263\345\256\236\350\267\265.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\274\202\345\270\270\346\234\272\345\210\266\347\232\204\346\234\200\344\275\263\345\256\236\350\267\265.md"
new file mode 100644
index 0000000000..94d0c23c1e
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\345\274\202\345\270\270\346\234\272\345\210\266\347\232\204\346\234\200\344\275\263\345\256\236\350\267\265.md"
@@ -0,0 +1,2091 @@
+**Java 的基本理念是“结构不佳的代码不能运行”。**
+
+改进的错误恢复机制是提高代码健壮性的最强有力的方式。错误恢复在我们所编写的每一个程序中都是基本的要素,但是在 Java 中它显得格外重要,因为 Java 的主要目标之一就是创建供他人使用的程序构件。
+
+发现错误的理想时机是在编译期。然而,编译期并不能找出所有错误,余下问题必须在运行时解决。这就需要错误源能通过某种方式,把适当的信息传递给知道如何正确处理这个问题的接收者。
+
+> 要想创建健壮的系统,它的每一个构件都必须是健壮的。
+
+Java 使用异常来提供一致的错误报告模型,使得构件能够与客户端代码可靠地沟通问题。
+
+- Java 中的异常处理的目的
+通过使用少于目前数量的代码来简化大型、可靠的程序的生成,并且通过这种方式可以使你更加确信你的应用中没有未处理的错误。异常的相关知识学起来并非艰涩难懂,并且它属于那种可以使你的项目受益明显、立竿见影的特性。
+
+因为异常处理是 Java 中唯一官方的错误报告机制,并且通过编译器强制执行,所以不学习异常处理的话,也就只能写出那么些例子了。本章重在如何编写正确的异常处理程序,当方法出问题的时候,如何产生自定义的异常。
+
+# 1 异常概念
+## 1.1 历史中所谓的“异常”
+C 以及其他早期语言常常具有多种错误处理模式,这些模式往往建立在约定俗成的基础上,并不属于语言规范。
+
+通常是会返回某个特殊值或者设置某个标志,并且假定接收者将对这个返回值或标志进行检查,以判定是否发生了错误。
+然而,随着时间的推移,人们发现,高傲的程序员们在使用程序库的时候更倾向于认为:“对,错误也许会发生,但那是别人造成的,不关我的事”。所以,程序员不去检查错误情形也就不足为奇了(对某些错误情形的检查确实无聊)。如果的确在每次调用方法的时候都彻底地进行错误检查,代码很可能会变得难以阅读。
+正是由于程序员还仍然用这些方式拼凑系统,所以他们拒绝承认这样一个事实:对于构造大型、健壮、可维护的程序而言,这种错误处理模式已经成为了主要障碍。
+
+## 解决方案
+强制规定形式,来消除错误处理过程中的随心所欲。
+这种做法由来已久,对异常处理的实现可以追溯到1960s的操作系统,甚至BASIC中的“on error goto”语句。C++的异常处理机制基于 Ada,Java 中的异常处理机制则建立在 C++ 的基础上。
+
+“异常”这个词有“我对此感到意外”的意思。问题出现你也许不清楚如何处理,但你知道不该置之不理,你要停下来看看是不是有地方能够处理这个问题。
+只是在当前的环境中还没有足够的信息来解决这个问题,所以就把这个问题提交到一个更高级别的环境中,在那里将作出正确的决定。
+
+异常往往能降低错误处理代码的复杂度。
+如果不使用异常,那么就必须检查特定的错误,并在程序中的许多地方去处理它。而如果使用异常,那就不必在方法调用处检查,因为异常机制将保证能够捕获这个错误。理想情况下,只需在一个地方处理错误,即所谓的异常处理程序。
+这种方式不仅节省代码,而且把“描述在正常执行过程中做什么事”的代码和“出了问题怎么办”的代码相分离。总之,与以前的错误处理方法相比,异常机制使代码的阅读、编写和调试工作更加井井有条。
+
+# 2 基本异常
+注意把异常情形与普通问题相区分:
+- 普通问题
+在当前环境下能得到足够的信息,总能处理这个错误
+- 异常情形(exceptional condition)
+阻止当前方法或作用域继续执行,就不能继续下去了,因为在当前环境下无法获得必要的信息来解决问题。你所能做的就是从当前环境跳出,并且把问题提交给上一级环境。这就是抛出异常时所发生的事情。
+
+## 简单的例子
+除法就是一个除数有可能为 0,所以先进行检查很有必要。
+但除数为 0 代表的究竟是什么意思呢?通过当前正在解决的问题环境,或许能知道该如何处理除数为 0 的情况。但如果这是一个意料之外的值,你也不清楚该如何处理,那就要抛出异常,而不是顺着原来的路径继续执行下去。
+
+## 抛出异常后
+1. 同 Java 中其他对象的创建一样,将使用 new 在堆上创建异常对象
+2. 当前的执行路径(无法继续)被终止,并且从当前环境中弹出对异常对象的引用
+3. 异常处理机制接管程序,并开始寻找一个恰当的地方来继续执行程序。这个恰当的地方就是异常处理程序,它的任务是将程序从错误状态中恢复,以使程序能要么换一种方式运行,要么继续运行下去。
+
+## 抛出异常的简单例子
+对于对象引用 t,传给你可能尚未初始化。所以在使用这个对象引用调用其方法之前,会先对引用进行检查。可以创建一个代表错误信息的对象,并且将它从当前环境中“抛出”,这样就把错误信息传播到了“更大”的环境中。
+这被称为*抛出一个异常*,看起来像这样:
+
+```java
+if(t == null)
+ throw new NullPointerException();
+```
+
+这就抛出了异常,于是在当前环境下就不必再为这个问题操心了,它将在别的地方得到处理。
+
+## 异常模型的观点
+- 异常使得我们可以将每件事都当作一个事务来考虑,而异常可以看护着这些事务的底线,事务的基本保障是我们所需的在分布式计算中的异常处理。事务是计算机中的合同法,如果出了什么问题,我们只需要放弃整个计算
+- 我们还可以将异常看作是一种内建的撤销系统,因为(在细心使用的情况下)我们在程序中可以拥有各种不同的撤销点。如果程序的某部分失败了,异常将撤销到程序中某个已知的稳定点上。
+
+异常最重要的方面之一就是如果发生问题,它们将不允许程序沿着其正常的路径继续走下去。在 C 和 C++ 这样的语言中,这可真是个问题,尤其是 C,它没有任何办法可以强制程序在出现问题时停止在某条路径上运行下去,因此我们有可能会较长时间地忽略问题,从而会陷入完全不恰当的状态中。异常允许我们(如果没有其他手段)强制程序停止运行,并告诉我们出现了什么问题,或者(理想状态下)强制程序处理问题,并返回到稳定状态。
+
+## 异常参数
+与使用 Java 中的其他对象一样,用 new 在堆上创建异常对象,这也伴随着存储空间的分配和构造器的调用。
+所有标准异常类都有两个构造器:
+- 无参构造器
+- 接受字符串作为参数,以便能把相关信息放入异常对象构造器
+```java
+throw new NullPointerException("t = null");
+```
+
+关键字 **throw** 将产生许多有趣的结果。在使用 **new** 创建了异常对象之后,此对象的引用将传给 **throw**。
+尽管异常对象的类型通常与方法设计的返回类型不同,但从效果上看,它就像是从方法“返回”的。可以简单地把异常处理看成一种不同的返回机制,当然若过分强调这种类比的话,就会有麻烦了。
+另外还能用抛出异常的方式从当前的作用域退出。在这两种情况下,将会返回一个异常对象,然后退出方法或作用域。
+
+抛出异常与方法正常返回的相似之处到此为止。因为异常返回的“地点”与普通方法调用返回的“地点”完全不同。
+异常将在一个恰当的异常处理程序中得到解决,它的位置可能离异常被抛出的地方很远,也可能会跨越方法调用栈的许多层级。
+
+此外,能够抛出任意类型的 **Throwable** 对象,它是异常类型的根类。通常,对于不同类型错误,要抛相应异常。错误信息可以保存在异常对象内部或者用异常类的名称来暗示。上一层环境通过这些信息来决定如何处理异常。
+
+> 通常,唯一的信息只有异常的类型名,而在异常对象内部没有任何有意义的信息
+
+# 3 异常捕获
+
+- 首先要理解监控区域(guarded region)的概念
+它是一段可能产生异常的代码,并且后面跟着处理这些异常的代码。
+
+## 3.1 try 块
+如果在方法内部抛异常(或在方法内部调用的其他方法抛异常),该方法将在抛异常过程中结束。要是不希望方法就此结束,可在方法内设置一个特殊的块来捕获异常。因为在这个块里“尝试”各种(可能产生异常的)方法调用,所以称为 try 块。它是跟在 try 关键字之后的普通程序块:
+
+```java
+try {
+ // Code that might generate exceptions
+}
+```
+### 意义
+对于不支持异常处理的程序语言,要想仔细检查错误,就得在每个方法调用的前后加上设置和错误检查的代码,甚至在每次调用同一方法时也得这么做。
+有了异常处理机制,可以把所有动作都放在 try 块,然后只需在一个地方就可以捕获所有异常。这意味着你的代码将更容易编写和阅读,因为代码的意图和错误检查不是混淆在一起。
+
+## 3.2 异常处理程序 - catch 块
+抛出的异常必须在 异常处理程序 得到处理。针对每个要捕获的异常,得准备相应的处理程序。
+异常处理程序紧跟在 try 块之后,以关键字 catch 表示:
+```java
+try {
+ // Code that might generate exceptions
+} catch(Type1 id1) {
+ // Handle exceptions of Type1
+} catch(Type2 id2) {
+ // Handle exceptions of Type2
+} catch(Type3 id3) {
+ // Handle exceptions of Type3
+}
+```
+
+每个 catch (异常处理程序)看起来就像是接收且仅接收一个特殊类型的参数的方法。可以在处理程序的内部使用标识符(id1,id2 等等),这与方法参数的使用很相似。有时可能用不到标识符,因为异常的类型已经给了你足够的信息来对异常进行处理,但标识符并不可以省略。
+
+异常处理程序必须紧跟在 try 块后。当异常被抛出时,异常处理机制将负责搜寻参数与异常类型相匹配的第一个处理程序。然后进入 catch 子句执行,此时认为异常得到了处理。
+一旦 catch 子句结束,则处理程序的查找过程结束。注意,只有匹配的 catch 子句才能得到执行。
+
+### 意义
+注意在 try 块的内部,许多不同的方法调用可能会产生类型相同的异常,而你只需要提供一个针对此类型的异常处理程序。
+
+## 3.3 终止与恢复
+异常处理理论上有两种基本模型。
+### 3.3.1 终止模型
+Java 和 C++所支持的模型。
+将假设错误非常严重,以至于程序无法返回到异常发生的地方继续执行。一旦异常被抛出,就表明错误无法挽回。
+
+### 3.3.2 恢复模型
+异常处理程序的工作是修正错误,然后重新尝试调用出问题的方法,并认为第二次能成功。对于恢复模型,通常希望异常被处理之后能继续执行程序。
+如果想要用 Java 实现类似恢复的行为
+- 那么在遇见错误时就不能抛出异常,而是调用方法来修正该错误
+- 或者把 try 块放在 while 循环里,这样就不断地进入 try 块,直到得到满意的结果
+
+#### 缺陷
+在过去,使用支持恢复模型异常处理的操作系统的程序员们最终还是转向使用类似“终止模型”的代码,并且忽略恢复行为。所以虽然恢复模型开始显得很吸引人,但不是很实用。其中的主要原因可能是它所导致的耦合:恢复性的处理程序需要了解异常抛出的地点,这势必要包含依赖于抛出位置的非通用性代码。这增加了代码编写和维护的困难,对于异常可能会从许多地方抛出的大型程序来说,更是如此。
+
+# 4 自定义异常
+Java 提供的异常体系不可能预见所有的希望加以报告的错误,所以可自己定义异常类。
+
+必须从已有的异常类继承,最好是选择意思相近的异常类继承(不过并不容易找)。建立新的异常类型最简单的方法就是让编译器为你产生
+## 无参构造器
+
+```java
+class SimpleException extends Exception {}
+
+public class InheritingExceptions {
+ public void f() throws SimpleException {
+ System.out.println(
+ "Throw SimpleException from f()");
+ throw new SimpleException();
+ }
+ public static void main(String[] args) {
+ InheritingExceptions sed =
+ new InheritingExceptions();
+ try {
+ sed.f();
+ } catch(SimpleException e) {
+ System.out.println("Caught it!");
+ }
+ }
+}
+```
+
+输出为:
+
+```
+Throw SimpleException from f()
+Caught it!
+```
+
+编译器创建了无参构造器,它将自动调用基类的无参构造器。**对异常来说,最重要的部分就是类名**。
+
+## 字符串参数的构造器
+
+```java
+class MyException extends Exception {
+ MyException() {}
+ MyException(String msg) { super(msg); }
+}
+public class FullConstructors {
+ public static void f() throws MyException {
+ System.out.println("Throwing MyException from f()");
+ throw new MyException();
+ }
+ public static void g() throws MyException {
+ System.out.println("Throwing MyException from g()");
+ throw new MyException("Originated in g()");
+ }
+ public static void main(String[] args) {
+ try {
+ f();
+ } catch(MyException e) {
+ e.printStackTrace(System.out);
+ }
+ try {
+ g();
+ } catch(MyException e) {
+ e.printStackTrace(System.out);
+ }
+ }
+}
+```
+
+输出为:
+
+```
+Throwing MyException from f()
+MyException
+ at FullConstructors.f(FullConstructors.java:11)
+ at
+FullConstructors.main(FullConstructors.java:19)
+Throwing MyException from g()
+MyException: Originated in g()
+ at FullConstructors.g(FullConstructors.java:15)
+ at
+FullConstructors.main(FullConstructors.java:24)
+```
+
+新增的代码非常简短:两个构造器定义了 MyException 类型对象的创建方式。对于第二个构造器,使用 super 关键字明确调用了其基类构造器,它接受一个字符串作为参数。
+
+在异常处理程序中,调用了在 Throwable 类声明(Exception 即从此类继承)的 printStackTrace() 方法。就像从输出中看到的,它将打印“从方法调用处直到异常抛出处”的方法调用序列。这里,信息被发送到了 System.out,并自动地被捕获和显示在输出中。但是,如果调用默认版本:
+
+```java
+e.printStackTrace();
+```
+
+信息就会被输出到标准错误流。
+
+## 4.1 记录日志
+- 使用 java.util.logging 工具将输出记录到日志
+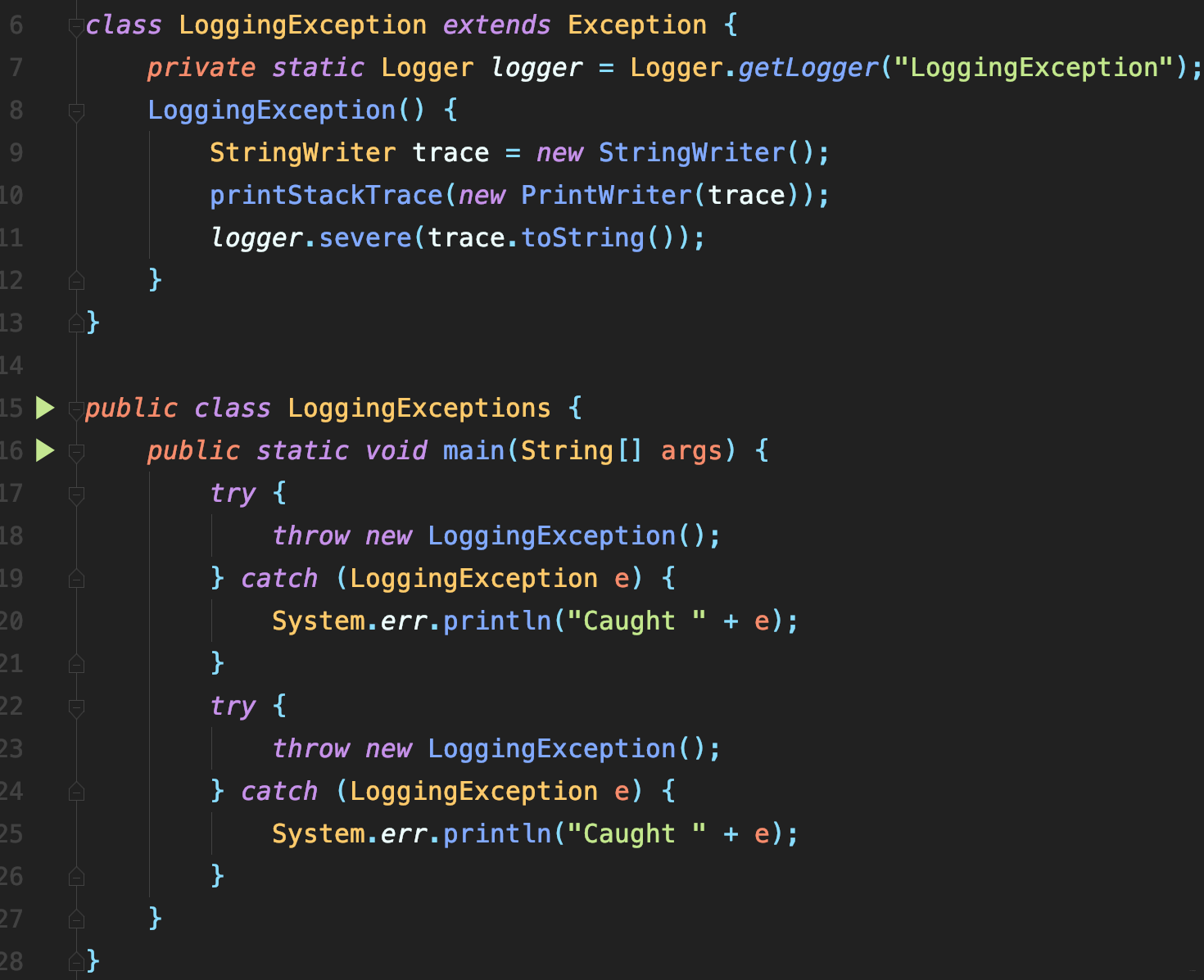
+- 输出
+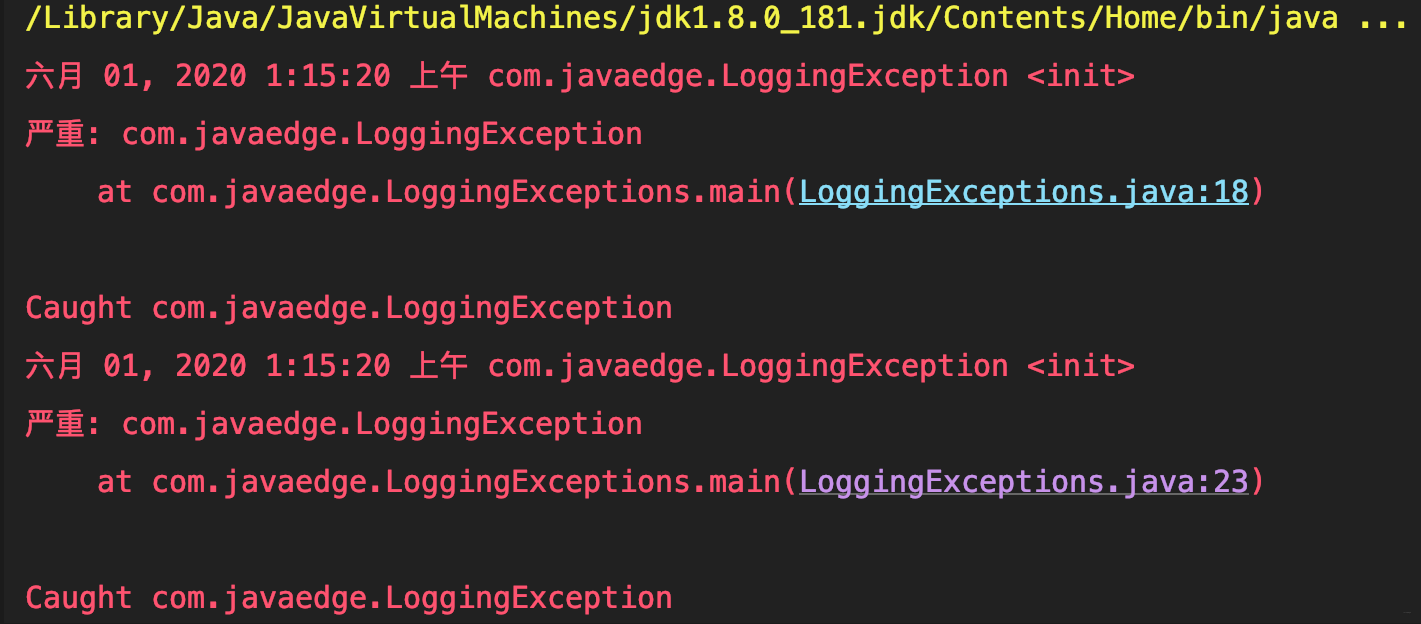
+
+直接调用与日志记录消息的级别相关联的方法,这里是 severe()。
+为了产生日志记录消息,要获取异常抛出处的栈轨迹,但是 printStackTrace() 不会默认地产生字符串。为了获取字符串,我们需要使用重载的 printStackTrace() 方法,它接受一个 java.io.PrintWriter 对象作为参数(PrintWriter 会在。如果我们将一个 java.io.StringWriter 对象传递给这个 PrintWriter 的构造器,那么通过调用 toString() 方法,就可以将输出抽取为一个 String。
+
+尽管由于 LoggingException 将所有记录日志的基础设施都构建在异常自身中,使得它所使用的方式非常方便,并因此不需要客户端程序员的干预就可以自动运行。
+
+### 捕获和记录其他人编写的异常
+必须在异常处理程序中生成日志消息
+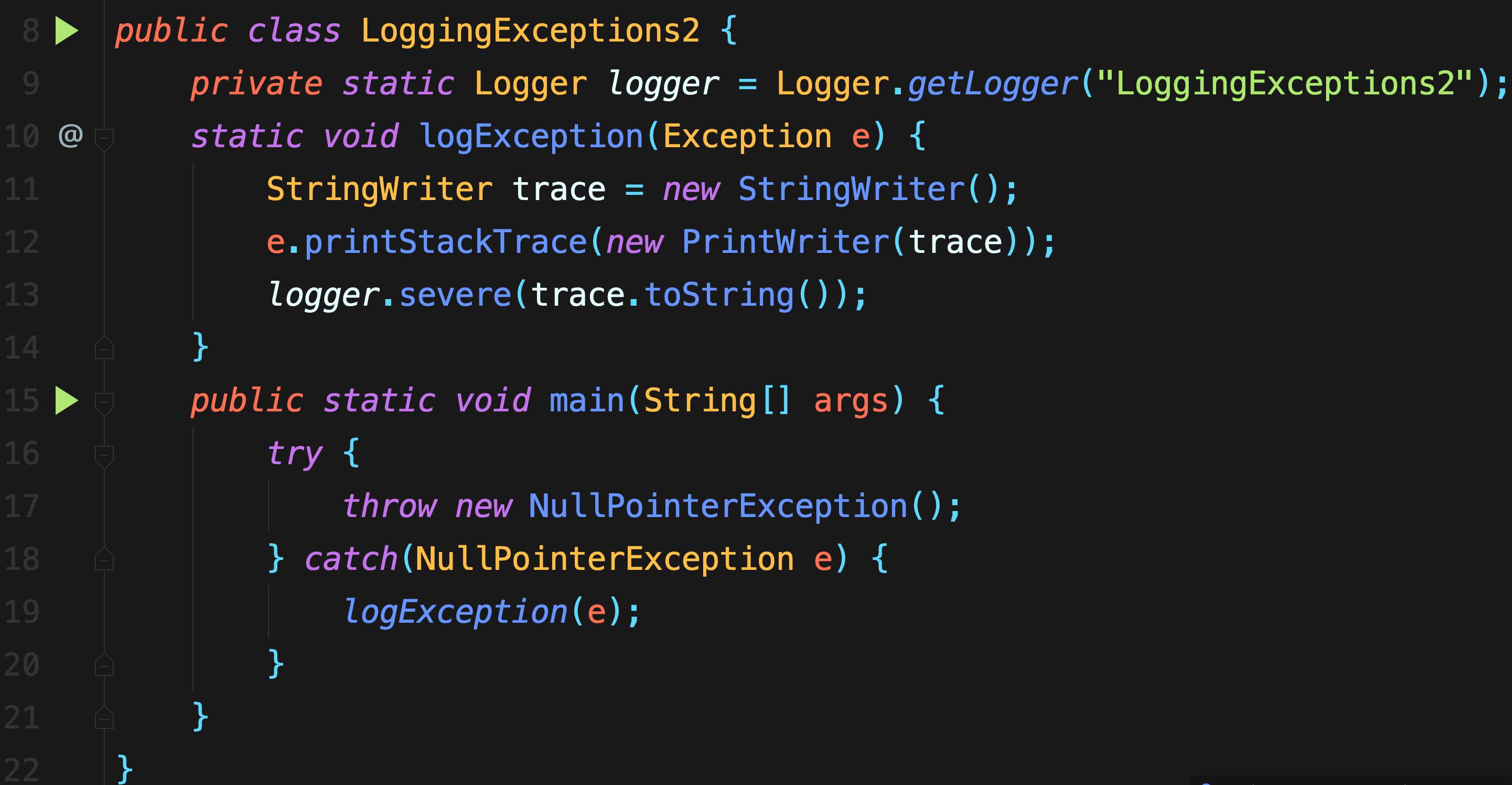
+- 结果
+
+
+### 加入额外构造器和成员
+
+```java
+class MyException2 extends Exception {
+ private int x;
+ MyException2() {}
+ MyException2(String msg) { super(msg); }
+ MyException2(String msg, int x) {
+ super(msg);
+ this.x = x;
+ }
+ public int val() { return x; }
+ @Override
+ public String getMessage() {
+ return "Detail Message: "+ x
+ + " "+ super.getMessage();
+ }
+}
+public class ExtraFeatures {
+ public static void f() throws MyException2 {
+ System.out.println(
+ "Throwing MyException2 from f()");
+ throw new MyException2();
+ }
+ public static void g() throws MyException2 {
+ System.out.println(
+ "Throwing MyException2 from g()");
+ throw new MyException2("Originated in g()");
+ }
+ public static void h() throws MyException2 {
+ System.out.println(
+ "Throwing MyException2 from h()");
+ throw new MyException2("Originated in h()", 47);
+ }
+ public static void main(String[] args) {
+ try {
+ f();
+ } catch(MyException2 e) {
+ e.printStackTrace(System.out);
+ }
+ try {
+ g();
+ } catch(MyException2 e) {
+ e.printStackTrace(System.out);
+ }
+ try {
+ h();
+ } catch(MyException2 e) {
+ e.printStackTrace(System.out);
+ System.out.println("e.val() = " + e.val());
+ }
+ }
+}
+```
+
+输出为:
+
+```
+Throwing MyException2 from f()
+MyException2: Detail Message: 0 null
+at ExtraFeatures.f(ExtraFeatures.java:24)
+at ExtraFeatures.main(ExtraFeatures.java:38)
+Throwing MyException2 from g()
+MyException2: Detail Message: 0 Originated in g()
+at ExtraFeatures.g(ExtraFeatures.java:29)
+at ExtraFeatures.main(ExtraFeatures.java:43)
+Throwing MyException2 from h()
+MyException2: Detail Message: 47 Originated in h()
+at ExtraFeatures.h(ExtraFeatures.java:34)
+at ExtraFeatures.main(ExtraFeatures.java:48)
+e.val() = 47
+```
+
+新的异常添加了字段 x 以及设定 x 值的构造器和读取数据的方法。此外,还覆盖了 Throwable.
+getMessage() 方法,以产生更详细的信息。对于异常类来说,getMessage() 方法有点类似于 toString() 方法。
+
+> 既然异常也是对象的一种,所以可以继续修改这个异常类,以得到更强的功能。但要记住,使用程序包的客户端程序员可能仅仅只是查看一下抛出的异常类型,其他的就不管了(大多数 Java 库里的异常都是这么用的),所以对异常所添加的其他功能也许根本用不上。
+
+# 5 异常声明
+Java 鼓励把方法可能会抛出的异常告知使用此方法的客户端程序员。这是种优雅的做法,它使得调用者能确切知道写什么样的代码可以捕获所有潜在的异常。
+
+当然,如果提供了源代码,客户端程序员可以在源代码中查找 throw 语句来获知相关信息,然而程序库通常并不与源代码一起发布。为了预防这样的问题,Java 提供了相应的语法(并强制使用这个语法),使你能以礼貌的方式告知客户端程序员某个方法可能会抛出的异常类型,然后客户端程序员就可以进行相应的处理。这就是异常说明,它属于方法声明的一部分,紧跟在形式参数列表之后。
+
+异常说明使用了附加的关键字 throws,后面接一个所有潜在异常类型的列表,所以方法定义可能看起来像这样:
+```java
+void f() throws TooBig, TooSmall, DivZero { // ...
+```
+但要是这样写:
+```java
+void f() { // ...
+```
+就表示此方法不会抛任何异常。
+
+代码必须与异常说明保持一致。如果方法里的代码产生了异常却没有进行处理,编译器会发现这个问题并提醒你:
+- 要么处理这个异常
+- 要么就在异常说明中表明此方法将产生异常
+
+通过这种自顶向下强制执行的异常说明机制,Java 在编译时就可以保证一定的异常正确性。
+
+## “作弊”的地方
+可以声明方法将抛异常,实际上却不抛出。编译器相信了这个声明,并强制此方法的用户像真的抛出异常那样使用这个方法。这样做的好处是,为异常先占个位子,以后就可以抛出这种异常而不用修改已有的代码。在定义抽象基类和接口时这种能力很重要,这样派生类或接口实现就能够抛出这些预先声明的异常。
+
+**这种在编译时被强制检查的异常称为被检查的异常。**
+
+# 6 捕获所有异常
+## 6.1 如何使用 Exception 类型
+可以只写一个异常处理程序来捕获所有类型的异常。
+通过捕获异常类型的基类 Exception 即可:
+```java
+catch(Exception e) {
+ System.out.println("Caught an exception");
+}
+```
+### 最佳实践
+它会捕获所有异常,所以最好把它**放在处理程序列表的末尾**,以防它抢在其他处理程序之前先把异常捕获了。
+
+### 从 Throwable 继承的方法
+因为 Exception 是与编程有关的所有异常类的基类,不含太多具体信息,但可以调用它从其基类 Throwable 继承的方法:
+- String getMessage()
+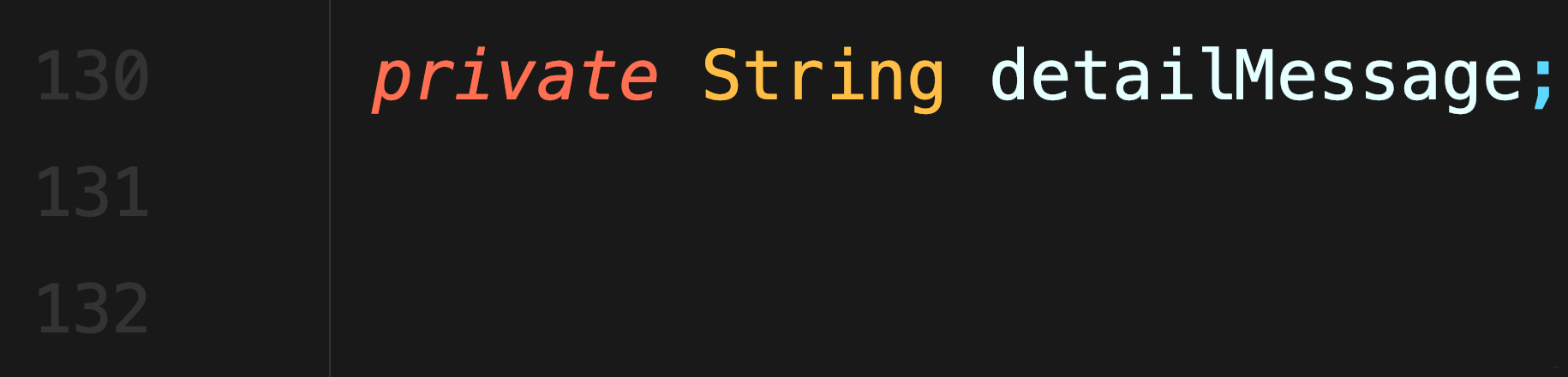
+
+
+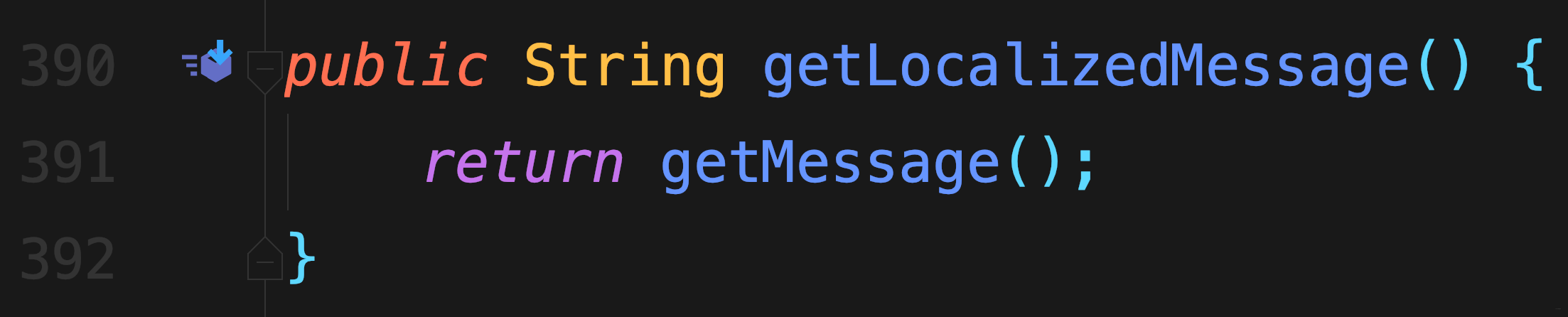
+用来获取详细信息,或用本地语言表示的详细信息。
+
+```java
+String toString()
+```
+
+返回对 Throwable 的简单描述,要是有详细信息的话,也会把它包含在内。
+
+```java
+void printStackTrace()
+void printStackTrace(PrintStream)
+void printStackTrace(java.io.PrintWriter)
+```
+
+打印 Throwable 和 Throwable 的调用栈轨迹。调用栈显示了“把你带到异常抛出地点”的方法调用序列。其中第一个版本输出到标准错误,后两个版本允许选择要输出的流。
+
+```java
+Throwable fillInStackTrace()
+```
+
+用于在 Throwable 对象的内部记录栈帧的当前状态。这在程序重新抛出错误或异常时很有用。
+
+此外,也可以使用 Throwable 从其基类 Object(也是所有类的基类)继承的方法。对于异常来说,getClass)也许是个很好用的方法,它将返回一个表示此对象类型的对象。然后可以使用 getName)方法查询这个 Class 对象包含包信息的名称,或者使用只产生类名称的 getSimpleName() 方法。
+
+### 使用案例
+
+```java
+public class ExceptionMethods {
+ public static void main(String[] args) {
+ try {
+ throw new Exception("My Exception");
+ } catch(Exception e) {
+ System.out.println("Caught Exception");
+ System.out.println(
+ "getMessage():" + e.getMessage());
+ System.out.println("getLocalizedMessage():" +
+ e.getLocalizedMessage());
+ System.out.println("toString():" + e);
+ System.out.println("printStackTrace():");
+ e.printStackTrace(System.out);
+ }
+ }
+}
+```
+
+输出为:
+
+```java
+Caught Exception
+getMessage():My Exception
+getLocalizedMessage():My Exception
+toString():java.lang.Exception: My Exception
+printStackTrace():
+java.lang.Exception: My Exception
+at
+ExceptionMethods.main(ExceptionMethods.java:7)
+```
+
+可以发现每个方法都比前一个提供了更多的信息一一实际上它们每一个都是前一个的超集。
+
+## 多重捕获
+如果有一组具有相同基类的异常,你想使用同一方式进行捕获,那你直接 catch 它们的基类型。但是,如果这些异常没有共同的基类型,在 Java 7 之前,你必须为每一个类型编写一个 catch:
+
+```java
+// exceptions/SameHandler.java
+class EBase1 extends Exception {}
+class Except1 extends EBase1 {}
+class EBase2 extends Exception {}
+class Except2 extends EBase2 {}
+class EBase3 extends Exception {}
+class Except3 extends EBase3 {}
+class EBase4 extends Exception {}
+class Except4 extends EBase4 {}
+
+public class SameHandler {
+ void x() throws Except1, Except2, Except3, Except4 {}
+ void process() {}
+ void f() {
+ try {
+ x();
+ } catch(Except1 e) {
+ process();
+ } catch(Except2 e) {
+ process();
+ } catch(Except3 e) {
+ process();
+ } catch(Except4 e) {
+ process();
+ }
+ }
+}
+```
+
+通过 Java 7 的多重捕获机制,你可以使用“或”将不同类型的异常组合起来,只需要一行 catch 语句:
+
+```java
+// exceptions/MultiCatch.java
+public class MultiCatch {
+ void x() throws Except1, Except2, Except3, Except4 {}
+ void process() {}
+ void f() {
+ try {
+ x();
+
+ } catch(Except1 | Except2 | Except3 | Except4 e) {
+ process();
+ }
+ }
+}
+```
+
+或者以其他的组合方式:
+
+```java
+// exceptions/MultiCatch2.java
+public class MultiCatch2 {
+ void x() throws Except1, Except2, Except3, Except4 {}
+ void process1() {}
+ void process2() {}
+ void f() {
+ try {
+ x();
+ } catch(Except1 | Except2 e) {
+ process1();
+ } catch(Except3 | Except4 e) {
+ process2();
+ }
+ }
+}
+```
+
+这对书写更整洁的代码很有帮助。
+
+## 栈轨迹
+
+printStackTrace() 方法所提供的信息可以通过 getStackTrace() 方法来直接访问,这个方法将返回一个由栈轨迹中的元素所构成的数组,其中每一个元素都表示栈中的一桢。元素 0 是栈顶元素,并且是调用序列中的最后一个方法调用(这个 Throwable 被创建和抛出之处)。数组中的最后一个元素和栈底是调用序列中的第一个方法调用。下面的程序是一个简单的演示示例:
+
+```java
+// exceptions/WhoCalled.java
+// Programmatic access to stack trace information
+public class WhoCalled {
+ static void f() {
+// Generate an exception to fill in the stack trace
+ try {
+ throw new Exception();
+ } catch(Exception e) {
+ for(StackTraceElement ste : e.getStackTrace())
+ System.out.println(ste.getMethodName());
+ }
+ }
+ static void g() { f(); }
+ static void h() { g(); }
+ public static void main(String[] args) {
+ f();
+ System.out.println("*******");
+ g();
+ System.out.println("*******");
+ h();
+ }
+}
+```
+
+输出为:
+
+```
+f
+main
+*******
+f
+g
+main
+*******
+f
+g
+h
+main
+```
+
+这里,我们只打印了方法名,但实际上还可以打印整个 StackTraceElement,它包含其他附加的信息。
+
+## 重新抛出异常
+
+有时希望把刚捕获的异常重新抛出,尤其是在使用 Exception 捕获所有异常的时候。既然已经得到了对当前异常对象的引用,可以直接把它重新抛出:
+
+```java
+catch(Exception e) {
+ System.out.println("An exception was thrown");
+ throw e;
+}
+```
+
+重抛异常会把异常抛给上一级环境中的异常处理程序,同一个 `try` 块的后续 `catch` 子句将被忽略。此外,异常对象的所有信息都得以保持,所以较高一级环境中捕获此异常的处理程序可以从这个异常对象中得到所有信息。
+
+若只是把当前异常对象重新抛出,那么
+- `printStackTrace()` 方法显示的将是原来异常抛出点的调用栈信息,而非重新抛出点的信息。
+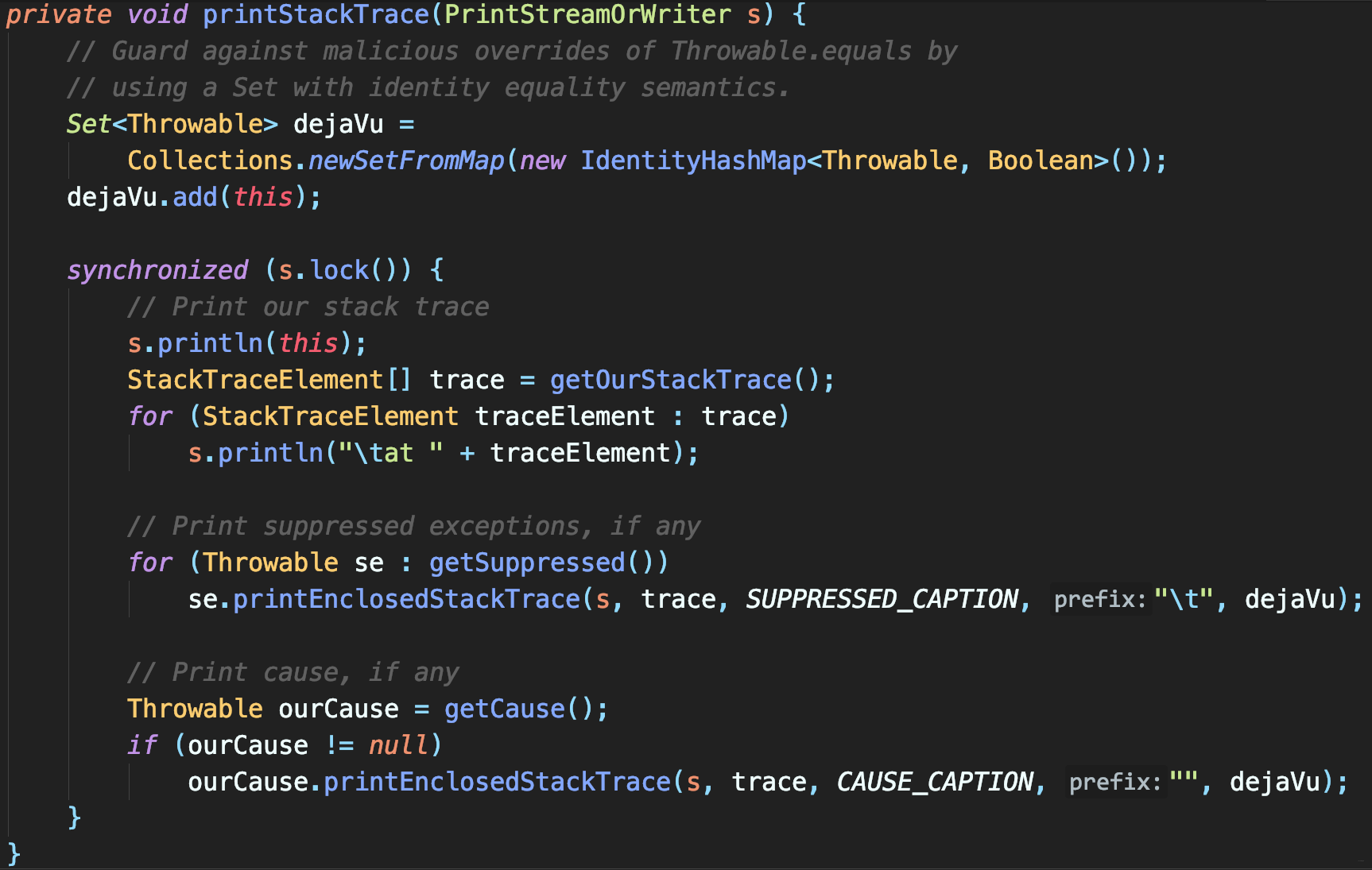
+要想更新该信息,可调用 `filInStackTrace()` 方法,这将返回一个 Throwable 对象,它是通过把当前调用栈信息填入原来那个异常对象而建立的。
+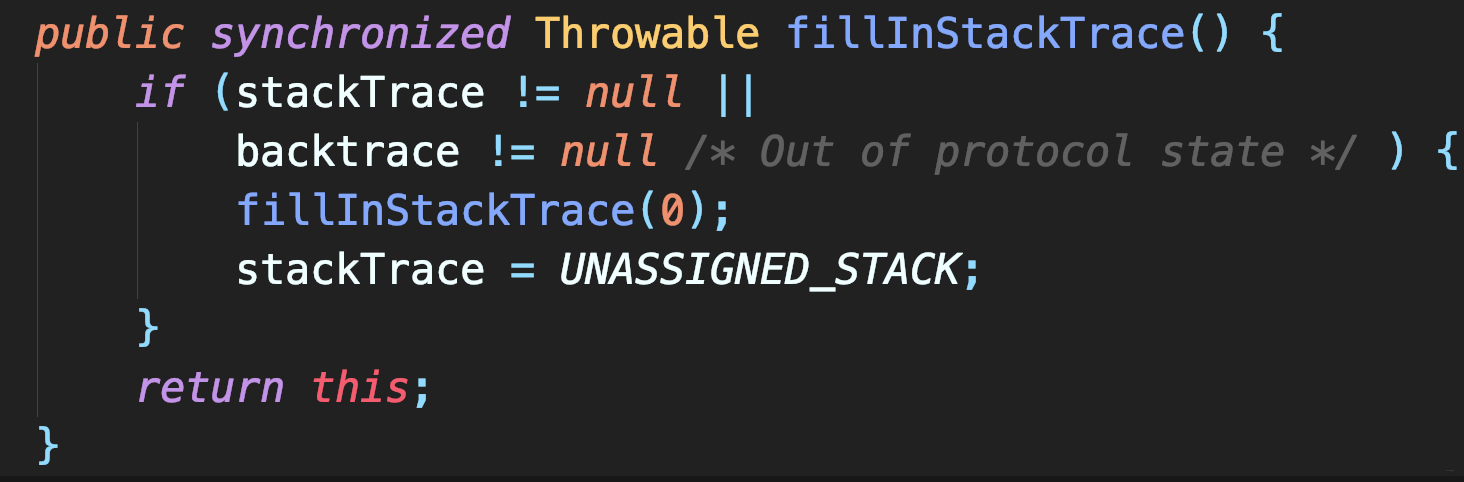
+
+就像这样:
+
+```java
+public class Rethrowing {
+ public static void f() throws Exception {
+ System.out.println(
+ "originating the exception in f()");
+ throw new Exception("thrown from f()");
+ }
+ public static void g() throws Exception {
+ try {
+ f();
+ } catch(Exception e) {
+ System.out.println(
+ "Inside g(), e.printStackTrace()");
+ e.printStackTrace(System.out);
+ throw e;
+ }
+ }
+ public static void h() throws Exception {
+ try {
+ f();
+ } catch(Exception e) {
+ System.out.println(
+ "Inside h(), e.printStackTrace()");
+ e.printStackTrace(System.out);
+ throw (Exception)e.fillInStackTrace();
+ }
+ }
+ public static void main(String[] args) {
+ try {
+ g();
+ } catch(Exception e) {
+ System.out.println("main: printStackTrace()");
+ e.printStackTrace(System.out);
+ }
+ try {
+ h();
+ } catch(Exception e) {
+ System.out.println("main: printStackTrace()");
+ e.printStackTrace(System.out);
+ }
+ }
+}
+```
+
+输出为:
+
+```java
+originating the exception in f()
+Inside g(), e.printStackTrace()
+java.lang.Exception: thrown from f()
+at Rethrowing.f(Rethrowing.java:8)
+at Rethrowing.g(Rethrowing.java:12)
+at Rethrowing.main(Rethrowing.java:32)
+main: printStackTrace()
+java.lang.Exception: thrown from f()
+at Rethrowing.f(Rethrowing.java:8)
+at Rethrowing.g(Rethrowing.java:12)
+at Rethrowing.main(Rethrowing.java:32)
+originating the exception in f()
+Inside h(), e.printStackTrace()
+java.lang.Exception: thrown from f()
+at Rethrowing.f(Rethrowing.java:8)
+at Rethrowing.h(Rethrowing.java:22)
+at Rethrowing.main(Rethrowing.java:38)
+main: printStackTrace()
+java.lang.Exception: thrown from f()
+at Rethrowing.h(Rethrowing.java:27)
+at Rethrowing.main(Rethrowing.java:38)
+```
+
+调用 `fillInStackTrace` 的那一行就成了异常的新发生地。
+
+有可能在捕获异常之后抛出另一种异常。这么做的话,得到的效果类似于使用 filInStackTrace(),有关原来异常发生点的信息会丢失,剩下的是与新的抛出点有关的信息:
+
+```java
+// exceptions/RethrowNew.java
+// Rethrow a different object from the one you caught
+class OneException extends Exception {
+ OneException(String s) { super(s); }
+}
+class TwoException extends Exception {
+ TwoException(String s) { super(s); }
+}
+public class RethrowNew {
+ public static void f() throws OneException {
+ System.out.println(
+ "originating the exception in f()");
+ throw new OneException("thrown from f()");
+ }
+ public static void main(String[] args) {
+ try {
+ try {
+ f();
+ } catch(OneException e) {
+ System.out.println(
+ "Caught in inner try, e.printStackTrace()");
+ e.printStackTrace(System.out);
+ throw new TwoException("from inner try");
+ }
+ } catch(TwoException e) {
+ System.out.println(
+ "Caught in outer try, e.printStackTrace()");
+ e.printStackTrace(System.out);
+ }
+ }
+}
+```
+
+输出为:
+
+```java
+originating the exception in f()
+Caught in inner try, e.printStackTrace()
+OneException: thrown from f()
+at RethrowNew.f(RethrowNew.java:16)
+at RethrowNew.main(RethrowNew.java:21)
+Caught in outer try, e.printStackTrace()
+TwoException: from inner try
+at RethrowNew.main(RethrowNew.java:26)
+```
+
+最后那个异常仅知道自己来自 main(),而对 f() 一无所知。
+
+永远不必为清理前一个异常对象而担心,或者说为异常对象的清理而担心。它们都是用 new 在堆上创建的对象,所以垃圾回收器会自动把它们清理掉。
+
+### 精准的重新抛出异常
+
+在 Java 7 前,若遇到异常,则只能重新抛出该类型的异常。这导致在 Java 7 中修复的代码不精确。所以在 Java 7 前,这无法编译:
+
+```java
+class BaseException extends Exception {}
+class DerivedException extends BaseException {}
+
+public class PreciseRethrow {
+ void catcher() throws DerivedException {
+ try {
+ throw new DerivedException();
+ } catch(BaseException e) {
+ throw e;
+ }
+ }
+}
+```
+
+因为 catch 捕获了一个 BaseException,编译器强迫你声明 catcher() 抛出 BaseException,即使它实际上抛出了更具体的 DerivedException。从 Java 7 开始,这段代码就可以编译,这是一个很小但很有用的修复。
+
+### 异常链
+想要在捕获一个异常后抛出另一个异常,并且希望把原始异常的信息保存下来,这被称为异常链。
+JDK1.4 前,程序员必须自己编写代码保存原始异常的信息。现在所有 Throwable 的子类在构造器中都可接收一个 cause 对象作为参数,表示原始异常,这样通过把原始异常传递给新的异常,使得即使在当前位置创建并抛出了新的异常,也能通过这个异常链追踪到异常最初发生的位置。
+
+在 Throwable 的子类中,只有三种基本的异常类提供了带 cause 参数的构造器:
+- Error(用于 Java 虚拟机报告系统错误)
+- Exception
+- RuntimeException
+
+如果要把其他类型的异常链接起来,应该使用 initCause() 而非构造器。
+
+### 运行时动态地向 DymamicFields 对象添加字段
+```java
+// A Class that dynamically adds fields to itself to
+// demonstrate exception chaining
+class DynamicFieldsException extends Exception {}
+public class DynamicFields {
+ private Object[][] fields;
+ public DynamicFields(int initialSize) {
+ fields = new Object[initialSize][2];
+ for(int i = 0; i < initialSize; i++)
+ fields[i] = new Object[] { null, null };
+ }
+ @Override
+ public String toString() {
+ StringBuilder result = new StringBuilder();
+ for(Object[] obj : fields) {
+ result.append(obj[0]);
+ result.append(": ");
+ result.append(obj[1]);
+ result.append("\n");
+ }
+ return result.toString();
+ }
+ private int hasField(String id) {
+ for(int i = 0; i < fields.length; i++)
+ if(id.equals(fields[i][0]))
+ return i;
+ return -1;
+ }
+ private int getFieldNumber(String id)
+ throws NoSuchFieldException {
+ int fieldNum = hasField(id);
+ if(fieldNum == -1)
+ throw new NoSuchFieldException();
+ return fieldNum;
+ }
+ private int makeField(String id) {
+ for(int i = 0; i < fields.length; i++)
+ if(fields[i][0] == null) {
+ fields[i][0] = id;
+ return i;
+ }
+// No empty fields. Add one:
+ Object[][] tmp = new Object[fields.length + 1][2];
+ for(int i = 0; i < fields.length; i++)
+ tmp[i] = fields[i];
+ for(int i = fields.length; i < tmp.length; i++)
+ tmp[i] = new Object[] { null, null };
+ fields = tmp;
+// Recursive call with expanded fields:
+ return makeField(id);
+ }
+ public Object
+ getField(String id) throws NoSuchFieldException {
+ return fields[getFieldNumber(id)][1];
+ }
+ public Object setField(String id, Object value)
+ throws DynamicFieldsException {
+ if(value == null) {
+// Most exceptions don't have a "cause"
+// constructor. In these cases you must use
+// initCause(), available in all
+// Throwable subclasses.
+ DynamicFieldsException dfe =
+ new DynamicFieldsException();
+ dfe.initCause(new NullPointerException());
+ throw dfe;
+ }
+ int fieldNumber = hasField(id);
+ if(fieldNumber == -1)
+ fieldNumber = makeField(id);
+ Object result = null;
+ try {
+ result = getField(id); // Get old value
+ } catch(NoSuchFieldException e) {
+// Use constructor that takes "cause":
+ throw new RuntimeException(e);
+ }
+ fields[fieldNumber][1] = value;
+ return result;
+ }
+ public static void main(String[] args) {
+ DynamicFields df = new DynamicFields(3);
+ System.out.println(df);
+ try {
+ df.setField("d", "A value for d");
+ df.setField("number", 47);
+ df.setField("number2", 48);
+ System.out.println(df);
+ df.setField("d", "A new value for d");
+ df.setField("number3", 11);
+ System.out.println("df: " + df);
+ System.out.println("df.getField(\"d\") : "
+ + df.getField("d"));
+ Object field =
+ df.setField("d", null); // Exception
+ } catch(NoSuchFieldException |
+ DynamicFieldsException e) {
+ e.printStackTrace(System.out);
+ }
+ }
+}
+```
+
+输出为:
+
+```java
+null: null
+null: null
+null: null
+d: A value for d
+number: 47
+number2: 48
+df: d: A new value for d
+number: 47
+number2: 48
+number3: 11
+df.getField("d") : A new value for d
+DynamicFieldsException
+at
+DynamicFields.setField(DynamicFields.java:65)
+at DynamicFields.main(DynamicFields.java:97)
+Caused by: java.lang.NullPointerException
+at
+DynamicFields.setField(DynamicFields.java:67)
+... 1 more
+```
+
+每个 DynamicFields 对象都含有一个数组,其元素是“成对的对象”。第一个对象表示字段标识符(一个字符串),第二个表示字段值,值的类型可以是除基本类型外的任意类型。当创建对象的时候,要合理估计一下需要多少字段。当调用 setField() 方法的时候,它将试图通过标识修改已有字段值,否则就建一个新的字段,并把值放入。如果空间不够了,将建立一个更长的数组,并把原来数组的元素复制进去。如果你试图为字段设置一个空值,将抛出一个 DynamicFieldsException 异常,它是通过使用 initCause() 方法把 NullPointerException 对象插入而建立的。
+
+至于返回值,setField() 将用 getField() 方法把此位置的旧值取出,这个操作可能会抛出 NoSuchFieldException 异常。如果客户端程序员调用了 getField() 方法,那么他就有责任处理这个可能抛出的 NoSuchFieldException 异常,但如果异常是从 setField0 方法抛出,这种情况将被视为编程错误,所以就使用接受 cause 参数的构造器把 NoSuchFieldException 异常转换为 RuntimeException 异常。
+
+主方法中的 catch 子句看起来不同 - 它使用相同的子句处理两种不同类型的异常,并结合“或(|)”符号。此 Java 7 功能有助于减少代码重复,并使你更容易指定要捕获的确切类型,而不是简单地捕获基本类型。你可以通过这种方式组合多种异常类型。
+
+# Java 标准异常
+Throwable 这个 Java 类被用来表示任何可以作为异常被抛出的类。Throwable 对象可分为两种类型(指从 Throwable 继承而得到的类型):Error 用来表示编译时和系统错误(除特殊情况外,一般不用你关心);Exception 是可以被抛出的基本类型,在 Java 类库、用户方法以及运行时故障中都可能抛出 Exception 型异常。所以 Java 程序员关心的基类型通常是 Exception。要想对异常有全面的了解,最好去浏览一下 HTML 格式的 Java 文档(可以从 java.sun.com 下载)。为了对不同的异常有个感性的认识,这么做是值得的。但很快你就会发现,这些异常除了名称外其实都差不多。同时,Java 中异常的数目在持续增加,所以在书中简单罗列它们毫无意义。所使用的第三方类库也可能会有自己的异常。对异常来说,关键是理解概念以及如何使用。
+
+异常的基本的概念是用名称代表发生的问题,并且异常的名称应该可以望文知意。异常并非全是在 java.lang 包里定义的;有些异常是用来支持其他像 util、net 和 io 这样的程序包,这些异常可以通过它们的完整名称或者从它们的父类中看出端倪。比如,所有的输入/输出异常都是从 java.io.IOException 继承而来的。
+
+### 特例:RuntimeException
+```java
+if(t == null)
+ throw new NullPointerException();
+```
+如果必须对传递给方法的每个引用都检查其是否为 null(因为无法确定调用者是否传入了非法引用),这听起来着实吓人。幸运的是,这不必由你亲自来做,它属于 Java 的标准运行时检测的一部分。如果对 null 引用进行调用,Java 会自动抛出 NullPointerException 异常,所以上述代码是多余的。
+
+属于运行时异常的类型有很多,它们会自动被 JVM 抛出,所以不必在异常说明中列出来。这些异常都是继承自 RuntimeException 。这构成了一组具有相同特征和行为的异常类型。并且,也不再需要在异常说明中声明方法将抛出 RuntimeException 类型的异常(或者任何从 RuntimeException 继承的异常),它们也被称为“不受检查异常”。这种异常属于错误,将被自动捕获,就不用你亲自动手了。要是自己去检查 RuntimeException 的话,代码就显得太混乱了。不过尽管通常不用捕获 RuntimeException 异常,但还是可以在代码中抛出 RuntimeException 类型的异常。
+
+RuntimeException 代表的是编程错误:
+1. 无法预料的错误
+比如从你控制范围之外传递进来的 null 引用
+2. 作为程序员,应该在代码中进行检查错误
+比如 ArrayIndexOutOfBoundsException,就得注意一下数组大小。在一个地方发生的异常,常常会在另一个地方导致错误。
+
+在这些情况下使用异常很有好处,它们能给调试带来便利。
+如果不捕获这种异常会发生什么事?
+因为编译器没有在这个问题上对异常说明进行强制检查,RuntimeException 类型的异常也许会穿越所有的执行路径直达 main() 方法,而不会被捕获。
+要明白到底发生了什么,可以试试下面的例子:
+```java
+public class NeverCaught {
+ static void f() {
+ throw new RuntimeException("From f()");
+ }
+ static void g() {
+ f();
+ }
+ public static void main(String[] args) {
+ g();
+ }
+}
+```
+
+输出结果为:
+
+```java
+___[ Error Output ]___
+Exception in thread "main" java.lang.RuntimeException:
+From f()
+at NeverCaught.f(NeverCaught.java:7)
+at NeverCaught.g(NeverCaught.java:10)
+at NeverCaught.main(NeverCaught.java:13)
+```
+
+如果 RuntimeException 没有被捕获而直达 main(),那么在程序退出前将调用异常的 printStackTrace() 方法。
+
+你会发现,RuntimeException 是个特例。对于这种异常,编译器无需异常说明,其输出被报告给了 System.err。
+
+只能在代码中忽略 RuntimeException 类型的异常,因为所有受检查类型异常的处理都是由编译器强制实施的。
+
+不应把 Java 的异常处理机制当成是单一用途的工具。它被设计用来处理一些烦人的运行时错误,这些错误往往是由代码控制能力之外的因素导致的;然而,它对于发现某些编译器无法检测到的编程错误,也是非常重要的。
+
+## 使用 finally 进行清理
+
+有一些代码片段,可能会希望无论 try 块中的异常是否抛出,它们都能得到执行。这通常适用于内存回收之外的情况(因为回收由垃圾回收器完成),为了达到这个效果,可以在异常处理程序后面加上 finally 子句。完整的异常处理程序看起来像这样:
+
+```java
+try {
+// The guarded region: Dangerous activities
+// that might throw A, B, or C
+} catch(A a1) {
+// Handler for situation A
+} catch(B b1) {
+// Handler for situation B
+} catch(C c1) {
+// Handler for situation C
+} finally {
+// Activities that happen every time
+}
+```
+
+为了证明 finally 子句总能运行,可以试试下面这个程序:
+
+```java
+// exceptions/FinallyWorks.java
+// The finally clause is always executed
+class ThreeException extends Exception {}
+public class FinallyWorks {
+ static int count = 0;
+ public static void main(String[] args) {
+ while(true) {
+ try {
+ // Post-increment is zero first time:
+ if(count++ == 0)
+ throw new ThreeException();
+ System.out.println("No exception");
+ } catch(ThreeException e) {
+ System.out.println("ThreeException");
+ } finally {
+ System.out.println("In finally clause");
+ if(count == 2) break; // out of "while"
+ }
+ }
+ }
+}
+```
+
+输出为:
+
+```
+ThreeException
+In finally clause
+No exception
+In finally clause
+```
+
+可以从输出中发现,无论异常是否被抛出,finally 子句总能被执行。这个程序也给了我们一些思路,当 Java 中的异常不允许我们回到异常抛出的地点时,那么该如何应对呢?如果把 try 块放在循环里,就建立了一个“程序继续执行之前必须要达到”的条件。还可以加入一个 static 类型的计数器或者别的装置,使循环在放弃以前能尝试一定的次数。这将使程序的健壮性更上一个台阶。
+
+### finally 用来做什么?
+
+对于没有垃圾回收和析构函数自动调用机制的语言来说,finally 非常重要。它能使程序员保证:无论 try 块里发生了什么,内存总能得到释放。但 Java 有垃圾回收机制,所以内存释放不再是问题。而且,Java 也没有析构函数可供调用。那么,Java 在什么情况下才能用到 finally 呢?
+
+当要把除内存之外的资源恢复到它们的初始状态时,就要用到 finally 子句。这种需要清理的资源包括:已经打开的文件或网络连接,在屏幕上画的图形,甚至可以是外部世界的某个开关,如下面例子所示:
+
+```java
+// exceptions/Switch.java
+public class Switch {
+ private boolean state = false;
+ public boolean read() { return state; }
+ public void on() {
+ state = true;
+ System.out.println(this);
+ }
+ public void off() {
+ state = false;
+ System.out.println(this);
+ }
+ @Override
+ public String toString() {
+ return state ? "on" : "off";
+ }
+}
+// exceptions/OnOffException1.java
+public class OnOffException1 extends Exception {}
+// exceptions/OnOffException2.java
+public class OnOffException2 extends Exception {}
+// exceptions/OnOffSwitch.java
+// Why use finally?
+public class OnOffSwitch {
+ private static Switch sw = new Switch();
+ public static void f()
+ throws OnOffException1, OnOffException2 {}
+ public static void main(String[] args) {
+ try {
+ sw.on();
+ // Code that can throw exceptions...
+ f();
+ sw.off();
+ } catch(OnOffException1 e) {
+ System.out.println("OnOffException1");
+ sw.off();
+ } catch(OnOffException2 e) {
+ System.out.println("OnOffException2");
+ sw.off();
+ }
+ }
+}
+```
+
+输出为:
+
+```
+on
+off
+```
+
+程序的目的是要确保 main() 结束的时候开关必须是关闭的,所以在每个 try 块和异常处理程序的末尾都加入了对 sw.offo 方法的调用。但也可能有这种情况:异常被抛出,但没被处理程序捕获,这时 sw.off() 就得不到调用。但是有了 finally,只要把 try 块中的清理代码移放在一处即可:
+
+```java
+// exceptions/WithFinally.java
+// Finally Guarantees cleanup
+public class WithFinally {
+ static Switch sw = new Switch();
+ public static void main(String[] args) {
+ try {
+ sw.on();
+ // Code that can throw exceptions...
+ OnOffSwitch.f();
+ } catch(OnOffException1 e) {
+ System.out.println("OnOffException1");
+ } catch(OnOffException2 e) {
+ System.out.println("OnOffException2");
+ } finally {
+ sw.off();
+ }
+ }
+}
+```
+
+输出为:
+
+```java
+on
+off
+```
+
+这里 sw.off() 被移到一处,并且保证在任何情况下都能得到执行。
+
+甚至在异常没有被当前的异常处理程序捕获的情况下,异常处理机制也会在跳到更高一层的异常处理程序之前,执行 finally 子句:
+
+```java
+// exceptions/AlwaysFinally.java
+// Finally is always executed
+class FourException extends Exception {}
+public class AlwaysFinally {
+ public static void main(String[] args) {
+ System.out.println("Entering first try block");
+ try {
+ System.out.println("Entering second try block");
+ try {
+ throw new FourException();
+ } finally {
+ System.out.println("finally in 2nd try block");
+ }
+ } catch(FourException e) {
+ System.out.println(
+ "Caught FourException in 1st try block");
+ } finally {
+ System.out.println("finally in 1st try block");
+ }
+ }
+}
+```
+
+输出为:
+
+```java
+Entering first try block
+Entering second try block
+finally in 2nd try block
+Caught FourException in 1st try block
+finally in 1st try block
+```
+
+当涉及 break 和 continue 语句的时候,finally 子句也会得到执行。请注意,如果把 finally 子句和带标签的 break 及 continue 配合使用,在 Java 里就没必要使用 goto 语句了。
+
+### 在 return 中使用 finally
+
+因为 finally 子句总是会执行,所以可以从一个方法内的多个点返回,仍然能保证重要的清理工作会执行:
+
+```java
+// exceptions/MultipleReturns.java
+public class MultipleReturns {
+ public static void f(int i) {
+ System.out.println(
+ "Initialization that requires cleanup");
+ try {
+ System.out.println("Point 1");
+ if(i == 1) return;
+ System.out.println("Point 2");
+ if(i == 2) return;
+ System.out.println("Point 3");
+ if(i == 3) return;
+ System.out.println("End");
+ return;
+ } finally {
+ System.out.println("Performing cleanup");
+ }
+ }
+ public static void main(String[] args) {
+ for(int i = 1; i <= 4; i++)
+ f(i);
+ }
+}
+```
+
+输出为:
+
+```java
+Initialization that requires cleanup
+Point 1
+Performing cleanup
+Initialization that requires cleanup
+Point 1
+Point 2
+Performing cleanup
+Initialization that requires cleanup
+Point 1
+Point 2
+Point 3
+Performing cleanup
+Initialization that requires cleanup
+Point 1
+Point 2
+Point 3
+End
+Performing cleanup
+```
+
+从输出中可以看出,从何处返回无关紧要,finally 子句永远会执行。
+
+### 缺憾:异常丢失
+
+遗憾的是,Java 的异常实现也有瑕疵。异常作为程序出错的标志,决不应该被忽略,但它还是有可能被轻易地忽略。用某些特殊的方式使用 finally 子句,就会发生这种情况:
+
+```java
+// exceptions/LostMessage.java
+// How an exception can be lost
+class VeryImportantException extends Exception {
+ @Override
+ public String toString() {
+ return "A very important exception!";
+ }
+}
+class HoHumException extends Exception {
+ @Override
+ public String toString() {
+ return "A trivial exception";
+ }
+}
+public class LostMessage {
+ void f() throws VeryImportantException {
+ throw new VeryImportantException();
+ }
+ void dispose() throws HoHumException {
+ throw new HoHumException();
+ }
+ public static void main(String[] args) {
+ try {
+ LostMessage lm = new LostMessage();
+ try {
+ lm.f();
+ } finally {
+ lm.dispose();
+ }
+ } catch(VeryImportantException | HoHumException e) {
+ System.out.println(e);
+ }
+ }
+}
+```
+
+输出为:
+
+```
+A trivial exception
+```
+
+从输出中可以看到,VeryImportantException 不见了,它被 finally 子句里的 HoHumException 所取代。这是相当严重的缺陷,因为异常可能会以一种比前面例子所示更微妙和难以察党的方式完全丢失。相比之下,C++把“前一个异常还没处理就抛出下一个异常”的情形看成是糟糕的编程错误。也许在 Java 的未来版本中会修正这个问题(另一方面,要把所有抛出异常的方法,如上例中的 dispose() 方法,全部打包放到 try-catch 子句里面)。
+
+一种更加简单的丢失异常的方式是从 finally 子句中返回:
+
+```java
+// exceptions/ExceptionSilencer.java
+public class ExceptionSilencer {
+ public static void main(String[] args) {
+ try {
+ throw new RuntimeException();
+ } finally {
+ // Using 'return' inside the finally block
+ // will silence any thrown exception.
+ return;
+ }
+ }
+}
+```
+
+如果运行这个程序,就会看到即使方法里抛出了异常,它也不会产生任何输出。
+
+
+
+## 异常限制
+
+当覆盖方法的时候,只能抛出在基类方法的异常说明里列出的那些异常。这个限制很有用,因为这意味着,若当基类使用的代码应用到其派生类对象的时候,一样能够工作(当然,这是面向对象的基本概念),异常也不例外。
+
+下面例子演示了这种(在编译时)施加在异常上面的限制:
+
+```java
+// exceptions/StormyInning.java
+// Overridden methods can throw only the exceptions
+// specified in their base-class versions, or exceptions
+// derived from the base-class exceptions
+class BaseballException extends Exception {}
+class Foul extends BaseballException {}
+class Strike extends BaseballException {}
+abstract class Inning {
+ Inning() throws BaseballException {}
+ public void event() throws BaseballException {
+// Doesn't actually have to throw anything
+ }
+ public abstract void atBat() throws Strike, Foul;
+ public void walk() {} // Throws no checked exceptions
+}
+class StormException extends Exception {}
+class RainedOut extends StormException {}
+class PopFoul extends Foul {}
+interface Storm {
+ void event() throws RainedOut;
+ void rainHard() throws RainedOut;
+}
+public class StormyInning extends Inning implements Storm {
+ // OK to add new exceptions for constructors, but you
+// must deal with the base constructor exceptions:
+ public StormyInning()
+ throws RainedOut, BaseballException {}
+ public StormyInning(String s)
+ throws BaseballException {}
+ // Regular methods must conform to base class:
+//- void walk() throws PopFoul {} //Compile error
+// Interface CANNOT add exceptions to existing
+// methods from the base class:
+//- public void event() throws RainedOut {}
+// If the method doesn't already exist in the
+// base class, the exception is OK:
+ @Override
+ public void rainHard() throws RainedOut {}
+ // You can choose to not throw any exceptions,
+// even if the base version does:
+ @Override
+ public void event() {}
+ // Overridden methods can throw inherited exceptions:
+ @Override
+ public void atBat() throws PopFoul {}
+ public static void main(String[] args) {
+ try {
+ StormyInning si = new StormyInning();
+ si.atBat();
+ } catch(PopFoul e) {
+ System.out.println("Pop foul");
+ } catch(RainedOut e) {
+ System.out.println("Rained out");
+ } catch(BaseballException e) {
+ System.out.println("Generic baseball exception");
+ }
+// Strike not thrown in derived version.
+ try {
+// What happens if you upcast?
+ Inning i = new StormyInning();
+ i.atBat();
+// You must catch the exceptions from the
+// base-class version of the method:
+ } catch(Strike e) {
+ System.out.println("Strike");
+ } catch(Foul e) {
+ System.out.println("Foul");
+ } catch(RainedOut e) {
+ System.out.println("Rained out");
+ } catch(BaseballException e) {
+ System.out.println("Generic baseball exception");
+ }
+ }
+}
+```
+
+在 Inning 类中,可以看到构造器和 event() 方法都声明将抛出异常,但实际上没有抛出。这种方式使你能强制用户去捕获可能在覆盖后的 event() 版本中增加的异常,所以它很合理。这对于抽象方法同样成立,比如 atBat()。
+
+接口 Storm 包含了一个在 Inning 中定义的方法 event() 和一个不在 Inning 中定义的方法 rainHard()。这两个方法都抛出新的异常 RainedOut,如果 StormyInning 类在扩展 Inning 类的同时又实现了 Storm 接口,那么 Storm 里的 event() 方法就不能改变在 Inning 中的 event(方法的异常接口。否则的话,在使用基类的时候就不能判断是否捕获了正确的异常,所以这也很合理。当然,如果接口里定义的方法不是来自于基类,比如 rainHard(),那么此方法抛出什么样的异常都没有问题。
+
+异常限制对构造器不起作用。你会发现 StormyInning 的构造器可以抛出任何异常,而不必理会基类构造器所抛出的异常。然而,因为基类构造器必须以这样或那样的方式被调用(这里默认构造器将自动被调用),派生类构造器的异常说明必须包含基类构造器的异常说明。
+
+派生类构造器不能捕获基类构造器抛出的异常。
+
+StormyInning.walk() 不能通过编译是因为它抛出了异常,而 Inning.walk() 并没有声明此异常。如果编译器允许这么做的话,就可以在调用 Inning.walk() 的时候不用做异常处理了,而且当把它替换成 Inning 的派生类的对象时,这个方法就有可能会抛出异常,于是程序就失灵了。通过强制派生类遵守基类方法的异常说明,对象的可替换性得到了保证。
+
+覆盖后的 event() 方法表明,派生类方法可以不抛出任何异常,即使它是基类所定义的异常。同样这是因为,假使基类的方法会抛出异常,这样做也不会破坏已有的程序,所以也没有问题。类似的情况出现在 atBat() 身上,它抛出的是 PopFoul,这个异常是继承自“会被基类的 atBat() 抛出”的 Foul,这样,如果你写的代码是同 Inning 打交道,并且调用了它的 atBat() 的话,那么肯定能捕获 Foul,而 PopFoul 是由 Foul 派生出来的,因此异常处理程序也能捕获 PopFoul。
+
+最后一个值得注意的地方是 main()。这里可以看到,如果处理的刚好是 Stormylnning 对象的话,编译器只会强制要求你捕获这个类所抛出的异常。但是如果将它向上转型成基类型,那么编译器就会(正确地)要求你捕获基类的异常。所有这些限制都是为了能产生更为强壮的异常处理代码。
+
+尽管在继承过程中,编译器会对异常说明做强制要求,但异常说明本身并不属于方法类型的一部分,方法类型是由方法的名字与参数的类型组成的。因此,不能基于异常说明来重载方法。此外,一个出现在基类方法的异常说明中的异常,不一定会出现在派生类方法的异常说明里。这点同继承的规则明显不同,在继承中,基类的方法必须出现在派生类里,换句话说,在继承和覆盖的过程中,某个特定方法的“异常说明的接口”不是变大了而是变小了——这恰好和类接口在继承时的情形相反。
+
+
+
+## 构造器
+
+有一点很重要,即你要时刻询问自己“如果异常发生了,所有东西能被正确的清理吗?"尽管大多数情况下是非常安全的,但涉及构造器时,问题就出现了。构造器会把对象设置成安全的初始状态,但还会有别的动作,比如打开一个文件,这样的动作只有在对象使用完毕并且用户调用了特殊的清理方法之后才能得以清理。如果在构造器内抛出了异常,这些清理行为也许就不能正常工作了。这意味着在编写构造器时要格外细心。
+
+你也许会认为使用 finally 就可以解决问题。但问题并非如此简单,因为 finally 会每次都执行清理代码。如果构造器在其执行过程中半途而废,也许该对象的某些部分还没有被成功创建,而这些部分在 finaly 子句中却是要被清理的。
+
+在下面的例子中,建立了一个 InputFile 类,它能打开一个文件并且每次读取其中的一行。这里使用了 Java 标准输入/输出库中的 FileReader 和 BufferedReader 类(将在 [附录:I/O 流 ](./Appendix-IO-Streams.md) 中讨论),这些类的基本用法很简单,你应该很容易明白:
+
+```java
+// exceptions/InputFile.java
+// Paying attention to exceptions in constructors
+import java.io.*;
+public class InputFile {
+ private BufferedReader in;
+ public InputFile(String fname) throws Exception {
+ try {
+ in = new BufferedReader(new FileReader(fname));
+ // Other code that might throw exceptions
+ } catch(FileNotFoundException e) {
+ System.out.println("Could not open " + fname);
+ // Wasn't open, so don't close it
+ throw e;
+ } catch(Exception e) {
+ // All other exceptions must close it
+ try {
+ in.close();
+ } catch(IOException e2) {
+ System.out.println("in.close() unsuccessful");
+ }
+ throw e; // Rethrow
+ } finally {
+ // Don't close it here!!!
+ }
+ }
+ public String getLine() {
+ String s;
+ try {
+ s = in.readLine();
+ } catch(IOException e) {
+ throw new RuntimeException("readLine() failed");
+ }
+ return s;
+ }
+ public void dispose() {
+ try {
+ in.close();
+ System.out.println("dispose() successful");
+ } catch(IOException e2) {
+ throw new RuntimeException("in.close() failed");
+ }
+ }
+}
+```
+
+InputFile 的构造器接受字符串作为参数,该字符串表示所要打开的文件名。在 try 块中,会使用此文件名建立 FileReader 对象。FileReader 对象本身用处并不大,但可以用它来建立 BufferedReader 对象。注意,使用 InputFile 的好处之一是把两步操作合而为一。
+
+如果 FileReader 的构造器失败了,将抛出 FileNotFoundException 异常。对于这个异常,并不需要关闭文件,因为这个文件还没有被打开。而任何其他捕获异常的 catch 子句必须关闭文件,因为在它们捕获到异常之时,文件已经打开了(当然,如果还有其他方法能抛出 FileNotFoundException,这个方法就显得有些投机取巧了。这时,通常必须把这些方法分别放到各自的 try 块里),close() 方法也可能会抛出异常,所以尽管它已经在另一个 catch 子句块里了,还是要再用一层 try-catch,这对 Java 编译器而言只不过是多了一对花括号。在本地做完处理之后,异常被重新抛出,对于构造器而言这么做是很合适的,因为你总不希望去误导调用方,让他认为“这个对象已经创建完毕,可以使用了”。
+
+在本例中,由于 finally 会在每次完成构造器之后都执行一遍,因此它实在不该是调用 close() 关闭文件的地方。我们希望文件在 InputFlle 对象的整个生命周期内都处于打开状态。
+
+getLine() 方法会返回表示文件下一行内容的字符串。它调用了能抛出异常的 readLine(),但是这个异常已经在方法内得到处理,因此 getLine() 不会抛出任何异常。在设计异常时有一个问题:应该把异常全部放在这一层处理;还是先处理一部分,然后再向上层抛出相同的(或新的)异常;又或者是不做任何处理直接向上层抛出。如果用法恰当的话,直接向上层抛出的确能简化编程。在这里,getLine() 方法将异常转换为 RuntimeException,表示一个编程错误。
+
+用户在不再需要 InputFile 对象时,就必须调用 dispose() 方法,这将释放 BufferedReader 和/或 FileReader 对象所占用的系统资源(比如文件句柄),在使用完 InputFile 对象之前是不会调用它的。可能你会考虑把上述功能放到 finalize() 里面,但我在 [封装](./Housekeeping.md) 讲过,你不知道 finalize() 会不会被调用(即使能确定它将被调用,也不知道在什么时候调用),这也是 Java 的缺陷:除了内存的清理之外,所有的清理都不会自动发生。所以必须告诉客户端程序员,这是他们的责任。
+
+对于在构造阶段可能会抛出异常,并且要求清理的类,最安全的使用方式是使用嵌套的 try 子句:
+
+```java
+// exceptions/Cleanup.java
+// Guaranteeing proper cleanup of a resource
+public class Cleanup {
+ public static void main(String[] args) {
+ try {
+ InputFile in = new InputFile("Cleanup.java");
+ try {
+ String s;
+ int i = 1;
+ while((s = in.getLine()) != null)
+ ; // Perform line-by-line processing here...
+ } catch(Exception e) {
+ System.out.println("Caught Exception in main");
+ e.printStackTrace(System.out);
+ } finally {
+ in.dispose();
+ }
+ } catch(Exception e) {
+ System.out.println(
+ "InputFile construction failed");
+ }
+ }
+}
+```
+
+输出为:
+
+```
+dispose() successful
+```
+
+请仔细观察这里的逻辑:对 InputFile 对象的构造在其自己的 try 语句块中有效,如果构造失败,将进入外部的 catch 子句,而 dispose() 方法不会被调用。但是,如果构造成功,我们肯定想确保对象能够被清理,因此在构造之后立即创建了一个新的 try 语句块。执行清理的 finally 与内部的 try 语句块相关联。在这种方式中,finally 子句在构造失败时是不会执行的,而在构造成功时将总是执行。
+
+这种通用的清理惯用法在构造器不抛出任何异常时也应该运用,其基本规则是:在创建需要清理的对象之后,立即进入一个 try-finally 语句块:
+
+```java
+// exceptions/CleanupIdiom.java
+// Disposable objects must be followed by a try-finally
+class NeedsCleanup { // Construction can't fail
+ private static long counter = 1;
+ private final long id = counter++;
+ public void dispose() {
+ System.out.println(
+ "NeedsCleanup " + id + " disposed");
+ }
+}
+class ConstructionException extends Exception {}
+class NeedsCleanup2 extends NeedsCleanup {
+ // Construction can fail:
+ NeedsCleanup2() throws ConstructionException {}
+}
+public class CleanupIdiom {
+ public static void main(String[] args) {
+ // [1]:
+ NeedsCleanup nc1 = new NeedsCleanup();
+ try {
+ // ...
+ } finally {
+ nc1.dispose();
+ }
+ // [2]:
+ // If construction cannot fail,
+ // you can group objects:
+ NeedsCleanup nc2 = new NeedsCleanup();
+ NeedsCleanup nc3 = new NeedsCleanup();
+ try {
+ // ...
+ } finally {
+ nc3.dispose(); // Reverse order of construction
+ nc2.dispose();
+ }
+ // [3]:
+ // If construction can fail you must guard each one:
+ try {
+ NeedsCleanup2 nc4 = new NeedsCleanup2();
+ try {
+ NeedsCleanup2 nc5 = new NeedsCleanup2();
+ try {
+ // ...
+ } finally {
+ nc5.dispose();
+ }
+ } catch(ConstructionException e) { // nc5 const.
+ System.out.println(e);
+ } finally {
+ nc4.dispose();
+ }
+ } catch(ConstructionException e) { // nc4 const.
+ System.out.println(e);
+ }
+ }
+}
+```
+
+输出为:
+
+```
+NeedsCleanup 1 disposed
+NeedsCleanup 3 disposed
+NeedsCleanup 2 disposed
+NeedsCleanup 5 disposed
+NeedsCleanup 4 disposed
+```
+
+- [1] 相当简单,遵循了在可去除对象之后紧跟 try-finally 的原则。如果对象构造不会失败,就不需要任何 catch。
+- [2] 为了构造和清理,可以看到将具有不能失败的构造器的对象分组在一起。
+- [3] 展示了如何处理那些具有可以失败的构造器,且需要清理的对象。为了正确处理这种情况,事情变得很棘手,因为对于每一个构造,都必须包含在其自己的 try-finally 语句块中,并且每一个对象构造必须都跟随一个 try-finally 语句块以确保清理。
+
+本例中的异常处理的棘手程度,对于应该创建不能失败的构造器是一个有力的论据,尽管这么做并非总是可行。
+
+注意,如果 dispose() 可以抛出异常,那么你可能需要额外的 try 语句块。基本上,你应该仔细考虑所有的可能性,并确保正确处理每一种情况。
+
+
+
+## Try-With-Resources 用法
+
+上一节的内容可能让你有些头疼。在考虑所有可能失败的方法时,找出放置所有 try-catch-finally 块的位置变得令人生畏。确保没有任何故障路径,使系统远离不稳定状态,这非常具有挑战性。
+
+InputFile.java 是一个特别棘手的情况,因为文件被打开(包含所有可能的异常),然后它在对象的生命周期中保持打开状态。每次调用 getLine() 都会导致异常,因此可以调用 dispose() 方法。这是一个很好的例子,因为它显示了事物的混乱程度。它还表明你应该尝试最好不要那样设计代码(当然,你经常会遇到这种你无法选择的代码设计的情况,因此你必须仍然理解它)。
+
+InputFile.java 一个更好的实现方式是如果构造函数读取文件并在内部缓冲它 —— 这样,文件的打开,读取和关闭都发生在构造函数中。或者,如果读取和存储文件不切实际,你可以改为生成 Stream。理想情况下,你可以设计成如下的样子:
+
+```java
+// exceptions/InputFile2.java
+import java.io.*;
+import java.nio.file.*;
+import java.util.stream.*;
+public class InputFile2 {
+ private String fname;
+
+ public InputFile2(String fname) {
+ this.fname = fname;
+ }
+
+ public Stream getLines() throws IOException {
+ return Files.lines(Paths.get(fname));
+ }
+
+ public static void
+ main(String[] args) throws IOException {
+ new InputFile2("InputFile2.java").getLines()
+ .skip(15)
+ .limit(1)
+ .forEach(System.out::println);
+ }
+}
+```
+
+输出为:
+
+```
+main(String[] args) throws IOException {
+```
+
+现在,getLines() 全权负责打开文件并创建 Stream。
+
+你不能总是轻易地回避这个问题。有时会有以下问题:
+
+1. 需要资源清理
+2. 需要在特定的时刻进行资源清理,比如你离开作用域的时候(在通常情况下意味着通过异常进行清理)。
+
+一个常见的例子是 jav.io.FileInputstream(将会在 [附录:I/O 流 ](./Appendix-IO-Streams.md) 中提到)。要正确使用它,你必须编写一些棘手的样板代码:
+
+```java
+// exceptions/MessyExceptions.java
+import java.io.*;
+public class MessyExceptions {
+ public static void main(String[] args) {
+ InputStream in = null;
+ try {
+ in = new FileInputStream(
+ new File("MessyExceptions.java"));
+ int contents = in.read();
+ // Process contents
+ } catch(IOException e) {
+ // Handle the error
+ } finally {
+ if(in != null) {
+ try {
+ in.close();
+ } catch(IOException e) {
+ // Handle the close() error
+ }
+ }
+ }
+ }
+}
+```
+
+当 finally 子句有自己的 try 块时,感觉事情变得过于复杂。
+
+幸运的是,Java 7 引入了 try-with-resources 语法,它可以非常清楚地简化上面的代码:
+
+```java
+// exceptions/TryWithResources.java
+import java.io.*;
+public class TryWithResources {
+ public static void main(String[] args) {
+ try(
+ InputStream in = new FileInputStream(
+ new File("TryWithResources.java"))
+ ) {
+ int contents = in.read();
+ // Process contents
+ } catch(IOException e) {
+ // Handle the error
+ }
+ }
+}
+```
+
+在 Java 7 之前,try 总是后面跟着一个 {,但是现在可以跟一个带括号的定义 - 这里是我们创建的 FileInputStream 对象。括号内的部分称为资源规范头(resource specification header)。现在可用于整个 try 块的其余部分。更重要的是,无论你如何退出 try 块(正常或异常),都会执行前一个 finally 子句的等价物,但不会编写那些杂乱而棘手的代码。这是一项重要的改进。
+
+它是如何工作的?在 try-with-resources 定义子句中创建的对象(在括号内)必须实现 java.lang.AutoCloseable 接口,这个接口有一个方法:close()。当在 Java 7 中引入 AutoCloseable 时,许多接口和类被修改以实现它;查看 Javadocs 中的 AutoCloseable,可以找到所有实现该接口的类列表,其中包括 Stream 对象:
+
+```java
+// exceptions/StreamsAreAutoCloseable.java
+import java.io.*;
+import java.nio.file.*;
+import java.util.stream.*;
+public class StreamsAreAutoCloseable {
+ public static void
+ main(String[] args) throws IOException{
+ try(
+ Stream in = Files.lines(
+ Paths.get("StreamsAreAutoCloseable.java"));
+ PrintWriter outfile = new PrintWriter(
+ "Results.txt"); // [1]
+ ) {
+ in.skip(5)
+ .limit(1)
+ .map(String::toLowerCase)
+ .forEachOrdered(outfile::println);
+ } // [2]
+ }
+}
+```
+
+- [1] 你在这里可以看到其他的特性:资源规范头中可以包含多个定义,并且通过分号进行分割(最后一个分号是可选的)。规范头中定义的每个对象都会在 try 语句块运行结束之后调用 close() 方法。
+- [2] try-with-resources 里面的 try 语句块可以不包含 catch 或者 finally 语句而独立存在。在这里,IOException 被 main() 方法抛出,所以这里并不需要在 try 后面跟着一个 catch 语句块。
+
+Java 5 中的 Closeable 已经被修改,修改之后的接口继承了 AutoCloseable 接口。所以所有实现了 Closeable 接口的对象,都支持了 try-with-resources 特性。
+
+### 揭示细节
+
+为了研究 try-with-resources 的基本机制,我们将创建自己的 AutoCloseable 类:
+
+```java
+// exceptions/AutoCloseableDetails.java
+class Reporter implements AutoCloseable {
+ String name = getClass().getSimpleName();
+ Reporter() {
+ System.out.println("Creating " + name);
+ }
+ public void close() {
+ System.out.println("Closing " + name);
+ }
+}
+class First extends Reporter {}
+class Second extends Reporter {}
+public class AutoCloseableDetails {
+ public static void main(String[] args) {
+ try(
+ First f = new First();
+ Second s = new Second()
+ ) {
+ }
+ }
+}
+```
+
+输出为:
+
+```
+Creating First
+Creating Second
+Closing Second
+Closing First
+```
+
+退出 try 块会调用两个对象的 close() 方法,并以与创建顺序相反的顺序关闭它们。顺序很重要,因为在此配置中,Second 对象可能依赖于 First 对象,因此如果 First 在第 Second 关闭时已经关闭。 Second 的 close() 方法可能会尝试访问 First 中不再可用的某些功能。
+
+假设我们在资源规范头中定义了一个不是 AutoCloseable 的对象
+
+```java
+// exceptions/TryAnything.java
+// {WillNotCompile}
+class Anything {}
+public class TryAnything {
+ public static void main(String[] args) {
+ try(
+ Anything a = new Anything()
+ ) {
+ }
+ }
+}
+```
+
+正如我们所希望和期望的那样,Java 不会让我们这样做,并且出现编译时错误。
+
+如果其中一个构造函数抛出异常怎么办?
+
+```java
+// exceptions/ConstructorException.java
+class CE extends Exception {}
+class SecondExcept extends Reporter {
+ SecondExcept() throws CE {
+ super();
+ throw new CE();
+ }
+}
+public class ConstructorException {
+ public static void main(String[] args) {
+ try(
+ First f = new First();
+ SecondExcept s = new SecondExcept();
+ Second s2 = new Second()
+ ) {
+ System.out.println("In body");
+ } catch(CE e) {
+ System.out.println("Caught: " + e);
+ }
+ }
+}
+```
+
+输出为:
+
+```
+Creating First
+Creating SecondExcept
+Closing First
+Caught: CE
+```
+
+现在资源规范头中定义了 3 个对象,中间的对象抛出异常。因此,编译器强制我们使用 catch 子句来捕获构造函数异常。这意味着资源规范头实际上被 try 块包围。
+
+正如预期的那样,First 创建时没有发生意外,SecondExcept 在创建期间抛出异常。请注意,不会为 SecondExcept 调用 close(),因为如果构造函数失败,则无法假设你可以安全地对该对象执行任何操作,包括关闭它。由于 SecondExcept 的异常,Second 对象实例 s2 不会被创建,因此也不会有清除事件发生。
+
+如果没有构造函数抛出异常,但你可能会在 try 的主体中获取它们,则再次强制你实现 catch 子句:
+
+```java
+// exceptions/BodyException.java
+class Third extends Reporter {}
+public class BodyException {
+ public static void main(String[] args) {
+ try(
+ First f = new First();
+ Second s2 = new Second()
+ ) {
+ System.out.println("In body");
+ Third t = new Third();
+ new SecondExcept();
+ System.out.println("End of body");
+ } catch(CE e) {
+ System.out.println("Caught: " + e);
+ }
+ }
+}
+```
+
+输出为:
+
+```java
+Creating First
+Creating Second
+In body
+Creating Third
+Creating SecondExcept
+Closing Second
+Closing First
+Caught: CE
+```
+
+请注意,第 3 个对象永远不会被清除。那是因为它不是在资源规范头中创建的,所以它没有被保护。这很重要,因为 Java 在这里没有以警告或错误的形式提供指导,因此像这样的错误很容易漏掉。实际上,如果依赖某些集成开发环境来自动重写代码,以使用 try-with-resources 特性,那么它们(在撰写本文时)通常只会保护它们遇到的第一个对象,而忽略其余的对象。
+
+最后,让我们看一下抛出异常的 close() 方法:
+
+```java
+// exceptions/CloseExceptions.java
+class CloseException extends Exception {}
+class Reporter2 implements AutoCloseable {
+ String name = getClass().getSimpleName();
+ Reporter2() {
+ System.out.println("Creating " + name);
+ }
+ public void close() throws CloseException {
+ System.out.println("Closing " + name);
+ }
+}
+class Closer extends Reporter2 {
+ @Override
+ public void close() throws CloseException {
+ super.close();
+ throw new CloseException();
+ }
+}
+public class CloseExceptions {
+ public static void main(String[] args) {
+ try(
+ First f = new First();
+ Closer c = new Closer();
+ Second s = new Second()
+ ) {
+ System.out.println("In body");
+ } catch(CloseException e) {
+ System.out.println("Caught: " + e);
+ }
+ }
+}
+```
+
+输出为:
+
+```
+Creating First
+Creating Closer
+Creating Second
+In body
+Closing Second
+Closing Closer
+Closing First
+Caught: CloseException
+```
+
+从技术上讲,我们并没有被迫在这里提供一个 catch 子句;你可以通过 **main() throws CloseException** 的方式来报告异常。但 catch 子句是放置错误处理代码的典型位置。
+
+请注意,因为所有三个对象都已创建,所以它们都以相反的顺序关闭 - 即使 Closer 也是如此。 close() 抛出异常。当你想到它时,这就是你想要发生的事情,但是如果你必须自己编写所有这些逻辑,那么你可能会错过一些错误。想象一下所有代码都在那里,程序员没有考虑清理的所有含义,并且做错了。因此,应始终尽可能使用 try-with-resources。它有助于实现该功能,使得生成的代码更清晰,更易于理解。
+
+
+
+## 异常匹配
+
+抛出异常的时候,异常处理系统会按照代码的书写顺序找出“最近”的处理程序。找到匹配的处理程序之后,它就认为异常将得到处理,然后就不再继续查找。
+
+查找的时候并不要求抛出的异常同处理程序所声明的异常完全匹配。派生类的对象也可以匹配其基类的处理程序,就像这样:
+
+```java
+// exceptions/Human.java
+// Catching exception hierarchies
+class Annoyance extends Exception {}
+class Sneeze extends Annoyance {}
+public class Human {
+ public static void main(String[] args) {
+ // Catch the exact type:
+ try {
+ throw new Sneeze();
+ } catch(Sneeze s) {
+ System.out.println("Caught Sneeze");
+ } catch(Annoyance a) {
+ System.out.println("Caught Annoyance");
+ }
+ // Catch the base type:
+ try {
+ throw new Sneeze();
+ } catch(Annoyance a) {
+ System.out.println("Caught Annoyance");
+ }
+ }
+}
+```
+
+输出为:
+
+```java
+Caught Sneeze
+Caught Annoyance
+```
+
+Sneeze 异常会被第一个匹配的 catch 子句捕获,也就是程序里的第一个。然而如果将这个 catch 子句删掉,只留下 Annoyance 的 catch 子句,该程序仍然能运行,因为这次捕获的是 Sneeze 的基类。换句话说,catch(Annoyance a)会捕获 Annoyance 以及所有从它派生的异常。这一点非常有用,因为如果决定在方法里加上更多派生异常的话,只要客户程序员捕获的是基类异常,那么它们的代码就无需更改。
+
+如果把捕获基类的 catch 子句放在最前面,以此想把派生类的异常全给“屏蔽”掉,就像这样:
+
+```java
+try {
+ throw new Sneeze();
+} catch(Annoyance a) {
+ // ...
+} catch(Sneeze s) {
+ // ...
+}
+```
+
+此时,编译器会发现 Sneeze 的 catch 子句永远得不到执行,因此它会向你报告错误。
+
+
+
+## 其他可选方式
+
+异常处理系统就像一个活门(trap door),使你能放弃程序的正常执行序列。当“异常情形”
+发生的时候,正常的执行已变得不可能或者不需要了,这时就要用到这个“活门"。异常代表了当前方法不能继续执行的情形。开发异常处理系统的原因是,如果为每个方法所有可能发生的错误都进行处理的话,任务就显得过于繁重了,程序员也不愿意这么做。结果常常是将错误忽格。应该注意到,开发异常处理的初衷是为了方便程序员处理错误。
+
+异常处理的一个重要原则是“只有在你知道如何处理的情况下才捕获异常"。实际上,异常处理的一个重要目标就是把错误处理的代码同错误发生的地点相分离。这使你能在一段代码中专注于要完成的事情,至于如何处理错误,则放在另一段代码中完成。这样一来,主要代码就不会与错误处理逻辑混在一起,也更容易理解和维护。通过允许一个处理程序去处理多个出错点,异常处理还使得错误处理代码的数量趋于减少。
+
+“被检查的异常”使这个问题变得有些复杂,因为它们强制你在可能还没准备好处理错误的时候被迫加上 catch 子句,这就导致了吞食则有害(harmful if swallowed)的问题:
+
+```java
+try {
+ // ... to do something useful
+} catch(ObligatoryException e) {} // Gulp!
+```
+
+程序员们只做最简单的事情(包括我自己,在本书第 1 版中也有这个问题),常常是无意中"吞食”了异常,然而一旦这么做,虽然能通过编译,但除非你记得复查并改正代码,否则异常将会丢失。异常确实发生了,但“吞食”后它却完全消失了。因为编译器强迫你立刻写代码来处理异常,所以这种看起来最简单的方法,却可能是最糟糕的做法。
+
+当我意识到犯了这么大一个错误时,简直吓了一大跳,在本书第 2 版中,我在处理程序里通过打印栈轨迹的方法“修补”了这个问题(本章中的很多例子还是使用了这种方法,看起来还是比较合适的),虽然这样可以跟踪异常的行为,但是仍旧不知道该如何处理异常。这一节,我们来研究一下“被检查的异常”及其并发症,以及采用什么方法来解决这些问题。
+
+这个话题看起来简单,但实际上它不仅复杂,更重要的是还非常多变。总有人会顽固地坚持自己的立场,声称正确答案(也是他们的答案)是显而易见的。我觉得之所以会有这种观点,是因为我们使用的工具已经不是 ANS1 标准出台前的像 C 那样的弱类型语言,而是像 C++ 和 Java 这样的“强静态类型语言”(也就是编译时就做类型检查的语言),这是前者所无法比拟的。当刚开始这种转变的时候(就像我一样),会觉得它带来的好处是那样明显,好像类型检查总能解决所有的问题。在此,我想结合我自己的认识过程,告诉读者我是怎样从对类型检查的绝对迷信变成持怀疑态度的,当然,很多时候它还是非常有用的,但是当它挡住我们的去路并成为障碍的时候,我们就得跨过去。只是这条界限往往并不是很清晰(我最喜欢的一句格言是:所有模型都是错误的,但有些是能用的)。
+
+### 历史
+
+异常处理起源于 PL/1 和 Mesa 之类的系统中,后来又出现在 CLU、Smalltalk、Modula-3、Ada、Eiffel、C++、Python、Java 以及后 Java 语言 Ruby 和 C# 中。Java 的设计和 C++ 很相似,只是 Java 的设计者去掉了一些他们认为 C++设计得不好的东西。
+
+为了能向程序员提供一个他们更愿意使用的错误处理和恢复的框架,异常处理机制很晚才被加入 C++ 标准化过程中,这是由 C++ 的设计者 Bjarne Stroustrup 所倡议。C++ 的异常模型主要借鉴了 CLU 的做法。然而,当时其他语言已经支持异常处理了:包括 Ada、Smalltalk(两者都有异常处理,但是都没有异常说明),以及 Modula-3(它既有异常处理也有异常说明)。
+
+Liskov 和 Snyder 在他们的一篇讨论该主题的独创性论文中指出,用瞬时风格(transient fashion)报告错误的语言(如 C 中)有一个主要缺陷,那就是:
+
+> “....每次调用的时候都必须执行条件测试,以确定会产生何种结果。这使程序难以阅读并且有可能降低运行效率,因此程序员们既不愿意指出,也不愿意处理异常。”
+
+因此,异常处理的初衷是要消除这种限制,但是我们又从 Java 的“被检查的异常”中看到了这种代码。他们继续写道:
+
+> “....要求程序员把异常处理程序的代码文本附接到会引发异常的调用上,这会降低程序的可读性,使得程序的正常思路被异常处理给破坏了。”
+
+C++ 中异常的设计参考了 CLU 方式。Stroustrup 声称其目标是减少恢复错误所需的代码。我想他这话是说给那些通常情况下都不写 C 的错误处理的程序员们听的,因为要把那么多代码放到那么多地方实在不是什么好差事。所以他们写 C 程序的习惯是,忽略所有的错误,然后使用调试器来跟踪错误。这些程序员知道,使用异常就意味着他们要写一些通常不用写的、“多出来的”代码。因此,要把他们拉到“使用错误处理”的正轨上,“多出来的”代码决不能太多。我认为,评价 Java 的“被检查的异常”的时候,这一点是很重要的。
+
+C++ 从 CLU 那里还带来另一种思想:异常说明。这样,就可以用编程的方式在方法签名中声明这个方法将会抛出异常。异常说明有两个目的:一个是“我的代码会产生这种异常,这由你来处理”。另一个是“我的代码忽略了这些异常,这由你来处理”。学习异常处理的机制和语法的时候,我们一直在关注“你来处理”部分,但这里特别值得注意的事实是,我们通常都忽略了异常说明所表达的完整含义。
+
+C++ 的异常说明不属于函数的类型信息。编译时唯一要检查的是异常说明是不是前后一致;比如,如果函数或方法会抛出某些异常,那么它的重载版本或者派生版本也必须抛出同样的异常。与 Java 不同,C++ 不会在编译时进行检查以确定函数或方法是不是真的抛出异常,或者异常说明是不是完整(也就是说,异常说明有没有精确描述所有可能被抛出的异常)。这样的检查只发生在运行期间。如果抛出的异常与异常说明不符,C++ 会调用标准类库的 unexpected() 函数。
+
+值得注意的是,由于使用了模板,C++ 的标准类库实现里根本没有使用异常说明。在 Java 中,对于泛型用于异常说明的方式存在着一些限制。
+
+### 观点
+
+首先,Java 无谓地发明了“被检查的异常”(很明显是受 C++ 异常说明的启发,以及受 C++ 程序员们一般对此无动于衷的事实的影响),但是,这还只是一次尝试,目前为止还没有别的语言采用这种做法。
+
+其次,仅从示意性的例子和小程序来看,“被检查的异常”的好处很明显。但是当程序开始变大的时候,就会带来一些微妙的问题。当然,程序不是一下就变大的,这有个过程。如果把不适用于大项目的语言用于小项目,当这些项目不断膨胀时,突然有一天你会发现,原来可以管理的东西,现在已经变得无法管理了。这就是我所说的过多的类型检查,特别是“被检查的异常"所造成的问题。
+
+看来程序的规模是个重要因素。由于很多讨论都用小程序来做演示,因此这并不足以说明问题。一名 C# 的设计人员发现:
+
+> “仅从小程序来看,会认为异常说明能增加开发人员的效率,并提高代码的质量;但考察大项目的时候,结论就不同了-开发效率下降了,而代码质量只有微不足道的提高,甚至毫无提高”。
+
+谈到未被捕获的异常的时候,CLU 的设计师们认为:
+
+> “我们觉得强迫程序员在不知道该采取什么措施的时候提供处理程序,是不现实的。”
+
+在解释为什么“函数没有异常说明就表示可以抛出任何异常”的时候,Stroustrup 这样认为:
+
+> “但是,这样一来几乎所有的函数都得提供异常说明了,也就都得重新编译,而且还会妨碍它同其他语言的交互。这样会迫使程序员违反异常处理机制的约束,他们会写欺骗程序来掩盖异常。这将给没有注意到这些异常的人造成一种虚假的安全感。”
+>
+
+我们已经看到这种破坏异常机制的行为了-就在 Java 的“被检查的异常”里。
+
+Martin Fowler(UML Distilled,Refactoring 和 Analysis Patterns 的作者)给我写了下面这段话:
+
+> “...总体来说,我觉得异常很不错,但是 Java 的”被检查的异常“带来的麻烦比好处要多。”
+
+过去,我曾坚定地认为“被检查的异常”和强静态类型检查对开发健壮的程序是非常必要的。但是,我看到的以及我使用一些动态(类型检查)语言的亲身经历告诉我,这些好处实际上是来自于:
+
+1. 不在于编译器是否会强制程序员去处理错误,而是要有一致的、使用异常来报告错误的模型。
+2. 不在于什么时候进行检查,而是一定要有类型检查。也就是说,必须强制程序使用正确的类型,至于这种强制施加于编译时还是运行时,那倒没关系。
+
+此外,减少编译时施加的约束能显著提高程序员的编程效率。事实上,反射和泛型就是用来补偿静态类型检查所带来的过多限制,在本书很多例子中都会见到这种情形。
+
+我已经听到有人在指责了,他们认为这种言论会令我名誉扫地,会让文明堕落,会导致更高比例的项目失败。他们的信念是应该在编译时指出所有错误,这样才能挽救项目,这种信念可以说是无比坚定的;其实更重要的是要理解编译器的能力限制。在 http://MindView.net/Books/BetterJava 上的补充材料中,我强调了自动构建过程和单元测试的重要性,比起把所有的东西都说成是语法错误,它们的效果可以说是事半功倍。下面这段话是至理名言:
+
+> 好的程序设计语言能帮助程序员写出好程序,但无论哪种语言都避免不了程序员用它写出坏程序。
+
+不管怎么说,要让 Java 把“被检查的异常”从语言中去除,这种可能性看来非常渺茫。对语言来说,这个变化可能太激进了点,况且 Sun 的支持者们也非常强大。Sun 有完全向后兼容的历史和策略,实际上所有 Sun 的软件都能在 Sun 的硬件上运行,无论它们有多么古老。然而,如果发现有些“被检查的异常”挡住了路,尤其是发现你不得不去对付那些不知道该如何处理的异常,还是有些办法的。
+
+### 把异常传递给控制台
+
+对于简单的程序,比如本书中的许多例子,最简单而又不用写多少代码就能保护异常信息的方法,就是把它们从 main() 传递到控制台。例如,为了读取信息而打开一个文件(在第 12 章将详细介绍),必须对 FilelnputStream 进行打开和关闭操作,这就可能会产生异常。对于简单的程序,可以像这样做(本书中很多地方采用了这种方法):
+
+```java
+// exceptions/MainException.java
+import java.util.*;
+import java.nio.file.*;
+public class MainException {
+ // Pass exceptions to the console:
+ public static void main(String[] args) throws Exception {
+ // Open the file:
+ List lines = Files.readAllLines(
+ Paths.get("MainException.java"));
+ // Use the file ...
+ }
+}
+```
+
+注意,main() 作为一个方法也可以有异常说明,这里异常的类型是 Exception,它也是所有“被检查的异常”的基类。通过把它传递到控制台,就不必在 main() 里写 try-catch 子句了。(不过,实际的文件输人输出操作比这个例子要复杂得多。你将会在 [文件](./Files.md) 和 [附录:I/O 流](./Appendix-IO-Streams.md) 章节中学到更多)
+
+### 把“被检查的异常”转换为“不检查的异常”
+在编写你自己使用的简单程序时,从主方法中抛出异常是很方便的,但这不是通用的方法。
+
+问题的实质是,当在一个普通方法里调用别的方法时,要考虑到“我不知道该这样处理这个异常,但是也不想把它‘吞’了,或若打印一些无用的消息”。异常链提供了一种新的思路来解决这个问题。
+可以直接把“被检查的异常”包装进 RuntimeException 里面:
+```java
+try {
+ // ...
+} catch(IDontKnowWhatToDoWithThisCheckedException e) {
+ throw new RuntimeException(e);
+}
+```
+如果想把“被检查的异常”这种功能“屏蔽”掉的话,这看上去像是一个好办法。不用“吞下”异常,也不必把它放到方法的异常说明里面,而异常链还能保证你不会丢失任何原始异常的信息。
+
+这种技巧给了你一种选择,可以不写 try-catch 子句和/或异常说明,直接忽略异常,让它自己沿着调用栈往上“冒泡”,同时,还可以用 getCause() 捕获并处理特定的异常,就像这样:
+```java
+// "Turning off" Checked exceptions
+import java.io.*;
+class WrapCheckedException {
+ void throwRuntimeException(int type) {
+ try {
+ switch(type) {
+ case 0: throw new FileNotFoundException();
+ case 1: throw new IOException();
+ case 2: throw new
+ RuntimeException("Where am I?");
+ default: return;
+ }
+ } catch(IOException | RuntimeException e) {
+ // Adapt to unchecked:
+ throw new RuntimeException(e);
+ }
+ }
+}
+class SomeOtherException extends Exception {}
+public class TurnOffChecking {
+ public static void main(String[] args) {
+ WrapCheckedException wce =
+ new WrapCheckedException();
+ // You can call throwRuntimeException() without
+ // a try block, and let RuntimeExceptions
+ // leave the method:
+ wce.throwRuntimeException(3);
+ // Or you can choose to catch exceptions:
+ for(int i = 0; i < 4; i++)
+ try {
+ if(i < 3)
+ wce.throwRuntimeException(i);
+ else
+ throw new SomeOtherException();
+ } catch(SomeOtherException e) {
+ System.out.println(
+ "SomeOtherException: " + e);
+ } catch(RuntimeException re) {
+ try {
+ throw re.getCause();
+ } catch(FileNotFoundException e) {
+ System.out.println(
+ "FileNotFoundException: " + e);
+ } catch(IOException e) {
+ System.out.println("IOException: " + e);
+ } catch(Throwable e) {
+ System.out.println("Throwable: " + e);
+ }
+ }
+ }
+}
+```
+
+输出为:
+
+```
+FileNotFoundException: java.io.FileNotFoundException
+IOException: java.io.IOException
+Throwable: java.lang.RuntimeException: Where am I?
+SomeOtherException: SomeOtherException
+```
+
+WrapCheckedException.throwRuntimeException() 的代码可以生成不同类型的异常。这些异常被捕获并包装进了 RuntimeException 对象,所以它们成了这些运行时异常的"cause"了。
+
+在 TurnOfChecking 里,可以不用 try 块就调用 throwRuntimeException(),因为它没有抛出“被检查的异常”。但是,当你准备好去捕获异常的时候,还是可以用 try 块来捕获任何你想捕获的异常的。应该捕获 try 块肯定会抛出的异常,这里就是 SomeOtherException,RuntimeException 要放到最后去捕获。然后把 getCause() 的结果(也就是被包装的那个原始异常)抛出来。这样就把原先的那个异常给提取出来了,然后就可以用它们自己的 catch 子句进行处理。
+
+另一种解决方案是创建自己的 RuntimeException 的子类。在这种方式中,不必捕获它,但是希望得到它的其他代码都可以捕获它。
+
+## 异常指南
+应该在下列情况下使用异常:
+
+1. 尽可能使用 try-with-resource。
+2. 在恰当的级别处理问题。(在知道该如何处理的情况下才捕获异常。)
+3. 解决问题并且重新调用产生异常的方法。
+4. 进行少许修补,然后绕过异常发生的地方继续执行。
+5. 用别的数据进行计算,以代替方法预计会返回的值。
+6. 把当前运行环境下能做的事情尽量做完,然后把相同的异常重抛到更高层。
+7. 把当前运行环境下能做的事情尽量做完,然后把不同的异常抛到更高层。
+8. 终止程序。
+9. 进行简化。(如果你的异常模式使问题变得太复杂,那用起来会非常痛苦也很烦人。)
+10. 让类库和程序更安全。(这既是在为调试做短期投资,也是在为程序的健壮性做长期投资。)
+
+# 总结
+异常是 Java 程序设计不可分割的一部分,如果不了解如何使用它们,那你只能完成很有限的工作。正因为如此,本书专门在此介绍了异常——对于许多类库(例如提到过的 I/O 库),如果不处理异常,你就无法使用它们。
+
+优点之一就是它使得你可以在某处集中精力处理你要解决的问题,而在另一处处理你编写的这段代码中产生的错误。尽管异常通常被认为是一种工具,使得你可以在运行时报告错误并从错误中恢复,但是我一直怀疑到底有多少时候“恢复”真正得以实现了,或者能够得以实现。我认为这种情况少于 10%,并且即便是这 10%,也只是将栈展开到某个已知的稳定状态,而并没有实际执行任何种类的恢复性行为。无论这是否正确,我一直相信“报告”功能是异常的精髓所在. Java 坚定地强调将所有的错误都以异常形式报告的这一事实,正是它远远超过语如 C++ 这类语言的长处之一,因为在 C++ 这类语言中,需要以大量不同的方式来报告错误,或者根本就没有提供错误报告功能。一致的错误报告系统意味着,你再也不必对所写的每一段代码,都质问自己“错误是否正在成为漏网之鱼?”(只要你没有“吞咽”异常,这是关键所在!)。
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\346\227\245\345\277\227\347\272\247\345\210\253\357\274\214\351\207\215\345\244\215\350\256\260\345\275\225\343\200\201\344\270\242\346\227\245\345\277\227\351\227\256\351\242\230.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\346\227\245\345\277\227\347\272\247\345\210\253\357\274\214\351\207\215\345\244\215\350\256\260\345\275\225\343\200\201\344\270\242\346\227\245\345\277\227\351\227\256\351\242\230.md"
new file mode 100644
index 0000000000..5da763f8e9
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\346\227\245\345\277\227\347\272\247\345\210\253\357\274\214\351\207\215\345\244\215\350\256\260\345\275\225\343\200\201\344\270\242\346\227\245\345\277\227\351\227\256\351\242\230.md"
@@ -0,0 +1,243 @@
+# 1 SLF4J
+## 日志行业的现状
+- 框架繁
+不同类库可能使用不同日志框架,兼容难,无法接入统一日志,让运维很头疼!
+- 配置复杂
+由于配置文件一般是 xml 文件,内容繁杂!很多人喜欢从其他项目或网上闭眼copy!
+- 随意度高
+因为不会直接导致代码 bug,测试人员也难发现问题,开发就没仔细考虑日志内容获取的性能开销,随意选用日志级别!
+
+Logback、Log4j、Log4j2、commons-logging及java.util.logging等,都是Java体系的日志框架。
+不同的类库,还可能选择使用不同的日志框架,导致日志统一管理困难。
+
+- SLF4J(Simple Logging Facade For Java)就为解决该问题而生
+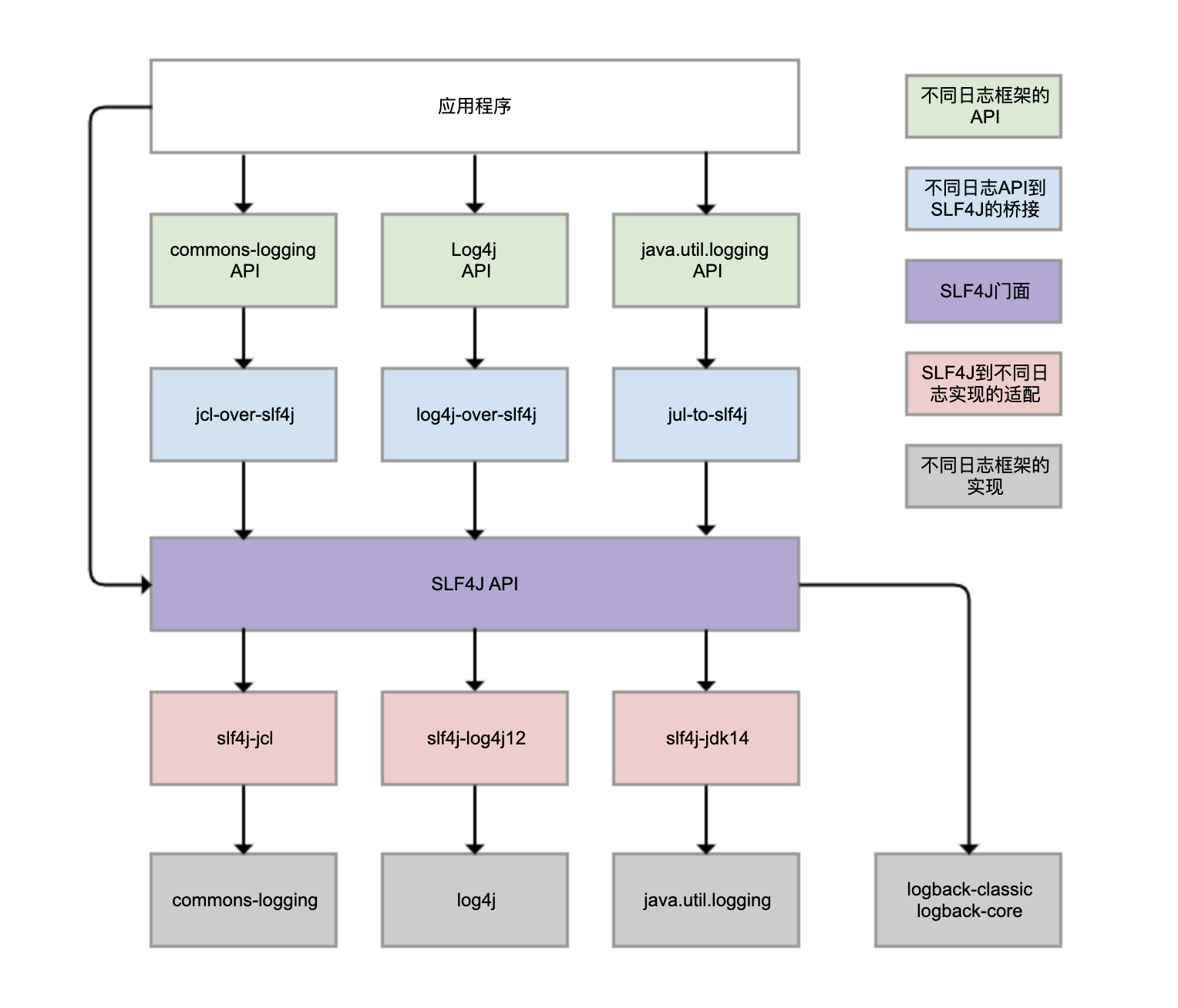
+
+- 提供统一的日志门面API
+图中紫色部分,实现中立的日志记录API
+- 桥接功能
+蓝色部分,把各种日志框架API桥接到SLF4J API。这样即使你的程序使用了各种日志API记录日志,最终都可桥接到SLF4J门面API
+- 适配功能
+红色部分,绑定SLF4J API和实际的日志框架(灰色部分)
+
+SLF4J只是日志标准,还是需要实际日志框架。日志框架本身未实现SLF4J API,所以需要有个前置转换。
+Logback本身就按SLF4J API标准实现,所以无需绑定模块做转换。
+
+虽然可用`log4j-over-slf4j`实现Log4j桥接到SLF4J,也可使用`slf4j-log4j12`实现SLF4J适配到Log4j,也把它们画到了一列,但是它不能同时使用它们,否则就会产生死循环。jcl和jul同理。
+
+虽然图中有4个灰色的日志实现框架,但业务开发使用最多的还是Logback和Log4j,都是同一人开发的。Logback可认为是Log4j改进版,更推荐使用,已是社会主流。
+
+Spring Boot的日志框架也是Logback。那为什么我们没有手动引入Logback包,就可直接使用Logback?
+
+spring-boot-starter模块依赖**spring-boot-starter-logging**模块,而
+**spring-boot-starter-logging**自动引入**logback-classic**(包含SLF4J和Logback日志框架)和SLF4J的一些适配器。
+# 2 异步日志就肯定能提高性能?
+如何避免日志记录成为系统性能瓶颈呢?
+这关系到磁盘(比如机械磁盘)IO性能较差、日志量又很大的情况下,如何记录日志。
+
+## 2.1 案例
+定义如下的日志配置,一共有两个Appender:
+- **FILE**是一个FileAppender,用于记录所有的日志
+- **CONSOLE**是一个ConsoleAppender,用于记录带有time标记的日志
+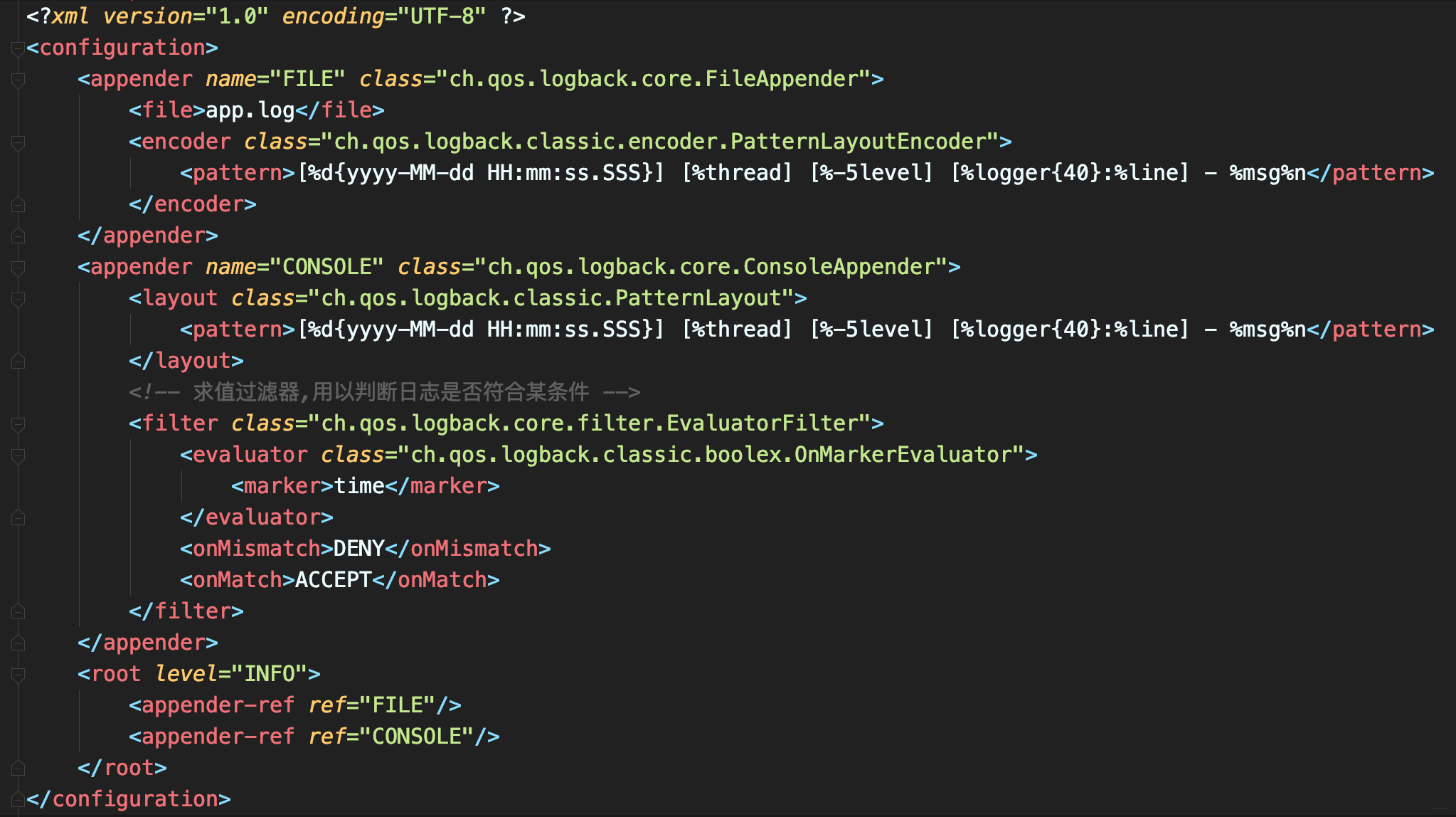
+
+把大量日志输出到文件中,日志文件会非常大,若性能测试结果也混在其中,就很难找到那条日志了。
+所以,这里使用EvaluatorFilter对日志按照标记进行过滤,并将过滤出的日志单独输出到控制台。该案例中给输出测试结果的那条日志上做了time标记。
+
+> **配合使用标记和EvaluatorFilter,可实现日志的按标签过滤**。
+
+- 测试代码:实现记录指定次数的大日志,每条日志包含1MB字节的模拟数据,最后记录一条以time为标记的方法执行耗时日志: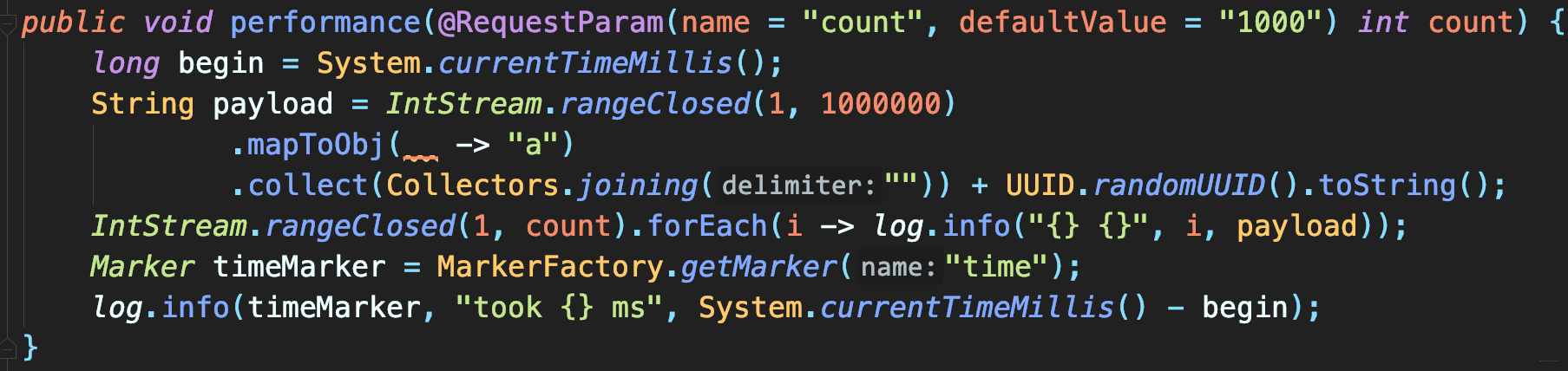
+
+执行程序后发现,记录1000次日志和10000次日志的调用耗时,分别是5.1s和39s
+
+对只记录文件日志的代码,这耗时过长了。
+## 2.2 源码解析
+FileAppender继承自OutputStreamAppender
+
+在追加日志时,是直接把日志写入OutputStream中,属**同步记录日志**
+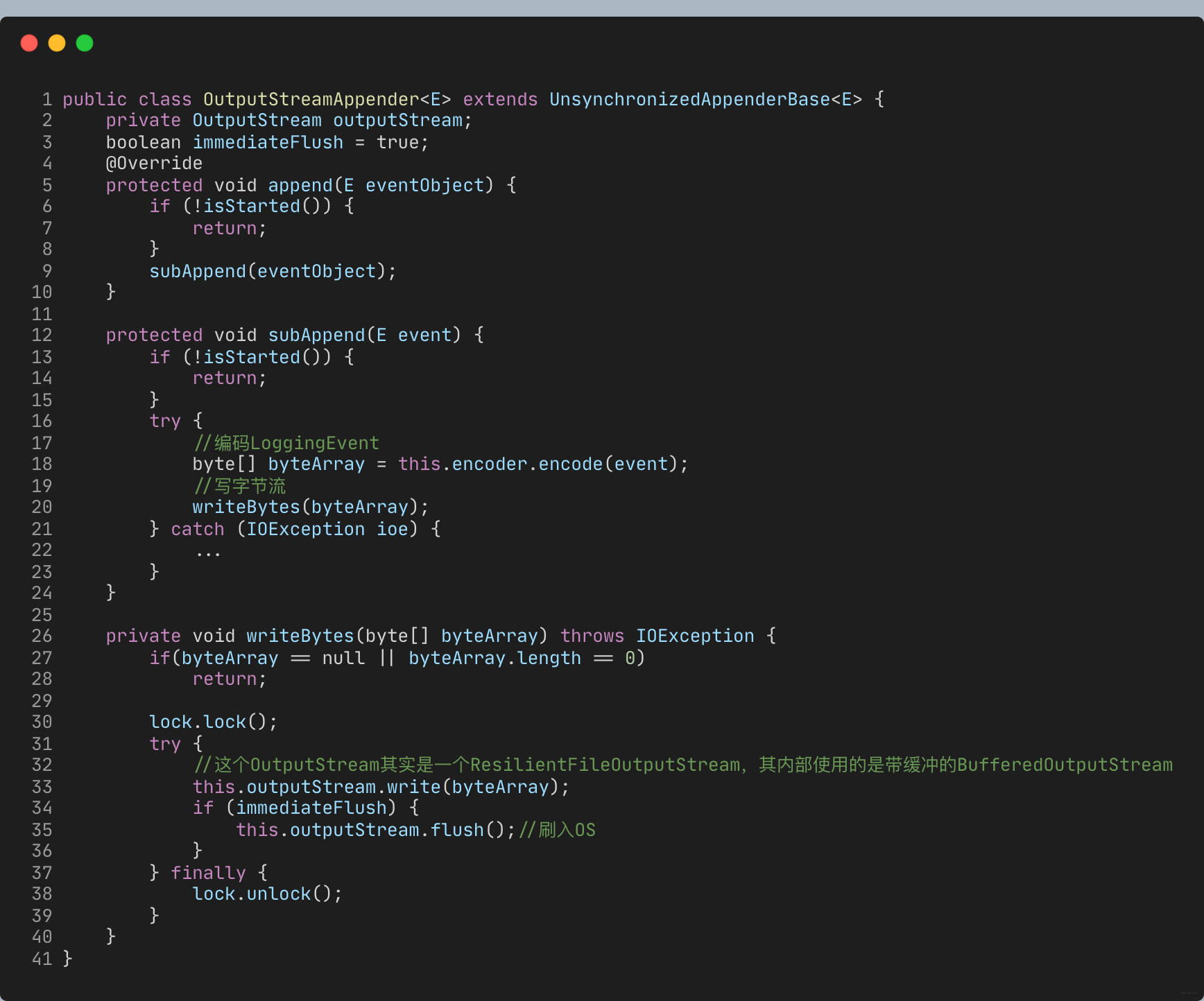
+所以日志大量写入才会旷日持久。如何才能实现大量日志写入时,不会过多影响业务逻辑执行耗时而影响吞吐量呢?
+## 2.3 AsyncAppender
+使用Logback的**AsyncAppender**,即可实现异步日志记录。
+
+**AsyncAppender**类似装饰模式,在不改变类原有基本功能情况下,为其增添新功能。这便可把**AsyncAppender**附加在其他**Appender**,将其变为异步。
+
+定义一个异步Appender ASYNCFILE,包装之前的同步文件日志记录的FileAppender, 即可实现异步记录日志到文件
+
+
+- 记录1000次日志和10000次日志的调用耗时,分别是537ms和1019ms
+
+异步日志真的如此高性能?并不,因为它并没有记录下所有日志。
+# 3 AsyncAppender异步日志的天坑
+- 记录异步日志撑爆内存
+- 记录异步日志出现日志丢失
+- 记录异步日志出现阻塞。
+
+## 3.1 案例
+模拟个慢日志记录场景:
+首先,自定义一个继承自**ConsoleAppender**的**MySlowAppender**,作为记录到控制台的输出器,写入日志时睡1s。
+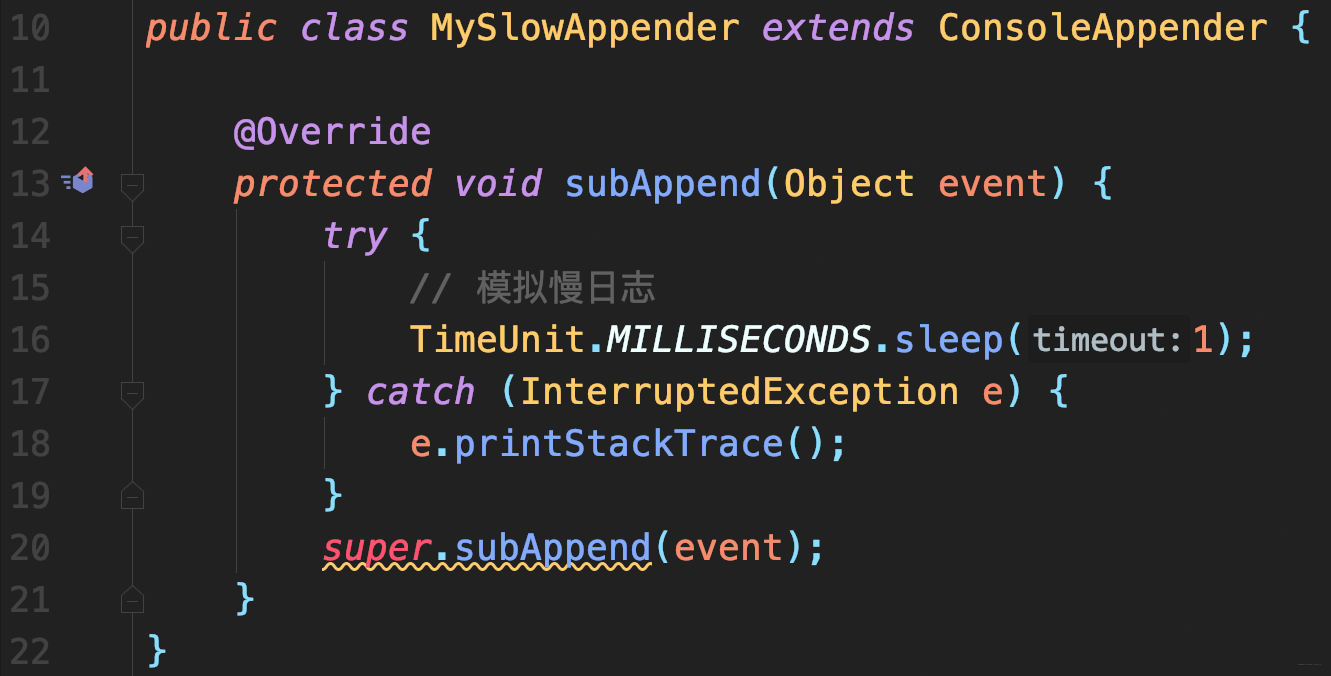
+
+- 配置文件中使用**AsyncAppender**,将**MySlowAppender**包装为异步日志记录
+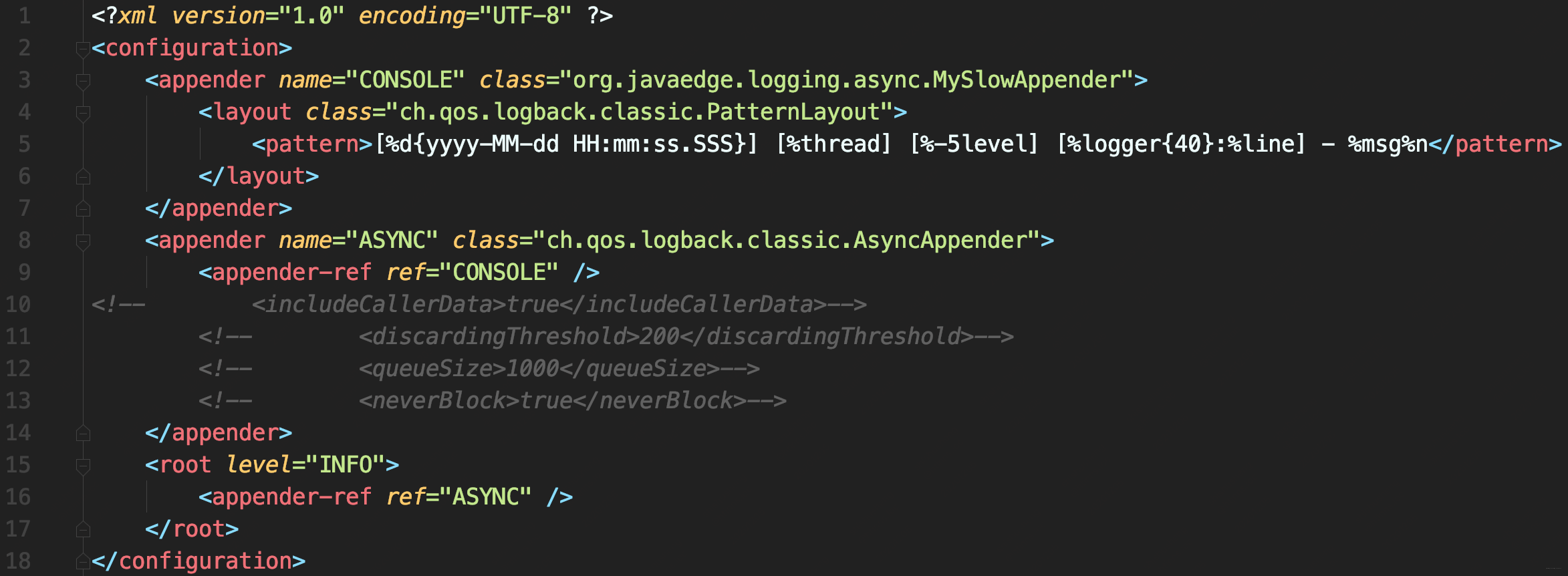
+
+- 测试代码
+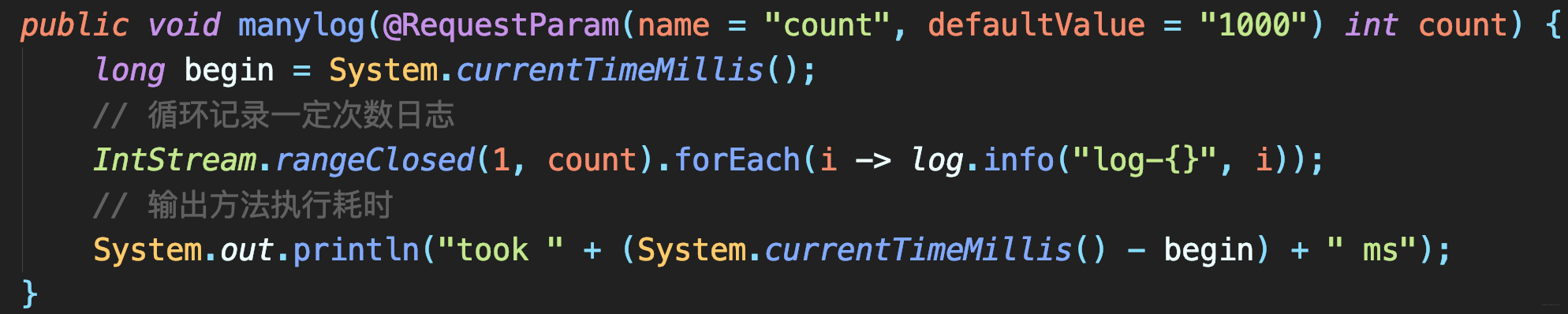
+
+- 耗时很短但出现日志丢失:要记录1000条日志,最终控制台只能搜索到215条日志,而且日志行号变问号。
+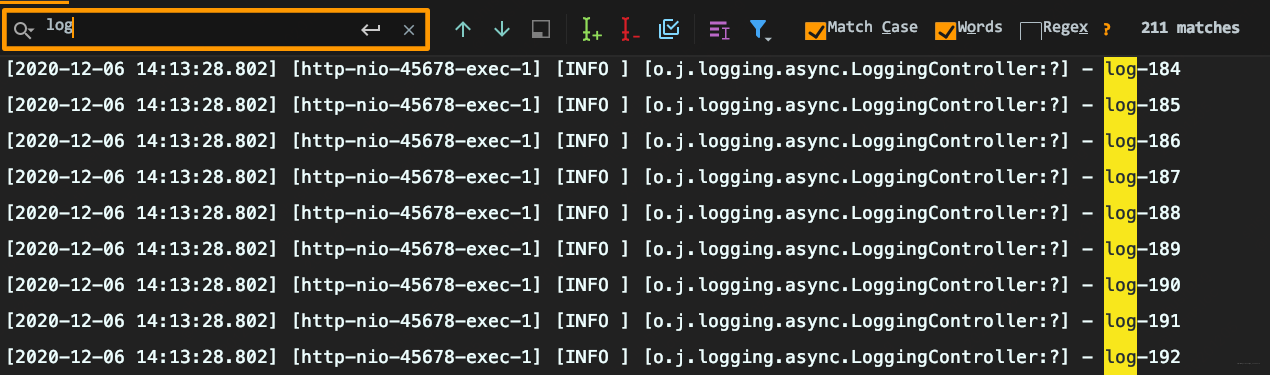
+- 原因分析
+**AsyncAppender**提供了一些配置参数,而当前没用对。
+
+### 源码解析
+- includeCallerData
+默认false:方法行号、方法名等信息不显示
+- queueSize
+控制阻塞队列大小,使用的ArrayBlockingQueue阻塞队列,默认容量256:内存中最多保存256条日志
+- discardingThreshold
+丢弃日志的阈值,为防止队列满后发生阻塞。默认`队列剩余容量 < 队列长度的20%`,就会丢弃TRACE、DEBUG和INFO级日志
+- neverBlock
+控制队列满时,加入的数据是否直接丢弃,不会阻塞等待,默认是false
+ - 队列满时:offer不阻塞,而put会阻塞
+ - neverBlock为true时,使用offer
+```java
+public class AsyncAppender extends AsyncAppenderBase {
+ // 是否收集调用方数据
+ boolean includeCallerData = false;
+ protected boolean isDiscardable(ILoggingEvent event) {
+ Level level = event.getLevel();
+ // 丢弃 ≤ INFO级日志
+ return level.toInt() <= Level.INFO_INT;
+ }
+ protected void preprocess(ILoggingEvent eventObject) {
+ eventObject.prepareForDeferredProcessing();
+ if (includeCallerData)
+ eventObject.getCallerData();
+ }
+}
+public class AsyncAppenderBase extends UnsynchronizedAppenderBase implements AppenderAttachable {
+
+ // 阻塞队列:实现异步日志的核心
+ BlockingQueue blockingQueue;
+ // 默认队列大小
+ public static final int DEFAULT_QUEUE_SIZE = 256;
+ int queueSize = DEFAULT_QUEUE_SIZE;
+ static final int UNDEFINED = -1;
+ int discardingThreshold = UNDEFINED;
+ // 当队列满时:加入数据时是否直接丢弃,不会阻塞等待
+ boolean neverBlock = false;
+
+ @Override
+ public void start() {
+ ...
+ blockingQueue = new ArrayBlockingQueue(queueSize);
+ if (discardingThreshold == UNDEFINED)
+ //默认丢弃阈值是队列剩余量低于队列长度的20%,参见isQueueBelowDiscardingThreshold方法
+ discardingThreshold = queueSize / 5;
+ ...
+ }
+
+ @Override
+ protected void append(E eventObject) {
+ if (isQueueBelowDiscardingThreshold() && isDiscardable(eventObject)) { //判断是否可以丢数据
+ return;
+ }
+ preprocess(eventObject);
+ put(eventObject);
+ }
+
+ private boolean isQueueBelowDiscardingThreshold() {
+ return (blockingQueue.remainingCapacity() < discardingThreshold);
+ }
+
+ private void put(E eventObject) {
+ if (neverBlock) { //根据neverBlock决定使用不阻塞的offer还是阻塞的put方法
+ blockingQueue.offer(eventObject);
+ } else {
+ putUninterruptibly(eventObject);
+ }
+ }
+ //以阻塞方式添加数据到队列
+ private void putUninterruptibly(E eventObject) {
+ boolean interrupted = false;
+ try {
+ while (true) {
+ try {
+ blockingQueue.put(eventObject);
+ break;
+ } catch (InterruptedException e) {
+ interrupted = true;
+ }
+ }
+ } finally {
+ if (interrupted) {
+ Thread.currentThread().interrupt();
+ }
+ }
+ }
+}
+```
+
+默认队列大小256,达到80%后开始丢弃<=INFO级日志后,即可理解日志中为什么只有两百多条INFO日志了。
+### queueSize 过大
+可能导致**OOM**
+### queueSize 较小
+默认值256就已经算很小了,且**discardingThreshold**设置为大于0(或为默认值),队列剩余容量少于**discardingThreshold**的配置就会丢弃<=INFO日志。这里的坑点有两个:
+1. 因为**discardingThreshold**,所以设置**queueSize**时容易踩坑。
+比如本案例最大日志并发1000,即便置**queueSize**为1000,同样会导致日志丢失
+2. **discardingThreshold**参数容易有歧义,它`不是百分比,而是日志条数`。对于总容量10000队列,若希望队列剩余容量少于1000时丢弃,需配置为1000
+### neverBlock 默认false
+意味总可能会出现阻塞。
+- 若**discardingThreshold = 0**,那么队列满时再有日志写入就会阻塞
+- 若**discardingThreshold != 0**,也只丢弃≤INFO级日志,出现大量错误日志时,还是会阻塞
+
+queueSize、discardingThreshold和neverBlock三参密不可分,务必按业务需求设置:
+- 若优先绝对性能,设置`neverBlock = true`,永不阻塞
+- 若优先绝不丢数据,设置`discardingThreshold = 0`,即使≤INFO级日志也不会丢。但最好把queueSize设置大一点,毕竟默认的queueSize显然太小,太容易阻塞。
+- 若兼顾,可丢弃不重要日志,把**queueSize**设置大点,再设置合理的**discardingThreshold**
+
+以上日志配置最常见两个误区
+
+再看日志记录本身的误区。
+
+# 4 如何选择日志级别?
+
+> 使用{}占位符,就不用判断log level了吗?
+
+据不知名网友说道:SLF4J的{}占位符语法,到真正记录日志时才会获取实际参数,因此解决了日志数据获取的性能问题。
+**是真的吗?**
+
+
+- 验证代码:返回结果耗时1s
+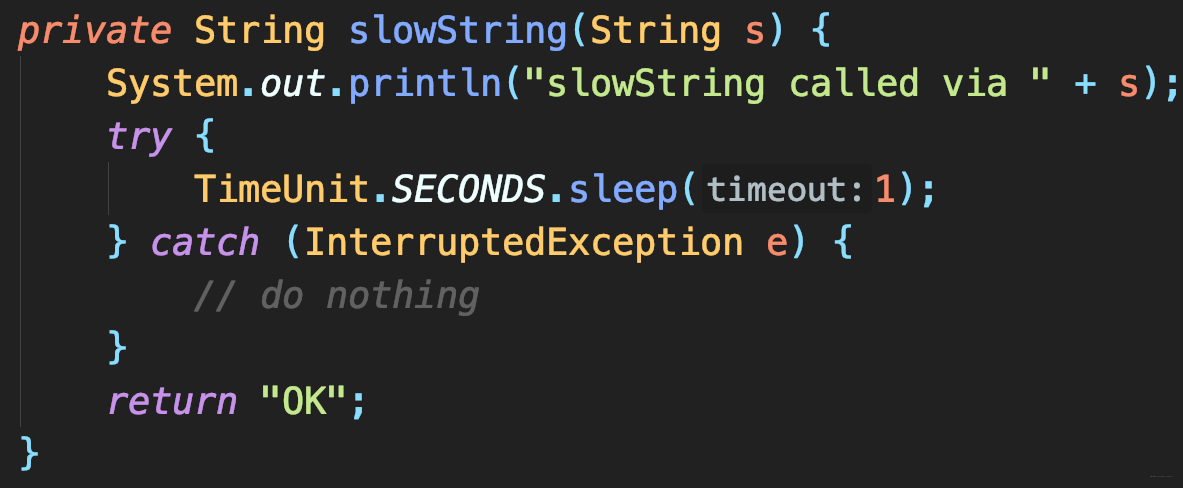
+
+若记录DEBUG日志,并设置只记录>=INFO级日志,程序是否也会耗时1s?
+三种方法测试:
+- 拼接字符串方式记录slowString
+- 使用占位符方式记录slowString
+- 先判断日志级别是否启用DEBUG。
+
+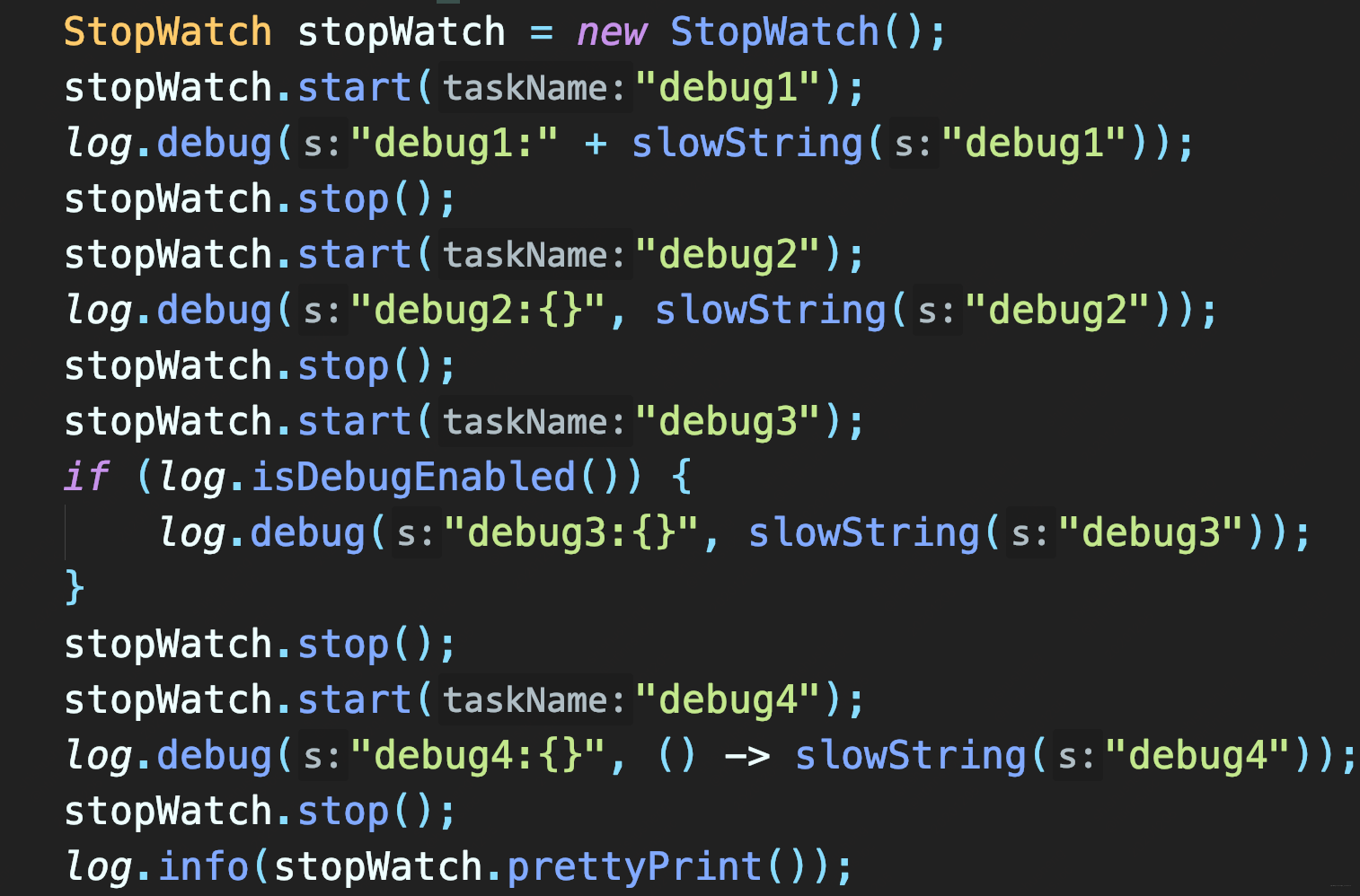
+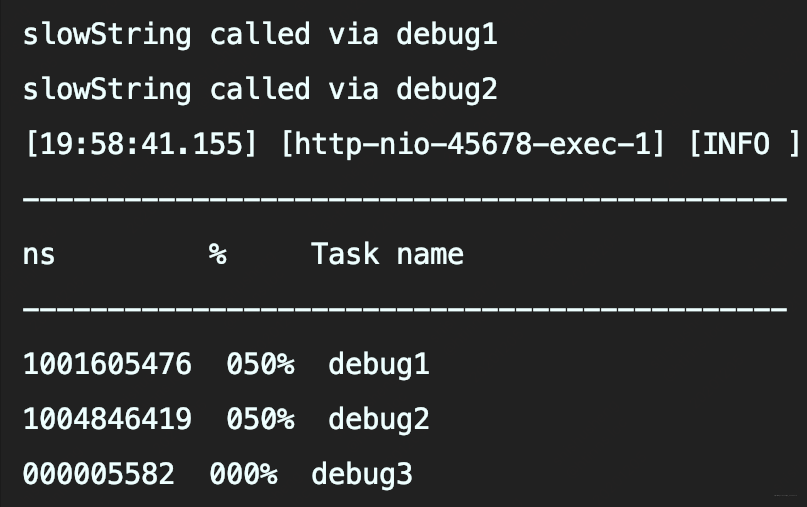
+前俩方式都调用slowString,所以都耗时1s。且方式二就是使用占位符记录slowString,这种方式虽允许传Object,不显式拼接String,但也只是延迟(若日志不记录那就是省去)**日志参数对象.toString()**和**字符串拼接**的耗时。
+
+本案例除非事先判断日志级别,否则必调用slowString。所以使用`{}占位符`不能通过延迟参数值获取,来解决日志数据获取的性能问题。
+
+除事先判断日志级别,还可通过lambda表达式延迟参数内容获取。但SLF4J的API还不支持lambda,因此需使用Log4j2日志API,把**Lombok的@Slf4j注解**替换为**@Log4j2**注解,即可提供lambda表达式参数的方法:
+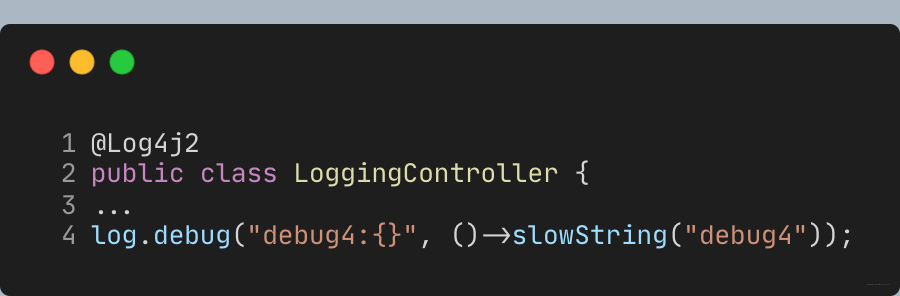
+
+这样调用debug,签名**Supplier**,参数就会延迟到真正需要记录日志时再获取:
+
+
+
+
+
+所以debug4并不会调用slowString方法
+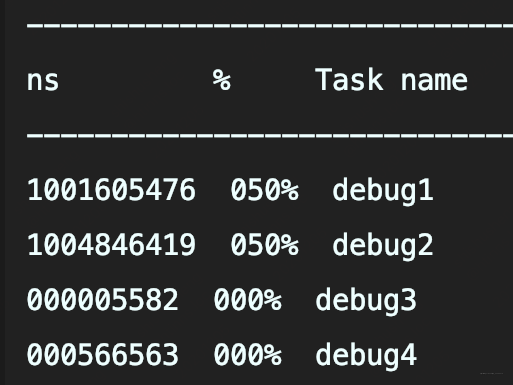
+
+只是换成**Log4j2 API**,真正的日志记录还是走的**Logback**,这就是**SLF4J**适配的好处。
+
+# 总结
+- SLF4J统一了Java日志框架。在使用SLF4J时,要理清楚其桥接API和绑定。若程序启动时出现SLF4J错误提示,可能是配置问题,可使用Maven的`dependency:tree`命令梳理依赖关系。
+- 异步日志解决性能问题,是用空间换时间。但空间毕竟有限,当空间满,要考虑阻塞等待or丢弃日志。若更希望不丢弃重要日志,那么选择阻塞等待;如果更希望程序不要因为日志记录而阻塞,那么就需要丢弃日志。
+- 日志框架提供的参数化记录方式不能完全取代日志级别的判断。若日志量很大,获取日志参数代价也很大,就要判断日志级别,避免不记录日志也要耗时获取日志参数!
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\347\261\273\347\232\204\345\210\235\345\247\213\345\214\226\345\222\214\346\270\205\347\220\206.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\347\261\273\347\232\204\345\210\235\345\247\213\345\214\226\345\222\214\346\270\205\347\220\206.md"
new file mode 100644
index 0000000000..c4723983a7
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\347\261\273\347\232\204\345\210\235\345\247\213\345\214\226\345\222\214\346\270\205\347\220\206.md"
@@ -0,0 +1,1526 @@
+# 1 不安全的编程是造成编程代价昂贵的主因之一
+两个安全性问题
+## 1.1 初始化
+C 语言中很多的 bug 都是因为程序员忘记初始化导致的。尤其是很多类库的使用者不知道如何初始化类库组件,甚至当侠客们必须得初始化这些三方组件时(很多可怜的掉包侠根本不会管初始化问题)
+## 1.2 清理
+当使用一个元素做完事后就不会去关心这个元素,所以你很容易忘记清理它。这样就造成了元素使用的资源滞留不会被回收,直到程序消耗完所有的资源(特别是内存)。
+
+C++ 引入了构造器的概念,这是一个特殊的方法,每创建一个对象,这个方法就会被自动调用。Java 采用了构造器的概念,另外还使用了垃圾收集器(Garbage Collector, GC)去自动回收不再被使用的对象所占的资源。这一章将讨论初始化和清理的问题,以及在 Java 中对它们的支持。
+
+
+
+# 2 利用构造器保证初始化
+
+你可能想为每个类创建一个 `initialize()` 方法,该方法名暗示着在使用类之前需要先调用它。不幸的是,用户必须得记得去调用它。在 Java 中,类的设计者通过构造器保证每个对象的初始化。如果一个类有构造器,那么 Java 会在用户使用对象之前(即对象刚创建完成)自动调用对象的构造器方法,从而保证初始化。下个挑战是如何命名构造器方法。存在两个问题:第一个是任何命名都可能与类中其他已有元素的命名冲突;第二个是编译器必须始终知道构造器方法名称,从而调用它。C++ 的解决方法看起来是最简单且最符合逻辑的,所以 Java 中使用了同样的方式:构造器名称与类名相同。在初始化过程中自动调用构造器方法是有意义的。
+
+以下示例是包含了一个构造器的类:
+
+```java
+// housekeeping/SimpleConstructor.java
+// Demonstration of a simple constructor
+
+class Rock {
+ Rock() { // 这是一个构造器
+ System.out.print("Rock ");
+ }
+}
+
+public class SimpleConstructor {
+ public static void main(String[] args) {
+ for (int i = 0; i < 10; i++) {
+ new Rock();
+ }
+ }
+}
+```
+
+输出:
+
+````java
+Rock Rock Rock Rock Rock Rock Rock Rock Rock Rock
+````
+
+现在,当创建一个对象时:`new Rock()` ,内存被分配,构造器被调用。构造器保证了对象在你使用它之前进行了正确的初始化。
+
+> 构造器方法名与类名相同,不需要符合首字母小写的编程风格。
+
+在 C++ 中,无参构造器被称为默认构造器,这个术语在 Java 出现之前使用了很多年。但是,出于一些原因,Java 设计者们决定使用无参构造器这个名称,我(作者)认为这种叫法笨拙而且没有必要,所以我打算继续使用默认构造器。Java 8 引入了 **default** 关键字修饰方法,所以算了,我还是用无参构造器的叫法吧。
+
+跟其他方法一样,构造器方法也可以传入参数来定义如何创建一个对象。之前的例子稍作修改,使得构造器接收一个参数:
+
+```java
+// housekeeping/SimpleConstructor2.java
+// Constructors can have arguments
+
+class Rock2 {
+ Rock2(int i) {
+ System.out.print("Rock " + i + " ");
+ }
+}
+
+public class SimpleConstructor2 {
+ public static void main(String[] args) {
+ for (int i = 0; i < 8; i++) {
+ new Rock2(i);
+ }
+ }
+}
+```
+
+输出:
+
+```java
+Rock 0 Rock 1 Rock 2 Rock 3 Rock 4 Rock 5 Rock 6 Rock 7
+```
+
+如果类 **Tree** 有一个构造方法,只接收一个参数用来表示树的高度,那么你可以像下面这样创建一棵树:
+
+```java
+Tree t = new Tree(12); // 12-foot 树
+```
+
+如果 **Tree(int)** 是唯一的构造器,那么编译器就不允许你以其他任何方式创建 **Tree** 类型的对象。
+
+构造器消除了一类重要的问题,使得代码更易读。例如,在上面的代码块中,你看不到对 `initialize()` 方法的显式调用,而从概念上来看,`initialize()` 方法应该与对象的创建分离。在 Java 中,对象的创建与初始化是统一的概念,二者不可分割。
+
+构造器没有返回值,它是一种特殊的方法。但它和返回类型为 `void` 的普通方法不同,普通方法可以返回空值,你还能选择让它返回别的类型;而构造器没有返回值,却同时也没有给你选择的余地(`new` 表达式虽然返回了刚创建的对象的引用,但构造器本身却没有返回任何值)。如果它有返回值,并且你也可以自己选择让它返回什么,那么编译器就还得知道接下来该怎么处理那个返回值(这个返回值没有接收者)。
+
+# 4 无参构造器
+
+如前文所说,一个无参构造器就是不接收参数的构造器,用来创建一个"默认的对象"。如果你创建一个类,类中没有构造器,那么编译器就会自动为你创建一个无参构造器。例如:
+
+```java
+// housekeeping/DefaultConstructor.java
+class Bird {}
+public class DefaultConstructor {
+ public static void main(String[] args) {
+ Bird bird = new Bird(); // 默认的
+ }
+}
+```
+
+表达式 `new Bird()` 创建了一个新对象,调用了无参构造器,尽管在 **Bird** 类中并没有显式的定义无参构造器。试想如果没有构造器,我们如何创建一个对象呢。但是,一旦你显式地定义了构造器(无论有参还是无参),编译器就不会自动为你创建无参构造器。如下:
+
+```java
+// housekeeping/NoSynthesis.java
+class Bird2 {
+ Bird2(int i) {}
+ Bird2(double d) {}
+}
+public class NoSynthesis {
+ public static void main(String[] args) {
+ //- Bird2 b = new Bird2(); // No default
+ Bird2 b2 = new Bird2(1);
+ Bird2 b3 = new Bird2(1.0);
+ }
+}
+```
+
+如果你调用了 `new Bird2()` ,编译器会提示找不到匹配的构造器。当类中没有构造器时,编译器会说"你一定需要构造器,那么让我为你创建一个吧"。但是如果类中有构造器,编译器会说"你已经写了构造器了,所以肯定知道你在做什么,如果你没有创建默认构造器,说明你本来就不需要"。
+
+
+
+# 5 this关键字
+
+对于两个相同类型的对象 **a** 和 **b**,你可能在想如何调用这两个对象的 `peel()` 方法:
+
+```java
+// housekeeping/BananaPeel.java
+
+class Banana {
+ void peel(int i) {
+ /*...*/
+ }
+}
+public class BananaPeel {
+ public static void main(String[] args) {
+ Banana a = new Banana(), b = new Banana();
+ a.peel(1);
+ b.peel(2);
+ }
+}
+```
+
+如果只有一个方法 `peel()` ,那么怎么知道调用的是对象 **a** 的 `peel()`方法还是对象 **b** 的 `peel()` 方法呢?编译器做了一些底层工作,所以你可以像这样编写代码。`peel()` 方法中第一个参数隐密地传入了一个指向操作对象的引用。因此,上述例子中的方法调用像下面这样:
+
+```java
+Banana.peel(a, 1)
+Banana.peel(b, 1)
+```
+
+这是在内部实现的,你不可以直接这么编写代码,编译器不会接受,但能说明到底发生了什么。假设现在在方法内部,你想获得对当前对象的引用。但是,对象引用是被秘密地传达给编译器——并不在参数列表中。方便的是,有一个关键字: **this** 。**this** 关键字只能在非静态方法内部使用。当你调用一个对象的方法时,**this** 生成了一个对象引用。你可以像对待其他引用一样对待这个引用。如果你在一个类的方法里调用其他该类中的方法,不要使用 **this**,直接调用即可,**this** 自动地应用于其他方法上了。因此你可以像这样:
+
+```java
+// housekeeping/Apricot.java
+
+public class Apricot {
+ void pick() {
+ /* ... */
+ }
+
+ void pit() {
+ pick();
+ /* ... */
+ }
+}
+```
+
+在 `pit()` 方法中,你可以使用 `this.pick()`,但是没有必要。编译器自动为你做了这些。**this** 关键字只用在一些必须显式使用当前对象引用的特殊场合。例如,用在 **return** 语句中返回对当前对象的引用。
+
+```java
+// housekeeping/Leaf.java
+// Simple use of the "this" keyword
+
+public class Leaf {
+
+ int i = 0;
+
+ Leaf increment() {
+ i++;
+ return this;
+ }
+
+ void print() {
+ System.out.println("i = " + i);
+ }
+
+ public static void main(String[] args) {
+ Leaf x = new Leaf();
+ x.increment().increment().increment().print();
+ }
+}
+```
+
+输出:
+
+```
+i = 3
+```
+
+因为 `increment()` 通过 **this** 关键字返回当前对象的引用,因此在相同的对象上可以轻易地执行多次操作。
+
+**this** 关键字在向其他方法传递当前对象时也很有用:
+
+```java
+// housekeeping/PassingThis.java
+
+class Person {
+ public void eat(Apple apple) {
+ Apple peeled = apple.getPeeled();
+ System.out.println("Yummy");
+ }
+}
+
+public class Peeler {
+ static Apple peel(Apple apple) {
+ // ... remove peel
+ return apple; // Peeled
+ }
+}
+
+public class Apple {
+ Apple getPeeled() {
+ return Peeler.peel(this);
+ }
+}
+
+public class PassingThis {
+ public static void main(String[] args) {
+ new Person().eat(new Apple());
+ }
+}
+```
+
+输出:
+
+```
+Yummy
+```
+
+**Apple** 因为某些原因(比如说工具类中的方法在多个类中重复出现,你不想代码重复),必须调用一个外部工具方法 `Peeler.peel()` 做一些行为。必须使用 **this** 才能将自身传递给外部方法。
+
+### 在构造器中调用构造器
+
+当你在一个类中写了多个构造器,有时你想在一个构造器中调用另一个构造器来避免代码重复。你通过 **this** 关键字实现这样的调用。
+
+通常当你说 **this**,意味着"这个对象"或"当前对象",它本身生成对当前对象的引用。在一个构造器中,当你给 **this** 一个参数列表时,它是另一层意思。它通过最直接的方式显式地调用匹配参数列表的构造器:
+
+```java
+// housekeeping/Flower.java
+// Calling constructors with "this"
+
+public class Flower {
+ int petalCount = 0;
+ String s = "initial value";
+
+ Flower(int petals) {
+ petalCount = petals;
+ System.out.println("Constructor w/ int arg only, petalCount = " + petalCount);
+ }
+
+ Flower(String ss) {
+ System.out.println("Constructor w/ string arg only, s = " + ss);
+ s = ss;
+ }
+
+ Flower(String s, int petals) {
+ this(petals);
+ //- this(s); // Can't call two!
+ this.s = s; // Another use of "this"
+ System.out.println("String & int args");
+ }
+
+ Flower() {
+ this("hi", 47);
+ System.out.println("no-arg constructor");
+ }
+
+ void printPetalCount() {
+ //- this(11); // Not inside constructor!
+ System.out.println("petalCount = " + petalCount + " s = " + s);
+ }
+
+ public static void main(String[] args) {
+ Flower x = new Flower();
+ x.printPetalCount();
+ }
+}
+```
+
+输出:
+
+```
+Constructor w/ int arg only, petalCount = 47
+String & int args
+no-arg constructor
+petalCount = 47 s = hi
+```
+
+从构造器 `Flower(String s, int petals)` 可以看出,其中只能通过 **this** 调用一次构造器。另外,必须首先调用构造器,否则编译器会报错。这个例子同样展示了 **this** 的另一个用法。参数列表中的变量名 **s** 和成员变量名 **s** 相同,会引起混淆。你可以通过 `this.s` 表明你指的是成员变量 **s**,从而避免重复。你经常会在 Java 代码中看到这种用法,同时本书中也会多次出现这种写法。在 `printPetalCount()` 方法中,编译器不允许你在一个构造器之外的方法里调用构造器。
+
+### static 的含义
+
+记住了 **this** 关键字的内容,你会对 **static** 修饰的方法有更加深入的理解:**static** 方法中不会存在 **this**。你不能在静态方法中调用非静态方法(反之可以)。静态方法是为类而创建的,不需要任何对象。事实上,这就是静态方法的主要目的,静态方法看起来就像全局方法一样,但是 Java 中不允许全局方法,一个类中的静态方法可以被其他的静态方法和静态属性访问。一些人认为静态方法不是面向对象的,因为它们的确具有全局方法的语义。使用静态方法,因为不存在 **this**,所以你没有向一个对象发送消息。的确,如果你发现代码中出现了大量的 **static** 方法,就该重新考虑自己的设计了。然而,**static** 的概念很实用,许多时候都要用到它。至于它是否真的"面向对象",就留给理论家去讨论吧。
+
+# 6 清理:Finalization和 GC
+
+程序员都了解初始化的重要性,但通常会忽略清理的重要性。毕竟,谁会去清理一个 **int** 呢?但是使用完一个对象就不管它并非总是安全的。Java 中有垃圾回收器回收无用对象占用的内存。但现在考虑一种特殊情况:你创建的对象不是通过 **new** 来分配内存的,而垃圾回收器只知道如何释放用 **new** 创建的对象的内存,所以它不知道如何回收不是 **new** 分配的内存。为了处理这种情况,Java 允许在类中定义一个名为 `finalize()` 的方法。
+
+它的工作原理"假定"是这样的:当垃圾回收器准备回收对象的内存时,首先会调用其 `finalize()` 方法,并在下一轮的垃圾回收动作发生时,才会真正回收对象占用的内存。所以如果你打算使用 `finalize()` ,就能在垃圾回收时做一些重要的清理工作。`finalize()` 是一个潜在的编程陷阱,因为一些程序员(尤其是 C++ 程序员)会一开始把它误认为是 C++ 中的析构函数(C++ 在销毁对象时会调用这个函数)。所以有必要明确区分一下:在 C++ 中,对象总是被销毁的(在一个 bug-free 的程序中),而在 Java 中,对象并非总是被垃圾回收,或者换句话说:
+
+1. 对象可能不被垃圾回收。
+2. 垃圾回收不等同于析构。
+
+这意味着在你不再需要某个对象之前,如果必须执行某些动作,你得自己去做。Java 没有析构器或类似的概念,所以你必须得自己创建一个普通的方法完成这项清理工作。例如,对象在创建的过程中会将自己绘制到屏幕上。如果不是明确地从屏幕上将其擦除,它可能永远得不到清理。如果在 `finalize()` 方法中加入某种擦除功能,那么当垃圾回收发生时,`finalize()` 方法被调用(不保证一定会发生),图像就会被擦除,要是"垃圾回收"没有发生,图像则仍会保留下来。
+
+也许你会发现,只要程序没有濒临内存用完的那一刻,对象占用的空间就总也得不到释放。如果程序执行结束,而垃圾回收器一直没有释放你创建的任何对象的内存,则当程序退出时,那些资源会全部交还给操作系统。这个策略是恰当的,因为垃圾回收本身也有开销,要是不使用它,那就不用支付这部分开销了。
+
+### `finalize()` 的用途
+
+如果你不能将 `finalize()` 作为通用的清理方法,那么这个方法有什么用呢?
+
+这引入了要记住的第3点:
+
+3. 垃圾回收只与内存有关。
+
+也就是说,使用垃圾回收的唯一原因就是为了回收程序不再使用的内存。所以对于与垃圾回收有关的任何行为来说(尤其是 `finalize()` 方法),它们也必须同内存及其回收有关。
+
+但这是否意味着如果对象中包括其他对象,`finalize()` 方法就应该明确释放那些对象呢?不是,无论对象是如何创建的,垃圾回收器都会负责释放对象所占用的所有内存。这就将对 `finalize()` 的需求限制到一种特殊情况,即通过某种创建对象方式之外的方式为对象分配了存储空间。不过,你可能会想,Java 中万物皆对象,这种情况怎么可能发生?
+
+看起来之所以有 `finalize()` 方法,是因为在分配内存时可能采用了类似 C 语言中的做法,而非 Java 中的通常做法。这种情况主要发生在使用"本地方法"的情况下,本地方法是一种用 Java 语言调用非 Java 语言代码的形式(关于本地方法的讨论,见本书电子版第2版的附录B)。本地方法目前只支持 C 和 C++,但是它们可以调用其他语言写的代码,所以实际上可以调用任何代码。在非 Java 代码中,也许会调用 C 的 `malloc()` 函数系列来分配存储空间,而且除非调用 `free()` 函数,不然存储空间永远得不到释放,造成内存泄露。但是,`free()` 是 C 和 C++ 中的函数,所以你需要在 `finalize()` 方法里用本地方法调用它。
+
+读到这里,你可能明白了不会过多使用 `finalize()` 方法。对,它确实不是进行普通的清理工作的合适场所。那么,普通的清理工作在哪里执行呢?
+
+### 你必须实施清理
+
+要清理一个对象,用户必须在需要清理的时候调用执行清理动作的方法。这听上去相当直接,但却与 C++ 中的"析构函数"的概念稍有抵触。在 C++ 中,所有对象都会被销毁,或者说应该被销毁。如果在 C++ 中创建了一个局部对象(在栈上创建,在 Java 中不行),此时的销毁动作发生在以"右花括号"为边界的、此对象作用域的末尾处。如果对象是用 **new** 创建的(类似于 Java 中),那么当程序员调用 C++ 的 **delete** 操作符时(Java 中不存在),就会调用相应的析构函数。如果程序员忘记调用 **delete**,那么永远不会调用析构函数,这样就会导致内存泄露,对象的其他部分也不会得到清理。这种 bug 很难跟踪,也是让 C++ 程序员转向 Java 的一个主要因素。相反,在 Java 中,没有用于释放对象的 **delete**,因为垃圾回收器会帮助你释放存储空间。甚至可以肤浅地认为,正是由于垃圾回收的存在,使得 Java 没有析构函数。然而,随着学习的深入,你会明白垃圾回收器的存在并不能完全替代析构函数(而且绝对不能直接调用 `finalize()`,所以这也不是一种解决方案)。如果希望进行除释放存储空间之外的清理工作,还是得明确调用某个恰当的 Java 方法:这就等同于使用析构函数了,只是没有它方便。
+
+记住,无论是"垃圾回收"还是"终结",都不保证一定会发生。如果 Java 虚拟机(JVM)并未面临内存耗尽的情形,它可能不会浪费时间执行垃圾回收以恢复内存。
+
+### 终结条件
+
+通常,不能指望 `finalize()` ,你必须创建其他的"清理"方法,并明确地调用它们。所以看起来,`finalize()` 只对大部分程序员很难用到的一些晦涩内存清理里有用了。但是,`finalize()` 还有一个有趣的用法,它不依赖于每次都要对 `finalize()` 进行调用,这就是对象终结条件的验证。
+
+当对某个对象不感兴趣时——也就是它将被清理了,这个对象应该处于某种状态,这种状态下它占用的内存可以被安全地释放掉。例如,如果对象代表了一个打开的文件,在对象被垃圾回收之前程序员应该关闭这个文件。只要对象中存在没有被适当清理的部分,程序就存在很隐晦的 bug。`finalize()` 可以用来最终发现这个情况,尽管它并不总是被调用。如果某次 `finalize()` 的动作使得 bug 被发现,那么就可以据此找出问题所在——这才是人们真正关心的。以下是个简单的例子,示范了 `finalize()` 的可能使用方式:
+
+```java
+// housekeeping/TerminationCondition.java
+// Using finalize() to detect a object that
+// hasn't been properly cleaned up
+
+import onjava.*;
+
+class Book {
+ boolean checkedOut = false;
+
+ Book(boolean checkOut) {
+ checkedOut = checkOut;
+ }
+
+ void checkIn() {
+ checkedOut = false;
+ }
+
+ @Override
+ protected void finalize() throws Throwable {
+ if (checkedOut) {
+ System.out.println("Error: checked out");
+ }
+ // Normally, you'll also do this:
+ // super.finalize(); // Call the base-class version
+ }
+}
+
+public class TerminationCondition {
+
+ public static void main(String[] args) {
+ Book novel = new Book(true);
+ // Proper cleanup:
+ novel.checkIn();
+ // Drop the reference, forget to clean up:
+ new Book(true);
+ // Force garbage collection & finalization:
+ System.gc();
+ new Nap(1); // One second delay
+ }
+
+}
+```
+
+输出:
+
+```
+Error: checked out
+```
+
+本例的终结条件是:所有的 **Book** 对象在被垃圾回收之前必须被登记。但在 `main()` 方法中,有一本书没有登记。要是没有 `finalize()` 方法来验证终结条件,将会很难发现这个 bug。
+
+你可能注意到使用了 `@Override`。`@` 意味着这是一个注解,注解是关于代码的额外信息。在这里,该注解告诉编译器这不是偶然地重定义在每个对象中都存在的 `finalize()` 方法——程序员知道自己在做什么。编译器确保你没有拼错方法名,而且确保那个方法存在于基类中。注解也是对读者的提醒,`@Override` 在 Java 5 引入,在 Java 7 中改善,本书通篇会出现。
+
+注意,`System.gc()` 用于强制进行终结动作。但是即使不这么做,只要重复地执行程序(假设程序将分配大量的存储空间而导致垃圾回收动作的执行),最终也能找出错误的 **Book** 对象。
+
+你应该总是假设基类版本的 `finalize()` 也要做一些重要的事情,使用 **super** 调用它,就像在 `Book.finalize()` 中看到的那样。本例中,它被注释掉了,因为它需要进行异常处理,而我们到现在还没有涉及到。
+
+### 垃圾回收器如何工作
+
+如果你以前用过的语言,在堆上分配对象的代价十分高昂,你可能自然会觉得 Java 中所有对象(基本类型除外)在堆上分配的方式也十分高昂。然而,垃圾回收器能很明显地提高对象的创建速度。这听起来很奇怪——存储空间的释放影响了存储空间的分配,但这确实是某些 Java 虚拟机的工作方式。这也意味着,Java 从堆空间分配的速度可以和其他语言在栈上分配空间的速度相媲美。
+
+例如,你可以把 C++ 里的堆想象成一个院子,里面每个对象都负责管理自己的地盘。一段时间后,对象可能被销毁,但地盘必须复用。在某些 Java 虚拟机中,堆的实现截然不同:它更像一个传送带,每分配一个新对象,它就向前移动一格。这意味着对象存储空间的分配速度特别快。Java 的"堆指针"只是简单地移动到尚未分配的区域,所以它的效率与 C++ 在栈上分配空间的效率相当。当然实际过程中,在簿记工作方面还有少量额外开销,但是这部分开销比不上查找可用空间开销大。
+
+你可能意识到了,Java 中的堆并非完全像传送带那样工作。要是那样的话,势必会导致频繁的内存页面调度——将其移进移出硬盘,因此会显得需要拥有比实际需要更多的内存。页面调度会显著影响性能。最终,在创建了足够多的对象后,内存资源被耗尽。其中的秘密在于垃圾回收器的介入。当它工作时,一边回收内存,一边使堆中的对象紧凑排列,这样"堆指针"就可以很容易地移动到更靠近传送带的开始处,也就尽量避免了页面错误。垃圾回收器通过重新排列对象,实现了一种高速的、有无限空间可分配的堆模型。
+
+要想理解 Java 中的垃圾回收,先了解其他系统中的垃圾回收机制将会很有帮助。一种简单但速度很慢的垃圾回收机制叫做*引用计数*。每个对象中含有一个引用计数器,每当有引用指向该对象时,引用计数加 1。当引用离开作用域或被置为 **null** 时,引用计数减 1。因此,管理引用计数是一个开销不大但是在程序的整个生命周期频繁发生的负担。垃圾回收器会遍历含有全部对象的列表,当发现某个对象的引用计数为 0 时,就释放其占用的空间(但是,引用计数模式经常会在计数为 0 时立即释放对象)。这个机制存在一个缺点:如果对象之间存在循环引用,那么它们的引用计数都不为 0,就会出现应该被回收但无法被回收的情况。对垃圾回收器而言,定位这样的循环引用所需的工作量极大。引用计数常用来说明垃圾回收的工作方式,但似乎从未被应用于任何一种 Java 虚拟机实现中。
+
+在更快的策略中,垃圾回收器并非基于引用计数。它们依据的是:对于任意"活"的对象,一定能最终追溯到其存活在栈或静态存储区中的引用。这个引用链条可能会穿过数个对象层次,由此,如果从栈或静态存储区出发,遍历所有的引用,你将会发现所有"活"的对象。对于发现的每个引用,必须追踪它所引用的对象,然后是该对象包含的所有引用,如此反复进行,直到访问完"根源于栈或静态存储区的引用"所形成的整个网络。你所访问过的对象一定是"活"的。注意,这解决了对象间循环引用的问题,这些对象不会被发现,因此也就被自动回收了。
+
+在这种方式下,Java 虚拟机采用了一种*自适应*的垃圾回收技术。至于如何处理找到的存活对象,取决于不同的 Java 虚拟机实现。其中有一种做法叫做停止-复制(stop-and-copy)。顾名思义,这需要先暂停程序的运行(不属于后台回收模式),然后将所有存活的对象从当前堆复制到另一个堆,没有复制的就是需要被垃圾回收的。另外,当对象被复制到新堆时,它们是一个挨着一个紧凑排列,然后就可以按照前面描述的那样简单、直接地分配新空间了。
+
+当对象从一处复制到另一处,所有指向它的引用都必须修正。位于栈或静态存储区的引用可以直接被修正,但可能还有其他指向这些对象的引用,它们在遍历的过程中才能被找到(可以想象成一个表格,将旧地址映射到新地址)。
+
+这种所谓的"复制回收器"效率低下主要因为两个原因。其一:得有两个堆,然后在这两个分离的堆之间来回折腾,得维护比实际需要多一倍的空间。某些 Java 虚拟机对此问题的处理方式是,按需从堆中分配几块较大的内存,复制动作发生在这些大块内存之间。
+
+其二在于复制本身。一旦程序进入稳定状态之后,可能只会产生少量垃圾,甚至没有垃圾。尽管如此,复制回收器仍然会将所有内存从一处复制到另一处,这很浪费。为了避免这种状况,一些 Java 虚拟机会进行检查:要是没有新垃圾产生,就会转换到另一种模式(即"自适应")。这种模式称为标记-清扫(mark-and-sweep),Sun 公司早期版本的 Java 虚拟机一直使用这种技术。对一般用途而言,"标记-清扫"方式速度相当慢,但是当你知道程序只会产生少量垃圾甚至不产生垃圾时,它的速度就很快了。
+
+"标记-清扫"所依据的思路仍然是从栈和静态存储区出发,遍历所有的引用,找出所有存活的对象。但是,每当找到一个存活对象,就给对象设一个标记,并不回收它。只有当标记过程完成后,清理动作才开始。在清理过程中,没有标记的对象将被释放,不会发生任何复制动作。"标记-清扫"后剩下的堆空间是不连续的,垃圾回收器要是希望得到连续空间的话,就需要重新整理剩下的对象。
+
+"停止-复制"指的是这种垃圾回收动作不是在后台进行的;相反,垃圾回收动作发生的同时,程序将会暂停。在 Oracle 公司的文档中会发现,许多参考文献将垃圾回收视为低优先级的后台进程,但是早期版本的 Java 虚拟机并不是这么实现垃圾回收器的。当可用内存较低时,垃圾回收器会暂停程序。同样,"标记-清扫"工作也必须在程序暂停的情况下才能进行。
+
+如前文所述,这里讨论的 Java 虚拟机中,内存分配以较大的"块"为单位。如果对象较大,它会占用单独的块。严格来说,"停止-复制"要求在释放旧对象之前,必须先将所有存活对象从旧堆复制到新堆,这导致了大量的内存复制行为。有了块,垃圾回收器就可以把对象复制到废弃的块。每个块都有年代数来记录自己是否存活。通常,如果块在某处被引用,其年代数加 1,垃圾回收器会对上次回收动作之后新分配的块进行整理。这对处理大量短命的临时对象很有帮助。垃圾回收器会定期进行完整的清理动作——大型对象仍然不会复制(只是年代数会增加),含有小型对象的那些块则被复制并整理。Java 虚拟机会监视,如果所有对象都很稳定,垃圾回收的效率降低的话,就切换到"标记-清扫"方式。同样,Java 虚拟机会跟踪"标记-清扫"的效果,如果堆空间出现很多碎片,就会切换回"停止-复制"方式。这就是"自适应"的由来,你可以给它个啰嗦的称呼:"自适应的、分代的、停止-复制、标记-清扫"式的垃圾回收器。
+
+Java 虚拟机中有许多附加技术用来提升速度。尤其是与加载器操作有关的,被称为"即时"(Just-In-Time, JIT)编译器的技术。这种技术可以把程序全部或部分翻译成本地机器码,所以不需要 JVM 来进行翻译,因此运行得更快。当需要装载某个类(通常是创建该类的第一个对象)时,编译器会先找到其 **.class** 文件,然后将该类的字节码装入内存。你可以让即时编译器编译所有代码,但这种做法有两个缺点:一是这种加载动作贯穿整个程序生命周期内,累加起来需要花更多时间;二是会增加可执行代码的长度(字节码要比即时编译器展开后的本地机器码小很多),这会导致页面调度,从而一定降低程序速度。另一种做法称为*惰性评估*,意味着即时编译器只有在必要的时候才编译代码。这样,从未被执行的代码也许就压根不会被 JIT 编译。新版 JDK 中的 Java HotSpot 技术就采用了类似的做法,代码每被执行一次就优化一些,所以执行的次数越多,它的速度就越快。
+
+
+
+# 7 成员初始化
+
+Java 尽量保证所有变量在使用前都能得到恰当的初始化。对于方法的局部变量,这种保证会以编译时错误的方式呈现,所以如果写成:
+
+```java
+void f() {
+ int i;
+ i++;
+}
+```
+
+你会得到一条错误信息,告诉你 **i** 可能尚未初始化。编译器可以为 **i** 赋一个默认值,但是未初始化的局部变量更有可能是程序员的疏忽,所以采用默认值反而会掩盖这种失误。强制程序员提供一个初始值,往往能帮助找出程序里的 bug。
+
+要是类的成员变量是基本类型,情况就会变得有些不同。正如在"万物皆对象"一章中所看到的,类的每个基本类型数据成员保证都会有一个初始值。下面的程序可以验证这类情况,并显示它们的值:
+
+```java
+// housekeeping/InitialValues.java
+// Shows default initial values
+
+public class InitialValues {
+ boolean t;
+ char c;
+ byte b;
+ short s;
+ int i;
+ long l;
+ float f;
+ double d;
+ InitialValues reference;
+
+ void printInitialValues() {
+ System.out.println("Data type Initial value");
+ System.out.println("boolean " + t);
+ System.out.println("char[" + c + "]");
+ System.out.println("byte " + b);
+ System.out.println("short " + s);
+ System.out.println("int " + i);
+ System.out.println("long " + l);
+ System.out.println("float " + f);
+ System.out.println("double " + d);
+ System.out.println("reference " + reference);
+ }
+
+ public static void main(String[] args) {
+ new InitialValues().printInitialValues();
+ }
+}
+```
+
+输出:
+
+```Java
+Data type Initial value
+boolean false
+char[NUL]
+byte 0
+short 0
+int 0
+long 0
+float 0.0
+double 0.0
+reference null
+```
+
+可见尽管数据成员的初值没有给出,但它们确实有初值(char 值为 0,所以显示为空白)。所以这样至少不会出现"未初始化变量"的风险了。
+
+在类里定义一个对象引用时,如果不将其初始化,那么引用就会被赋值为 **null**。
+
+### 指定初始化
+
+怎么给一个变量赋初值呢?一种很直接的方法是在定义类成员变量的地方为其赋值。以下代码修改了 InitialValues 类成员变量的定义,直接提供了初值:
+
+```java
+// housekeeping/InitialValues2.java
+// Providing explicit initial values
+
+public class InitialValues2 {
+ boolean bool = true;
+ char ch = 'x';
+ byte b = 47;
+ short s = 0xff;
+ int i = 999;
+ long lng = 1;
+ float f = 3.14f;
+ double d = 3.14159;
+}
+```
+
+你也可以用同样的方式初始化非基本类型的对象。如果 **Depth** 是一个类,那么可以像下面这样创建一个对象并初始化它:
+
+```java
+// housekeeping/Measurement.java
+
+class Depth {}
+
+public class Measurement {
+ Depth d = new Depth();
+ // ...
+}
+```
+
+如果没有为 **d** 赋予初值就尝试使用它,就会出现运行时错误,告诉你产生了一个异常(详细见"异常"章节)。
+
+你也可以通过调用某个方法来提供初值:
+
+```java
+// housekeeping/MethodInit.java
+
+public class MethodInit {
+ int i = f();
+
+ int f() {
+ return 11;
+ }
+
+}
+```
+
+这个方法可以带有参数,但这些参数不能是未初始化的类成员变量。因此,可以这么写:
+
+```java
+// housekeeping/MethodInit2.java
+
+public class MethodInit2 {
+ int i = f();
+ int j = g(i);
+
+ int f() {
+ return 11;
+ }
+
+ int g(int n) {
+ return n * 10;
+ }
+}
+```
+
+但是你不能这么写:
+
+```java
+// housekeeping/MethodInit3.java
+
+public class MethodInit3 {
+ //- int j = g(i); // Illegal forward reference
+ int i = f();
+
+ int f() {
+ return 11;
+ }
+
+ int g(int n) {
+ return n * 10;
+ }
+}
+```
+
+显然,上述程序的正确性取决于初始化的顺序,而与其编译方式无关。所以,编译器恰当地对"向前引用"发出了警告。
+
+这种初始化方式简单直观,但有个限制:类 **InitialValues** 的每个对象都有相同的初值,有时这的确是我们需要的,但有时却需要更大的灵活性。
+
+
+
+# 8 构造器初始化
+
+可以用构造器进行初始化,这种方式给了你更大的灵活性,因为你可以在运行时调用方法进行初始化。但是,这无法阻止自动初始化的进行,他会在构造器被调用之前发生。因此,如果使用如下代码:
+
+```java
+// housekeeping/Counter.java
+
+public class Counter {
+ int i;
+
+ Counter() {
+ i = 7;
+ }
+ // ...
+}
+```
+
+**i** 首先会被初始化为 **0**,然后变为 **7**。对于所有的基本类型和引用,包括在定义时已明确指定初值的变量,这种情况都是成立的。因此,编译器不会强制你一定要在构造器的某个地方或在使用它们之前初始化元素——初始化早已得到了保证。,
+
+### 初始化的顺序
+
+在类中变量定义的顺序决定了它们初始化的顺序。即使变量定义散布在方法定义之间,它们仍会在任何方法(包括构造器)被调用之前得到初始化。例如:
+
+```java
+// housekeeping/OrderOfInitialization.java
+// Demonstrates initialization order
+// When the constructor is called to create a
+// Window object, you'll see a message:
+
+class Window {
+ Window(int marker) {
+ System.out.println("Window(" + marker + ")");
+ }
+}
+
+class House {
+ Window w1 = new Window(1); // Before constructor
+
+ House() {
+ // Show that we're in the constructor:
+ System.out.println("House()");
+ w3 = new Window(33); // Reinitialize w3
+ }
+
+ Window w2 = new Window(2); // After constructor
+
+ void f() {
+ System.out.println("f()");
+ }
+
+ Window w3 = new Window(3); // At end
+}
+
+public class OrderOfInitialization {
+ public static void main(String[] args) {
+ House h = new House();
+ h.f(); // Shows that construction is done
+ }
+}
+```
+
+输出:
+
+```
+Window(1)
+Window(2)
+Window(3)
+House()
+Window(33)
+f()
+```
+
+在 **House** 类中,故意把几个 **Window** 对象的定义散布在各处,以证明它们全都会在调用构造器或其他方法之前得到初始化。此外,**w3** 在构造器中被再次赋值。
+
+由输出可见,引用 **w3** 被初始化了两次:一次在调用构造器前,一次在构造器调用期间(第一次引用的对象将被丢弃,并作为垃圾回收)。这乍一看可能觉得效率不高,但保证了正确的初始化。试想,如果定义了一个重载构造器,在其中没有初始化 **w3**,同时在定义 **w3** 时没有赋予初值,那会产生怎样的后果呢?
+
+### 静态数据的初始化
+
+无论创建多少个对象,静态数据都只占用一份存储区域。**static** 关键字不能应用于局部变量,所以只能作用于属性。如果一个字段是静态的基本类型,你没有初始化它,那么它就会获得基本类型的标准初值。如果它是对象引用,那么它的默认初值就是 **null**。
+
+如果在定义时进行初始化,那么静态变量看起来就跟非静态变量一样。
+
+下面例子显示了静态存储区是何时初始化的:
+
+```java
+// housekeeping/StaticInitialization.java
+// Specifying initial values in a class definition
+
+class Bowl {
+ Bowl(int marker) {
+ System.out.println("Bowl(" + marker + ")");
+ }
+
+ void f1(int marker) {
+ System.out.println("f1(" + marker + ")");
+ }
+}
+
+class Table {
+ static Bowl bowl1 = new Bowl(1);
+
+ Table() {
+ System.out.println("Table()");
+ bowl2.f1(1);
+ }
+
+ void f2(int marker) {
+ System.out.println("f2(" + marker + ")");
+ }
+
+ static Bowl bowl2 = new Bowl(2);
+}
+
+class Cupboard {
+ Bowl bowl3 = new Bowl(3);
+ static Bowl bowl4 = new Bowl(4);
+
+ Cupboard() {
+ System.out.println("Cupboard()");
+ bowl4.f1(2);
+ }
+
+ void f3(int marker) {
+ System.out.println("f3(" + marker + ")");
+ }
+
+ static Bowl bowl5 = new Bowl(5);
+}
+
+public class StaticInitialization {
+ public static void main(String[] args) {
+ System.out.println("main creating new Cupboard()");
+ new Cupboard();
+ System.out.println("main creating new Cupboard()");
+ new Cupboard();
+ table.f2(1);
+ cupboard.f3(1);
+ }
+
+ static Table table = new Table();
+ static Cupboard cupboard = new Cupboard();
+}
+```
+
+输出:
+
+```
+Bowl(1)
+Bowl(2)
+Table()
+f1(1)
+Bowl(4)
+Bowl(5)
+Bowl(3)
+Cupboard()
+f1(2)
+main creating new Cupboard()
+Bowl(3)
+Cupboard()
+f1(2)
+main creating new Cupboard()
+Bowl(3)
+Cupboard()
+f1(2)
+f2(1)
+f3(1)
+```
+
+**Bowl** 类展示类的创建,而 **Table** 和 **Cupboard** 在它们的类定义中包含 **Bowl** 类型的静态数据成员。注意,在静态数据成员定义之前,**Cupboard** 类中先定义了一个 **Bowl** 类型的非静态成员 **b3**。
+
+由输出可见,静态初始化只有在必要时刻才会进行。如果不创建 **Table** 对象,也不引用 **Table.bowl1** 或 **Table.bowl2**,那么静态的 **Bowl** 类对象 **bowl1** 和 **bowl2** 永远不会被创建。只有在第一个 Table 对象被创建(或被访问)时,它们才会被初始化。此后,静态对象不会再次被初始化。
+
+初始化的顺序先是静态对象(如果它们之前没有被初始化的话),然后是非静态对象,从输出中可以看出。要执行 `main()` 方法,必须加载 **StaticInitialization** 类,它的静态属性 **table** 和 **cupboard** 随后被初始化,这会导致它们对应的类也被加载,而由于它们都包含静态的 **Bowl** 对象,所以 **Bowl** 类也会被加载。因此,在这个特殊的程序中,所有的类都会在 `main()` 方法之前被加载。实际情况通常并非如此,因为在典型的程序中,不会像本例中所示的那样,将所有事物通过 **static** 联系起来。
+
+概括一下创建对象的过程,假设有个名为 **Dog** 的类:
+
+1. 即使没有显式地使用 **static** 关键字,构造器实际上也是静态方法。所以,当首次创建 **Dog** 类型的对象或是首次访问 **Dog** 类的静态方法或属性时,Java 解释器必须在类路径中查找,以定位 **Dog.class**。
+2. 当加载完 **Dog.class** 后(后面会学到,这将创建一个 **Class** 对象),有关静态初始化的所有动作都会执行。因此,静态初始化只会在首次加载 **Class** 对象时初始化一次。
+3. 当用 `new Dog()` 创建对象时,首先会在堆上为 **Dog** 对象分配足够的存储空间。
+4. 分配的存储空间首先会被清零,即会将 **Dog** 对象中的所有基本类型数据设置为默认值(数字会被置为 0,布尔型和字符型也相同),引用被置为 **null**。
+5. 执行所有出现在字段定义处的初始化动作。
+6. 执行构造器。你将会在"复用"这一章看到,这可能会牵涉到很多动作,尤其当涉及继承的时候。
+
+### 显式的静态初始化
+
+你可以将一组静态初始化动作放在类里面一个特殊的"静态子句"(有时叫做静态块)中。像下面这样:
+
+```java
+// housekeeping/Spoon.java
+
+public class Spoon {
+ static int i;
+
+ static {
+ i = 47;
+ }
+}
+```
+
+这看起来像个方法,但实际上它只是一段跟在 **static** 关键字后面的代码块。与其他静态初始化动作一样,这段代码仅执行一次:当首次创建这个类的对象或首次访问这个类的静态成员(甚至不需要创建该类的对象)时。例如:
+
+```java
+// housekeeping/ExplicitStatic.java
+// Explicit static initialization with "static" clause
+
+class Cup {
+ Cup(int marker) {
+ System.out.println("Cup(" + marker + ")");
+ }
+
+ void f(int marker) {
+ System.out.println("f(" + marker + ")");
+ }
+}
+
+class Cups {
+ static Cup cup1;
+ static Cup cup2;
+
+ static {
+ cup1 = new Cup(1);
+ cup2 = new Cup(2);
+ }
+
+ Cups() {
+ System.out.println("Cups()");
+ }
+}
+
+public class ExplicitStatic {
+ public static void main(String[] args) {
+ System.out.println("Inside main()");
+ Cups.cup1.f(99); // [1]
+ }
+
+ // static Cups cups1 = new Cups(); // [2]
+ // static Cups cups2 = new Cups(); // [2]
+}
+```
+
+输出:
+
+```
+Inside main
+Cup(1)
+Cup(2)
+f(99)
+```
+
+无论是通过标为 [1] 的行访问静态的 **cup1** 对象,还是把标为 [1] 的行去掉,让它去运行标为 [2] 的那行代码(去掉 [2] 的注释),**Cups** 的静态初始化动作都会执行。如果同时注释 [1] 和 [2] 处,那么 **Cups** 的静态初始化就不会进行。此外,把标为 [2] 处的注释都去掉还是只去掉一个,静态初始化只会执行一次。
+
+### 非静态实例初始化
+
+Java 提供了被称为*实例初始化*的类似语法,用来初始化每个对象的非静态变量,例如:
+
+```java
+// housekeeping/Mugs.java
+// Instance initialization
+
+class Mug {
+ Mug(int marker) {
+ System.out.println("Mug(" + marker + ")");
+ }
+}
+
+public class Mugs {
+ Mug mug1;
+ Mug mug2;
+ { // [1]
+ mug1 = new Mug(1);
+ mug2 = new Mug(2);
+ System.out.println("mug1 & mug2 initialized");
+ }
+
+ Mugs() {
+ System.out.println("Mugs()");
+ }
+
+ Mugs(int i) {
+ System.out.println("Mugs(int)");
+ }
+
+ public static void main(String[] args) {
+ System.out.println("Inside main()");
+ new Mugs();
+ System.out.println("new Mugs() completed");
+ new Mugs(1);
+ System.out.println("new Mugs(1) completed");
+ }
+}
+```
+
+输出:
+
+```
+Inside main
+Mug(1)
+Mug(2)
+mug1 & mug2 initialized
+Mugs()
+new Mugs() completed
+Mug(1)
+Mug(2)
+mug1 & mug2 initialized
+Mugs(int)
+new Mugs(1) completed
+```
+
+看起来它很像静态代码块,只不过少了 **static** 关键字。这种语法对于支持"匿名内部类"(参见"内部类"一章)的初始化是必须的,但是你也可以使用它保证某些操作一定会发生,而不管哪个构造器被调用。从输出看出,实例初始化子句是在两个构造器之前执行的。
+
+
+
+# 9 数组初始化
+
+数组是相同类型的、用一个标识符名称封装到一起的一个对象序列或基本类型数据序列。数组是通过方括号下标操作符 [] 来定义和使用的。要定义一个数组引用,只需要在类型名加上方括号:
+
+```java
+int[] a1;
+```
+
+方括号也可放在标识符的后面,两者的含义是一样的:
+
+```java
+int a1[];
+```
+
+这种格式符合 C 和 C++ 程序员的习惯。不过前一种格式或许更合理,毕竟它表明类型是"一个 **int** 型数组"。本书中采用这种格式。
+
+编译器不允许指定数组的大小。这又把我们带回有关"引用"的问题上。你所拥有的只是对数组的一个引用(你已经为该引用分配了足够的存储空间),但是还没有给数组对象本身分配任何空间。为了给数组创建相应的存储空间,必须写初始化表达式。对于数组,初始化动作可以出现在代码的任何地方,但是也可以使用一种特殊的初始化表达式,它必须在创建数组的地方出现。这种特殊的初始化是由一对花括号括起来的值组成。这种情况下,存储空间的分配(相当于使用 **new**) 将由编译器负责。例如:
+
+```java
+int[] a1 = {1, 2, 3, 4, 5};
+```
+
+那么为什么在还没有数组的时候定义一个数组引用呢?
+
+```java
+int[] a2;
+```
+
+在 Java 中可以将一个数组赋值给另一个数组,所以可以这样:
+
+```java
+a2 = a1;
+```
+
+其实真正做的只是复制了一个引用,就像下面演示的这样:
+
+```java
+// housekeeping/ArraysOfPrimitives.java
+
+public class ArraysOfPrimitives {
+ public static void main(String[] args) {
+ int[] a1 = {1, 2, 3, 4, 5};
+ int[] a2;
+ a2 = a1;
+ for (int i = 0; i < a2.length; i++) {
+ a2[i] += 1;
+ }
+ for (int i = 0; i < a1.length; i++) {
+ System.out.println("a1[" + i + "] = " + a1[i]);
+ }
+ }
+}
+```
+
+输出:
+
+```
+a1[0] = 2;
+a1[1] = 3;
+a1[2] = 4;
+a1[3] = 5;
+a1[4] = 6;
+```
+
+**a1** 初始化了,但是 **a2** 没有;这里,**a2** 在后面被赋给另一个数组。由于 **a1** 和 **a2** 是相同数组的别名,因此通过 **a2** 所做的修改在 **a1** 中也能看到。
+
+所有的数组(无论是对象数组还是基本类型数组)都有一个固定成员 **length**,告诉你这个数组有多少个元素,你不能对其修改。与 C 和 C++ 类似,Java 数组计数也是从 0 开始的,所能使用的最大下标数是 **length - 1**。超过这个边界,C 和 C++ 会默认接受,允许你访问所有内存,许多声名狼藉的 bug 都是由此而生。但是 Java 在你访问超出这个边界时,会报运行时错误(异常),从而避免此类问题。
+
+### 动态数组创建
+
+如果在编写程序时,不确定数组中需要多少个元素,那么该怎么办呢?你可以直接使用 **new** 在数组中创建元素。下面例子中,尽管创建的是基本类型数组,**new** 仍然可以工作(不能用 **new** 创建单个的基本类型数组):
+
+```java
+// housekeeping/ArrayNew.java
+// Creating arrays with new
+import java.util.*;
+
+public class ArrayNew {
+ public static void main(String[] args) {
+ int[] a;
+ Random rand = new Random(47);
+ a = new int[rand.nextInt(20)];
+ System.out.println("length of a = " + a.length);
+ System.out.println(Arrays.toString(a));
+ }
+}
+```
+
+输出:
+
+```
+length of a = 18
+[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
+```
+
+数组的大小是通过 `Random.nextInt()` 随机确定的,这个方法会返回 0 到输入参数之间的一个值。 由于随机性,很明显数组的创建确实是在运行时进行的。此外,程序输出表明,数组元素中的基本数据类型值会自动初始化为空值(对于数字和字符是 0;对于布尔型是 **false**)。`Arrays.toString()` 是 **java.util** 标准类库中的方法,会产生一维数组的可打印版本。
+
+本例中,数组也可以在定义的同时进行初始化:
+
+```java
+int[] a = new int[rand.nextInt(20)];
+```
+
+如果可能的话,应该尽量这么做。
+
+如果你创建了一个非基本类型的数组,那么你创建的是一个引用数组。以整型的包装类型 **Integer** 为例,它是一个类而非基本类型:
+
+```java
+// housekeeping/ArrayClassObj.java
+// Creating an array of nonprimitive objects
+
+import java.util.*;
+
+public class ArrayClassObj {
+ public static void main(String[] args) {
+ Random rand = new Random(47);
+ Integer[] a = new Integer[rand.nextInt(20)];
+ System.out.println("length of a = " + a.length);
+ for (int i = 0; i < a.length; i++) {
+ a[i] = rand.nextInt(500); // Autoboxing
+ }
+ System.out.println(Arrays.toString(a));
+ }
+}
+```
+
+输出:
+
+```
+length of a = 18
+[55, 193, 361, 461, 429, 368, 200, 22, 207, 288, 128, 51, 89, 309, 278, 498, 361, 20]
+```
+
+这里,即使使用 new 创建数组之后:
+
+```java
+Integer[] a = new Integer[rand.nextInt(20)];
+```
+
+它只是一个引用数组,直到通过创建新的 **Integer** 对象(通过自动装箱),并把对象赋值给引用,初始化才算结束:
+
+```java
+a[i] = rand.nextInt(500);
+```
+
+如果忘记了创建对象,但试图使用数组中的空引用,就会在运行时产生异常。
+
+也可以用花括号括起来的列表来初始化数组,有两种形式:
+
+```java
+// housekeeping/ArrayInit.java
+// Array initialization
+import java.util.*;
+
+public class ArrayInit {
+ public static void main(String[] args) {
+ Integer[] a = {
+ 1, 2,
+ 3, // Autoboxing
+ };
+ Integer[] b = new Integer[] {
+ 1, 2,
+ 3, // Autoboxing
+ };
+ System.out.println(Arrays.toString(a));
+ System.out.println(Arrays.toString(b));
+
+ }
+}
+```
+
+输出:
+
+```
+[1, 2, 3]
+[1, 2, 3]
+```
+
+在这两种形式中,初始化列表的最后一个逗号是可选的(这一特性使维护长列表变得更容易)。
+
+尽管第一种形式很有用,但是它更加受限,因为它只能用于数组定义处。第二种和第三种形式可以用在任何地方,甚至用在方法的内部。例如,你创建了一个 **String** 数组,将其传递给另一个类的 `main()` 方法,如下:
+
+```java
+// housekeeping/DynamicArray.java
+// Array initialization
+
+public class DynamicArray {
+ public static void main(String[] args) {
+ Other.main(new String[] {"fiddle", "de", "dum"});
+ }
+}
+
+class Other {
+ public static void main(String[] args) {
+ for (String s: args) {
+ System.out.print(s + " ");
+ }
+ }
+}
+```
+
+输出:
+
+```
+fiddle de dum
+```
+
+`Other.main()` 的参数是在调用处创建的,因此你甚至可以在方法调用处提供可替换的参数。
+
+### 可变参数列表
+
+你可以以一种类似 C 语言中的可变参数列表(C 通常把它称为"varargs")来创建和调用方法。这可以应用在参数个数或类型未知的场合。由于所有的类都最后继承于 **Object** 类(随着本书的进展,你会对此有更深的认识),所以你可以创建一个以 Object 数组为参数的方法,并像下面这样调用:
+
+```java
+// housekeeping/VarArgs.java
+// Using array syntax to create variable argument lists
+
+class A {}
+
+public class VarArgs {
+ static void printArray(Object[] args) {
+ for (Object obj: args) {
+ System.out.print(obj + " ");
+ }
+ System.out.println();
+ }
+
+ public static void main(String[] args) {
+ printArray(new Object[] {47, (float) 3.14, 11.11});
+ printArray(new Object[] {"one", "two", "three"});
+ printArray(new Object[] {new A(), new A(), new A()});
+ }
+}
+```
+
+输出:
+
+```
+47 3.14 11.11
+one two three
+A@15db9742 A@6d06d69c A@7852e922
+```
+
+`printArray()` 的参数是 **Object** 数组,使用 for-in 语法遍历和打印数组的每一项。标准 Java 库能输出有意义的内容,但这里创建的是类的对象,打印出的内容是类名,后面跟着一个 **@** 符号以及多个十六进制数字。因而,默认行为(如果没有定义 `toString()` 方法的话,后面会讲这个方法)就是打印类名和对象的地址。
+
+你可能看到像上面这样编写的 Java 5 之前的代码,它们可以产生可变的参数列表。在 Java 5 中,这种期盼已久的特性终于添加了进来,就像在 `printArray()` 中看到的那样:
+
+```java
+// housekeeping/NewVarArgs.java
+// Using array syntax to create variable argument lists
+
+public class NewVarArgs {
+ static void printArray(Object... args) {
+ for (Object obj: args) {
+ System.out.print(obj + " ");
+ }
+ System.out.println();
+ }
+
+ public static void main(String[] args) {
+ // Can take individual elements:
+ printArray(47, (float) 3.14, 11.11);
+ printArray(47, 3.14F, 11.11);
+ printArray("one", "two", "three");
+ printArray(new A(), new A(), new A());
+ // Or an array:
+ printArray((Object[]) new Integer[] {1, 2, 3, 4});
+ printArray(); // Empty list is OK
+ }
+}
+```
+
+输出:
+
+```
+47 3.14 11.11
+47 3.14 11.11
+one two three
+A@15db9742 A@6d06d69c A@7852e922
+1 2 3 4
+```
+
+有了可变参数,你就再也不用显式地编写数组语法了,当你指定参数时,编译器实际上会为你填充数组。你获取的仍然是一个数组,这就是为什么 `printArray()` 可以使用 for-in 迭代数组的原因。但是,这不仅仅只是从元素列表到数组的自动转换。注意程序的倒数第二行,一个 **Integer** 数组(通过自动装箱创建)被转型为一个 **Object** 数组(为了移除编译器的警告),并且传递给了 `printArray()`。显然,编译器会发现这是一个数组,不会执行转换。因此,如果你有一组事物,可以把它们当作列表传递,而如果你已经有了一个数组,该方法会把它们当作可变参数列表来接受。
+
+程序的最后一行表明,可变参数的个数可以为 0。当具有可选的尾随参数时,这一特性会有帮助:
+
+```java
+// housekeeping/OptionalTrailingArguments.java
+
+public class OptionalTrailingArguments {
+ static void f(int required, String... trailing) {
+ System.out.print("required: " + required + " ");
+ for (String s: trailing) {
+ System.out.print(s + " ");
+ }
+ System.out.println();
+ }
+
+ public static void main(String[] args) {
+ f(1, "one");
+ f(2, "two", "three");
+ f(0);
+ }
+}
+```
+
+输出:
+
+```
+required: 1 one
+required: 2 two three
+required: 0
+```
+
+这段程序展示了如何使用除了 **Object** 类之外类型的可变参数列表。这里,所有的可变参数都是 **String** 对象。可变参数列表中可以使用任何类型的参数,包括基本类型。下面例子展示了可变参数列表变为数组的情形,并且如果列表中没有任何元素,那么转变为大小为 0 的数组:
+
+```java
+// housekeeping/VarargType.java
+
+public class VarargType {
+ static void f(Character... args) {
+ System.out.print(args.getClass());
+ System.out.println(" length " + args.length);
+ }
+
+ static void g(int... args) {
+ System.out.print(args.getClass());
+ System.out.println(" length " + args.length)
+ }
+
+ public static void main(String[] args) {
+ f('a');
+ f();
+ g(1);
+ g();
+ System.out.println("int[]: "+ new int[0].getClass());
+ }
+}
+```
+
+输出:
+
+```
+class [Ljava.lang.Character; length 1
+class [Ljava.lang.Character; length 0
+class [I length 1
+class [I length 0
+int[]: class [I
+```
+
+`getClass()` 方法属于 Object 类,将在"类型信息"一章中全面介绍。它会产生对象的类,并在打印该类时,看到表示该类类型的编码字符串。前导的 **[** 代表这是一个后面紧随的类型的数组,**I** 表示基本类型 **int**;为了进行双重检查,我在最后一行创建了一个 **int** 数组,打印了其类型。这样也验证了使用可变参数列表不依赖于自动装箱,而使用的是基本类型。
+
+然而,可变参数列表与自动装箱可以和谐共处,如下:
+
+```java
+// housekeeping/AutoboxingVarargs.java
+
+public class AutoboxingVarargs {
+ public static void f(Integer... args) {
+ for (Integer i: args) {
+ System.out.print(i + " ");
+ }
+ System.out.println();
+ }
+
+ public static void main(String[] args) {
+ f(1, 2);
+ f(4, 5, 6, 7, 8, 9);
+ f(10, 11, 12);
+
+ }
+}
+```
+
+输出:
+
+```
+1 2
+4 5 6 7 8 9
+10 11 12
+```
+
+注意吗,你可以在单个参数列表中将类型混合在一起,自动装箱机制会有选择地把 **int** 类型的参数提升为 **Integer**。
+
+可变参数列表使得方法重载更加复杂了,尽管乍看之下似乎足够安全:
+
+```java
+// housekeeping/OverloadingVarargs.java
+
+public class OverloadingVarargs {
+ static void f(Character... args) {
+ System.out.print("first");
+ for (Character c: args) {
+ System.out.print(" " + c);
+ }
+ System.out.println();
+ }
+
+ static void f(Integer... args) {
+ System.out.print("second");
+ for (Integer i: args) {
+ System.out.print(" " + i);
+ }
+ System.out.println();
+ }
+
+ static void f(Long... args) {
+ System.out.println("third");
+ }
+
+ public static void main(String[] args) {
+ f('a', 'b', 'c');
+ f(1);
+ f(2, 1);
+ f(0);
+ f(0L);
+ //- f(); // Won's compile -- ambiguous
+ }
+}
+```
+
+输出:
+
+```
+first a b c
+second 1
+second 2 1
+second 0
+third
+```
+
+在每种情况下,编译器都会使用自动装箱来匹配重载的方法,然后调用最明确匹配的方法。
+
+但是如果调用不含参数的 `f()`,编译器就无法知道应该调用哪个方法了。尽管这个错误可以弄清楚,但是它可能会使客户端程序员感到意外。
+
+你可能会通过在某个方法中增加一个非可变参数解决这个问题:
+
+```java
+// housekeeping/OverloadingVarargs2.java
+// {WillNotCompile}
+
+public class OverloadingVarargs2 {
+ static void f(float i, Character... args) {
+ System.out.println("first");
+ }
+
+ static void f(Character... args) {
+ System.out.println("second");
+ }
+
+ public static void main(String[] args) {
+ f(1, 'a');
+ f('a', 'b');
+ }
+}
+```
+
+**{WillNotCompile}** 注释把该文件排除在了本书的 Gradle 构建之外。如果你手动编译它,会得到下面的错误信息:
+
+```
+OverloadingVarargs2.java:14:error:reference to f is ambiguous f('a', 'b');
+\^
+both method f(float, Character...) in OverloadingVarargs2 and method f(Character...) in OverloadingVarargs2 match 1 error
+```
+
+如果你给这两个方法都添加一个非可变参数,就可以解决问题了:
+
+```java
+// housekeeping/OverloadingVarargs3
+
+public class OverloadingVarargs3 {
+ static void f(float i, Character... args) {
+ System.out.println("first");
+ }
+
+ static void f(char c, Character... args) {
+ System.out.println("second");
+ }
+
+ public static void main(String[] args) {
+ f(1, 'a');
+ f('a', 'b');
+ }
+}
+```
+
+输出:
+
+```
+first
+second
+```
+
+你应该总是在重载方法的一个版本上使用可变参数列表,或者压根不用它。
+
+
+
+# 10 枚举类型
+
+Java 5 中添加了一个看似很小的特性 **enum** 关键字,它使得我们在需要群组并使用枚举类型集时,可以很方便地处理。以前,你需要创建一个整数常量集,但是这些值并不会将自身限制在这个常量集的范围内,因此使用它们更有风险,而且更难使用。枚举类型属于非常普遍的需求,C、C++ 和其他许多语言都已经拥有它了。在 Java 5 之前,Java 程序员必须了解许多细节并格外仔细地去达成 **enum** 的效果。现在 Java 也有了 **enum**,并且它的功能比 C/C++ 中的完备得多。下面是个简单的例子:
+
+```java
+// housekeeping/Spiciness.java
+
+public enum Spiciness {
+ NOT, MILD, MEDIUM, HOT, FLAMING
+}
+```
+
+这里创建了一个名为 **Spiciness** 的枚举类型,它有5个值。由于枚举类型的实例是常量,因此按照命名惯例,它们都用大写字母表示(如果名称中含有多个单词,使用下划线分隔)。
+
+要使用 **enum**,需要创建一个该类型的引用,然后将其赋值给某个实例:
+
+```java
+// housekeeping/SimpleEnumUse.java
+
+public class SimpleEnumUse {
+ public static void main(String[] args) {
+ Spiciness howHot = Spiciness.MEDIUM;
+ System.out.println(howHot);
+ }
+}
+```
+
+输出:
+
+```
+MEDIUM
+```
+
+在你创建 **enum** 时,编译器会自动添加一些有用的特性。例如,它会创建 `toString()` 方法,以便你方便地显示某个 **enum** 实例的名称,这从上面例子中的输出可以看出。编译器还会创建 `ordinal()` 方法表示某个特定 **enum** 常量的声明顺序,`static values()` 方法按照 enum 常量的声明顺序,生成这些常量值构成的数组:
+
+```java
+// housekeeping/EnumOrder.java
+
+public class EnumOrder {
+ public static void main(String[] args) {
+ for (Spiciness s: Spiciness.values()) {
+ System.out.println(s + ", ordinal " + s.ordinal());
+ }
+ }
+}
+```
+
+输出:
+
+```
+NOT, ordinal 0
+MILD, ordinal 1
+MEDIUM, ordinal 2
+HOT, ordinal 3
+FLAMING, ordinal 4
+```
+
+尽管 **enum** 看起来像是一种新的数据类型,但是这个关键字只是在生成 **enum** 的类时,产生了某些编译器行为,因此在很大程度上你可以将 **enum** 当作其他任何类。事实上,**enum** 确实是类,并且具有自己的方法。
+
+**enum** 有一个很实用的特性,就是在 **switch** 语句中使用:
+
+```java
+// housekeeping/Burrito.java
+
+public class Burrito {
+ Spiciness degree;
+
+ public Burrito(Spiciness degree) {
+ this.degree = degree;
+ }
+
+ public void describe() {
+ System.out.print("This burrito is ");
+ switch(degree) {
+ case NOT:
+ System.out.println("not spicy at all.");
+ break;
+ case MILD:
+ case MEDIUM:
+ System.out.println("a little hot.");
+ break;
+ case HOT:
+ case FLAMING:
+ default:
+ System.out.println("maybe too hot");
+ }
+ }
+
+ public static void main(String[] args) {
+ Burrito plain = new Burrito(Spiciness.NOT),
+ greenChile = new Burrito(Spiciness.MEDIUM),
+ jalapeno = new Burrito(Spiciness.HOT);
+ plain.describe();
+ greenChile.describe();
+ jalapeno.describe();
+ }
+}
+```
+
+输出:
+
+```
+This burrito is not spicy at all.
+This burrito is a little hot.
+This burrito is maybe too hot.
+```
+
+由于 **switch** 是在有限的可能值集合中选择,因此它与 **enum** 是绝佳的组合。注意,enum 的名称是如何能够倍加清楚地表明程序的目的的。
+
+通常,你可以将 **enum** 用作另一种创建数据类型的方式,然后使用所得到的类型。这正是关键所在,所以你不用过多地考虑它们。在 **enum** 被引入之前,你必须花费大量的精力去创建一个等同的枚举类型,并是安全可用的。
+
+这些介绍对于你理解和使用基本的 **enum** 已经足够了,我们会在"枚举"一章中进行更深入的探讨。
+
+
+
+# 11 本章小结
+
+构造器,这种看起来精巧的初始化机制,应该给了你很强的暗示:初始化在编程语言中的重要地位。C++ 的发明者 Bjarne Stroustrup 在设计 C++ 期间,在针对 C 语言的生产效率进行的最初调查中发现,错误的初始化会导致大量编程错误。这些错误很难被发现,同样,不合理的清理也会如此。因为构造器能保证进行正确的初始化和清理(没有正确的构造器调用,编译器就不允许创建对象),所以你就有了完全的控制和安全。
+
+在 C++ 中,析构器很重要,因为用 **new** 创建的对象必须被明确地销毁。在 Java 中,垃圾回收器会自动地释放所有对象的内存,所以很多时候类似的清理方法就不太需要了(但是当要用到的时候,你得自己动手)。在不需要类似析构器行为的时候,Java 的垃圾回收器极大地简化了编程,并加强了内存管理上的安全性。一些垃圾回收器甚至能清理其他资源,如图形和文件句柄。然而,垃圾回收器确实增加了运行时开销,由于 Java 解释器从一开始就很慢,所以这种开销到底造成多大的影响很难看出来。随着时间的推移,Java 在性能方面提升了很多,但是速度问题仍然是它涉足某些特定编程领域的障碍。
+
+由于要保证所有对象被创建,实际上构造器比这里讨论得更加复杂。特别是当通过*组合*或*继承*创建新类的时候,这种保证仍然成立,并且需要一些额外的语法来支持。在后面的章节中,你会学习组合,继承以及它们如何影响构造器。
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\347\272\277\347\250\213\347\212\266\346\200\201.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\347\272\277\347\250\213\347\212\266\346\200\201.md"
new file mode 100644
index 0000000000..c3304c0ee1
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\347\272\277\347\250\213\347\212\266\346\200\201.md"
@@ -0,0 +1,215 @@
+
+
+> 面试官瞅了瞅我精悍的简历,随口一问,说说Java线程有哪些状态?
+
+这问的也太基础了,这就是开场白吗?
+
+这个简单的呀,面试官让我来告诉你,JDK 的 Thread 源码定义了6个状态: **java.lang.Thread.State**
+- New
+尚未启动的线程的线程状态。
+- Runnable
+可运行线程的线程状态,等待CPU调度。
+- Blocked
+线程阻塞等待监视器锁定的线程状态。处于synchronized同步代码块或方法中被阻塞。
+- Waiting
+等待线程的线程状态。下列不带超时的方式:
+`Object.wait`、`Thread.join`、 `LockSupport.park`
+- Timed Waiting
+具有指定等待时间的等待线程的线程状态。下列带超时的方式:
+Thread.sleep、0bject.wait、 Thread.join、 LockSupport.parkNanos、 LockSupport.parkUntil
+- Terminated
+终止线程的线程状态。线程正常完成执行或出现异常。
+
+文字说的还不是太清楚了,让我来你画个图就一目了然了:
+- Thread状态机
+
+- 上面那个图太复杂了看不懂?没问题,看个小学生版:
+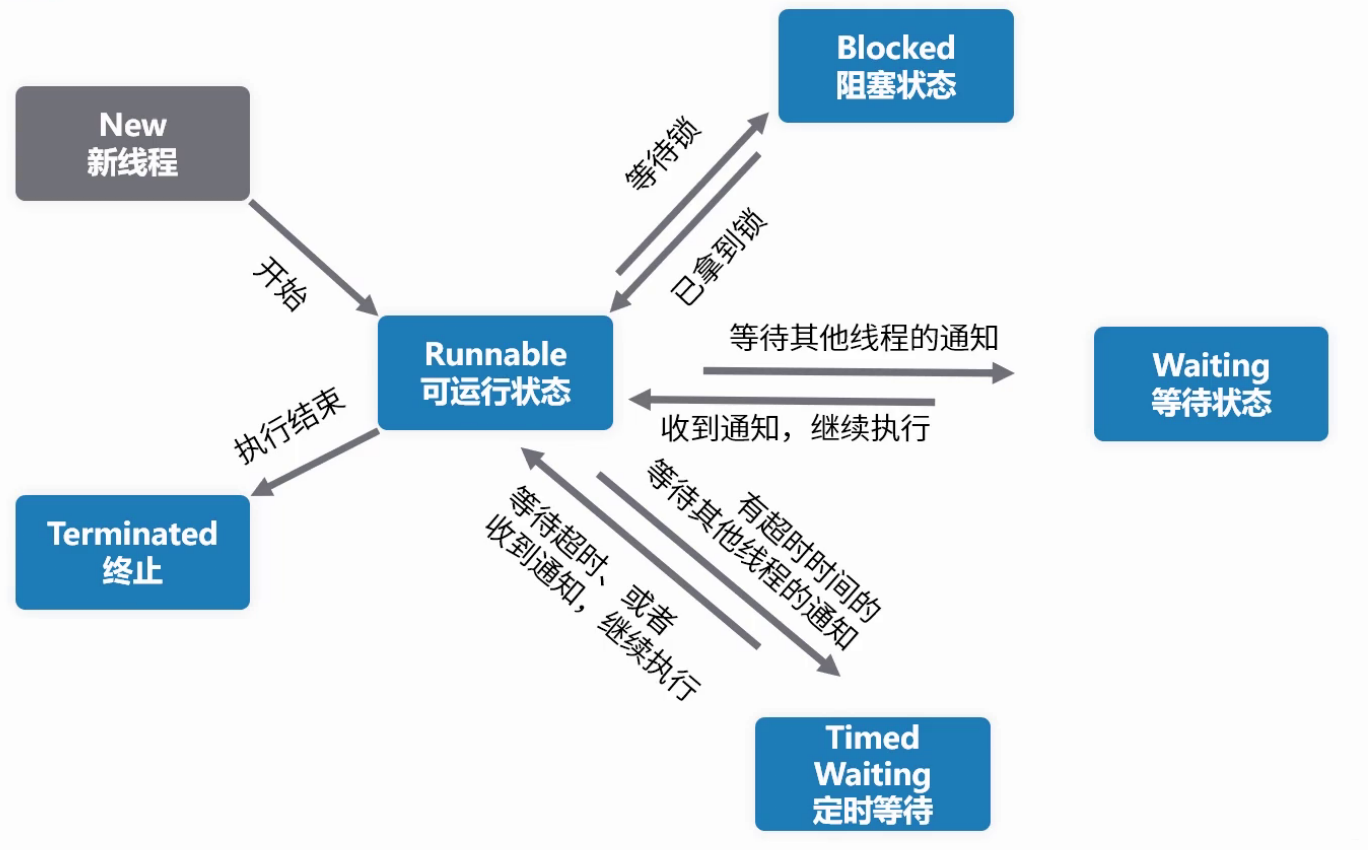
+
+# 1 NEW
+- **`线程还没有开始执行`**
+
+实现Runnable接口和继承Thread可以得到一个线程类,new一个实例出来,线程就进入了 **NEW** 状态。
+
+当调用线程的**start()**方法,线程也不一定会马上执行,因为`Java线程是映射到os的线程执行的`,此时可能还需要等os调度,但此时该线程的状态已经为**RUNNABLE**。
+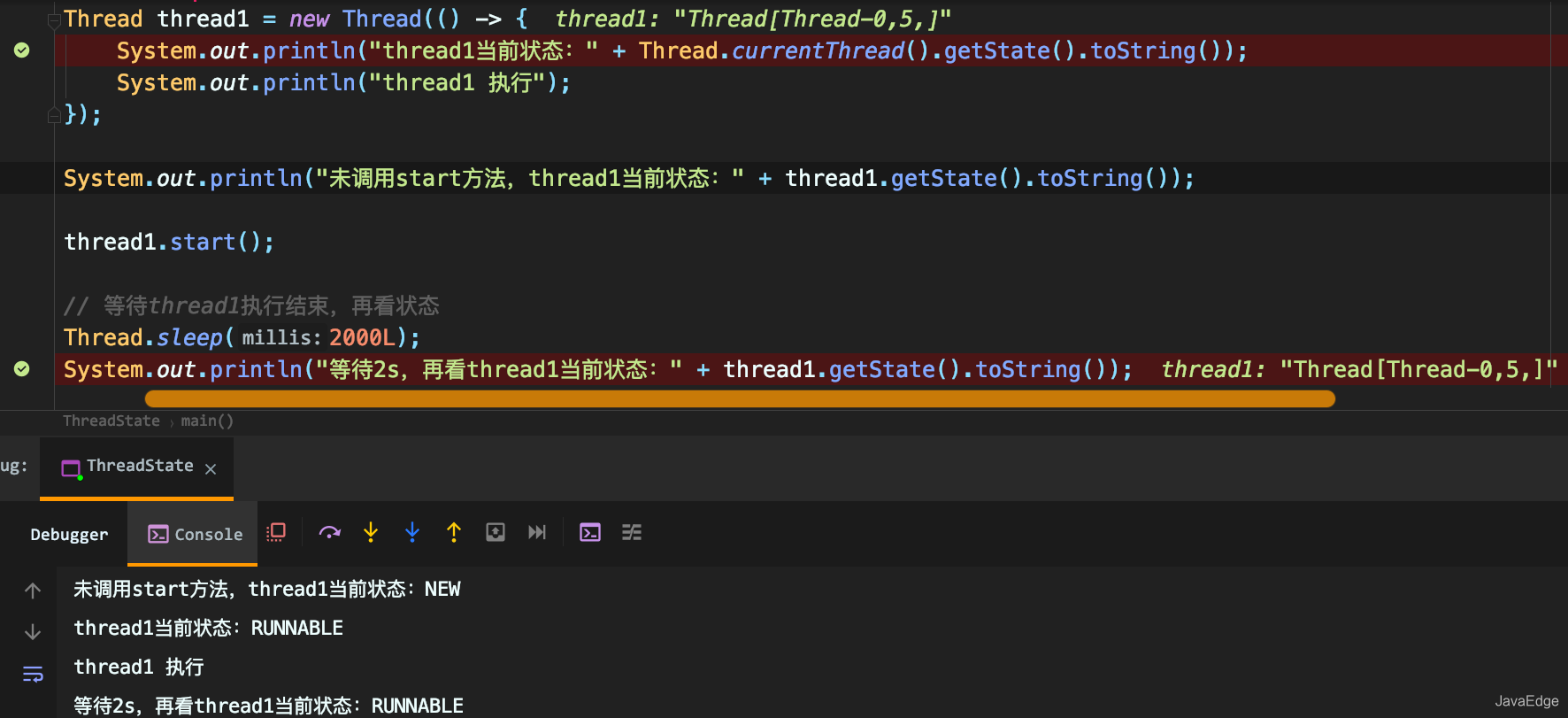
+# 2 RUNNABLE
+
+
+只是说你有资格运行,调度程序没有挑选到你,你就永远是可运行状态。
+
+## 2.1条件
+- 调用start()
+- 当前线程sleep()结束
+- 其他线程join()结束
+- 等待用户输入完毕
+- 某个线程拿到对象锁
+- 当前线程时间片用完
+- 调用当前线程的yield()
+- 锁池里的线程拿到对象锁后,进入可运行状态
+- 正在执行的线程
+
+该状态最有争议,注释说它表示线程在JVM层面是执行的,但在os不一定,它举例是CPU,毫无疑问CPU是一个os资源,但这也就意味着在等操作系统其他资源的时候,线程也会是这个状态
+
+> 这里就有一个关键点IO阻塞算是等操作系统的资源?
+# 3 BLOCKED
+- 线程由于等待监视器锁,被阻塞。 处于阻塞态的线程在调用`Object.wait`之后正在等待监视器锁 进入 同步的块/方法或 再进入 同步的块/方法
+
+
+被挂起,线程因为某原因放弃cpu 时间片,暂时停止运行。
+
+## 3.1条件
+- 当前线程调用`Thread.sleep()`
+- 运行在当前线程里的其它线程调用`join()`,当前线程进入阻塞态
+- 等待用户输入时,当前线程进入阻塞态
+
+## 3.2 分类
+- 等待阻塞
+运行的线程执行o.wait()方法,JVM会把该线程放入等待队列(waitting queue)
+
+- 同步阻塞
+运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池(lock pool)
+
+- 其他阻塞
+运行的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。
+当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
+
+线程在阻塞等待monitor lock(监视器锁)
+一个线程在进入synchronized修饰的临界区的时候,或者在synchronized临界区中调用Object.wait然后被唤醒重新进入synchronized临界区都对应该态。
+
+结合上面RUNNABLE的分析,也就是I/O阻塞不会进入BLOCKED状态,只有synchronized会导致线程进入该状态
+
+关于BLOCKED状态,注释里只提到一种情况就是进入synchronized声明的临界区时会导致,这好理解,synchronized是JVM自己控制的,所以这个阻塞事件它自己能够知道(对比理解上面的os层面)。
+
+interrupt()是无法唤醒的,只是做个标记。
+
+# 4 等待
+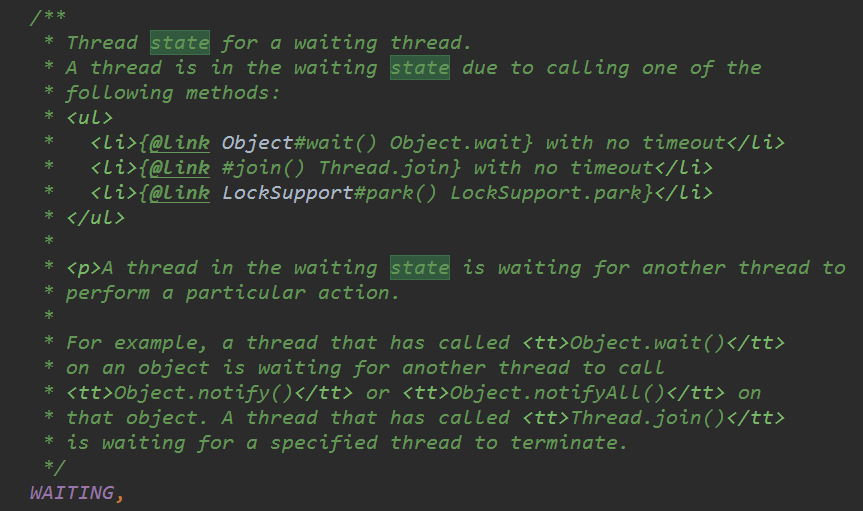
+线程拥有对象锁后进入到相应的代码区后,调用相应的“锁对象”的`wait()`后产生的一种结果
+
+- 变相的实现
+`LockSupport.park()`
+`LockSupport parkNanos( )`
+`LockSupport parkUntil( )`
+`Thread join( )`
+
+它们也是在等待另一个对象事件的发生,也就是描述了等待的意思。
+
+## `BLOCKED `状态也是等待的意思,有什么关系与区别呢?
+- `BLOCKED `是虚拟机认为程序还不能进入某个区域,因为同时进去就会有问题,这是一块临界区
+- `wait()`的先决条件是要进入临界区,也就是线程已经拿到了“门票”,自己可能进去做了一些事情,但此时通过判定某些业务上的参数(由具体业务决定),发现还有一些其他配合的资源没有准备充分,那么自己就等等再做其他的事情
+
+有一个非常典型的案例就是通过`wait()`和`notify()`完成生产者/消费者模型
+当生产者生产过快,发现仓库满了,即消费者还没有把东西拿走(空位资源还没准备好) 时,生产者就等待有空位再做事情,消费者拿走东西时会发出“有空位了”的消息,那么生产者就又开始工作了
+反过来也是一样,当消费者消费过快发现没有存货时,消费者也会等存货到来,生产者生产出内容后发出“有存货了”的消息,消费者就又来抢东西了。
+
+
+在这种状态下,如果发生了对该线程的`interrupt()`是有用的,处于该状态的线程内部会抛出一个`InerruptedException`
+这个异常应当在`run()`里面捕获,使得`run()`正常地执行完成。当然在`run()`内部捕获异常后,还可以让线程继续运行,这完全是根据具体的应用场景来决定的。
+
+在这种状态下,如果某线程对该锁对象做了`notify()`,那么将从等待池中唤醒一个线程重新恢复到`RUNNABLE `
+除`notify()`外,还有一个`notifyAll()` ,前者是
+唤醒一个处于`WAITING`的线程,而后者是唤醒所有的线程。
+
+Object.wait()是否需要死等呢?
+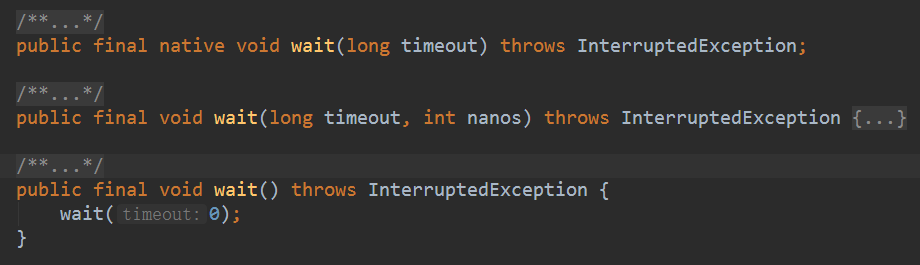
+不是,除中断外,它还有两个重构方法
+- Object.wait(int timeout),传入的timeout 参数是超时的毫秒值,超过这个值后会自动唤醒,继续做下面的操作(不会抛出`InterruptedException` ,但是并不意味着我们不去捕获,因为不排除其他线程会对它做`interrup()`)。
+- Object.wait(int timeout,int nanos) 这是一个更精确的超时设置,理论上可以精确到纳秒,这个纳秒值可接受的范围是0~999999 (因为100000onS 等于1ms)。
+
+同样的
+`LockSupport park( )`
+`LockSupport.parkNanos( )`
+`LockSupport.parkUntil( )`
+`Thread.join()`
+这些方法都会有类似的重构方法来设置超时,达到类似的目的,不过此时的状态不再是`WAITING`,而是`TIMED.WAITING`
+
+通常写代码的人肯定不想让程序死掉,但是又希望通过这些等待、通知的方式来实现某些平衡,这样就不得不去尝试采用“超时+重试+失败告知”等方式来达到目的。
+
+# TIMED _WAITING
+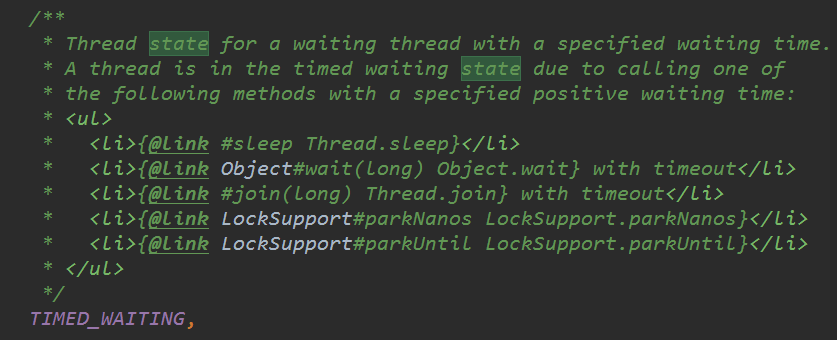
+当调用`Thread.sleep()`时,相当于使用某个时间资源作为锁对象,进而达到等待的目的,当时间达到时触发线程回到工作状态。
+
+# TERM_INATED
+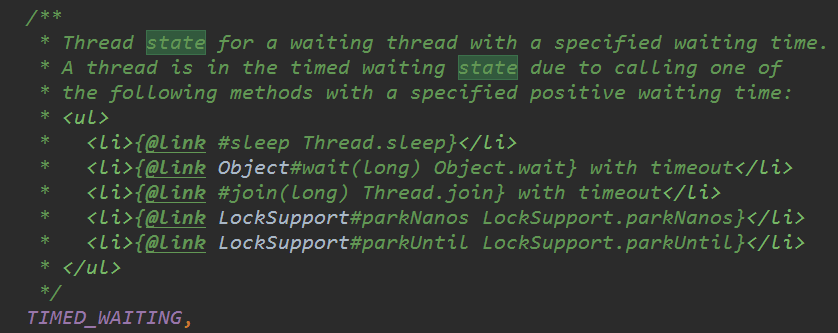
+这个线程对象也许是活的,但是,它已经不是一个单独执行的线程,在一个死去的线程上调用start()方法,会抛`java.lang.IllegalThreadStateException`.
+线程run()、main() 方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
+run()走完了,线程就处于这种状态。其实这只是Java 语言级别的一种状态,在操作系统内部可能已经注销了相应的线程,或者将它复用给其他需要使用线程的请求,而在Java语言级别只是通过Java 代码看到的线程状态而已。
+
+## 为什么`wait( )`和`notify( )`必须要使用synchronized
+如果不用就会报`ilegalMonitorStateException`
+常见的写法如下:
+```java
+synchronized(Object){
+ object.wait() ;//object.notify() ;
+}
+
+synchronized(this){
+ this.wait();
+}
+synchronized fun( ){
+ this.wait();//this.notify();
+}
+```
+`wait()`和notify()`是基于对象存在的。
+- 那为什么要基于对象存在呢?
+既然要等,就要考虑等什么,这里等待的就是一个对象发出的信号,所以要基于对象而存在。
+不用对象也可以实现,比如suspend()/resume()就不需要,但是它们是反面教材,表面上简单,但是处处都是问题
+
+理解基于对象的这个道理后,目前认为它调用的方式只能是`Object.wait()`,这样才能和对象挂钩。但这些东西还与问题“wait()/notify() 为什么必须要使用synchronized" 没有
+半点关系,或者说与对象扯上关系,为什么非要用锁呢?
+
+既然是基于对象的,因此它不得不用一个数据结构来存放这些等
+待的线程,而且这个数据结构应当是与该对象绑定的(通过查看C++代码,发现该数据结构为一个双向链表),此时在这个对象上可能同时有多个线程调用wait()/notify(),在向这个对象所对应的双向链表中写入、删除数据时,依然存在并发的问题,理论上
+也需要一个锁来控制。在JVM 内核源码中并没有发现任何自己用锁来控制写入的动作,只是通过检查当前线程是否为对象的OWNER 来判定是否要抛出相应的异常。由此可见它希望该动作由Java 程序这个抽象层次来控制,它为什么不想去自己控制锁呢?
+因为有些时候更低抽象层次的锁未必是好事,因为这样的请求对于外部可能是反复循环地去征用,或者这些代码还可能在其他地方复用,也许将它粗粒度化会更好一些,而且这样的代在写在Java 程序中本身也会更加清晰,更加容易看到相互之间的关系。
+
+interrupt()操作只对处于WAITING 和TIME_WAITING 状态的线程有用,让它们]产生实质性的异常抛出。
+在通常情况下,如果线程处于运行中状态,也不会让它中断,如果中断是成立的,可能会导致正常的业务运行出现问题。另外,如果不想用强制手段,就得为每条代码的运行设立检查,但是这个动作很麻烦,JVM 不愿意做这件事情,它做interruptl )仅仅是打一个标记,此时程序中通过isInterrupt()方法能够判定是否被发起过中断操作,如果被中断了,那么如何处理程序就是设计上的事情了。
+
+举个例子,如果代码运行是一个死循环,那么在循环中可以这样做:
+```java
+while(true) {
+ if (Thread.currentThread.isInterrupt()) {
+ //可以做类似的break、return,抛出InterruptedExcept ion 达到某种目的,这完全由自己决定
+ //如拋出异常,通常包装一层try catch 异常处理,进一步做处理,如退出run 方法或什么也不做
+ }
+}
+```
+这太麻烦了,为什么不可以自动呢?
+可以通过一些生活的沟通方式来理解一下: 当你发现门外面有人呼叫你时,你自己是否搭理他是你的事情,这是一种有“爱”的沟通方式,反之是暴力地破门而入,把你强制“抓”出去的方式。
+
+在JDK 1.6 及以后的版本中,可以使用线程的`interrupted( )`
+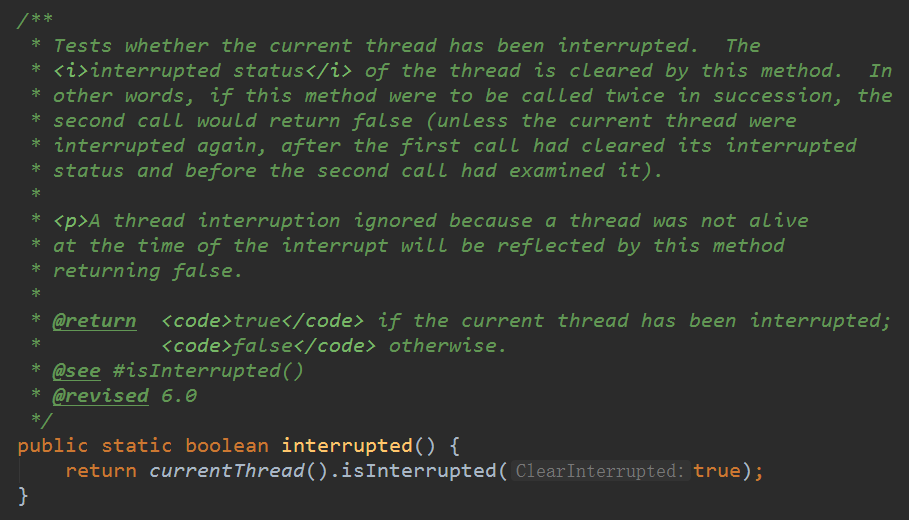
+
+判定线程是否已经被调用过中断方法,表面上的效果与`isInterrupted()`
+结果一样,不过这个方法是一个静态方法
+除此之外,更大的区别在于这个方法调用后将会重新将中断状态设置为`false`,方便于循环利用线程,而不是中断后状态就始终为true,就无法将状态修改回来了。类似的,判定线程的相关方法还有`isAlive()`
+
+`isDaemon()`
+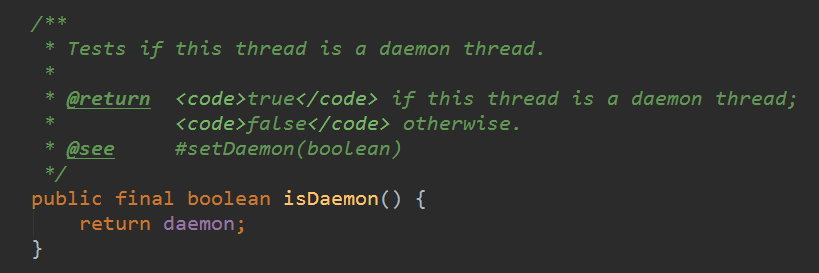
+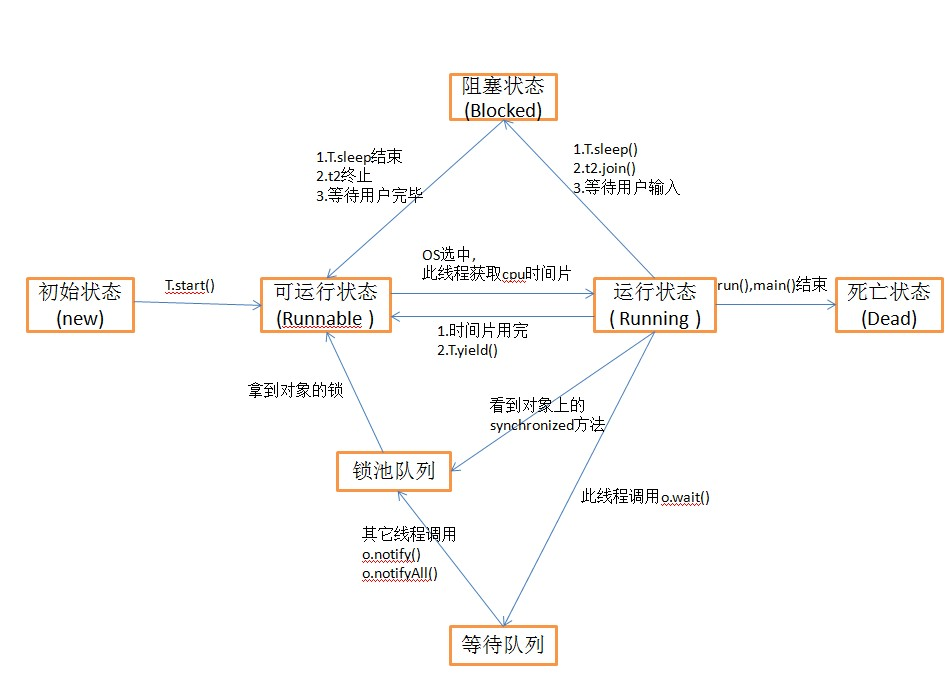
+# 等待队列
+1. 调用wait(), notify()前,必须获得obj锁,也就是必须写在synchronized(obj) 代码段内
+2. 与等待队列相关的步骤和图
+* 线程1获取对象A的锁,正在使用对象A。
+* 线程1调用对象A的wait()方法。
+* 线程1释放对象A的锁,并马上进入等待队列。
+* 锁池里面的对象争抢对象A的锁。
+* 线程5获得对象A的锁,进入synchronized块,使用对象A。
+* 线程5调用对象A的notifyAll()方法,唤醒所有线程,所有线程进入锁池。|| 线程5调用对象A的notify()方法,唤醒一个线程,不知道会唤醒谁,被唤醒的那个线程进入锁池。
+* notifyAll()方法所在synchronized结束,线程5释放对象A的锁。
+* 锁池里面的线程争抢对象锁,但线程1什么时候能抢到就不知道了。|| 原本锁池+第6步被唤醒的线程一起争抢对象锁。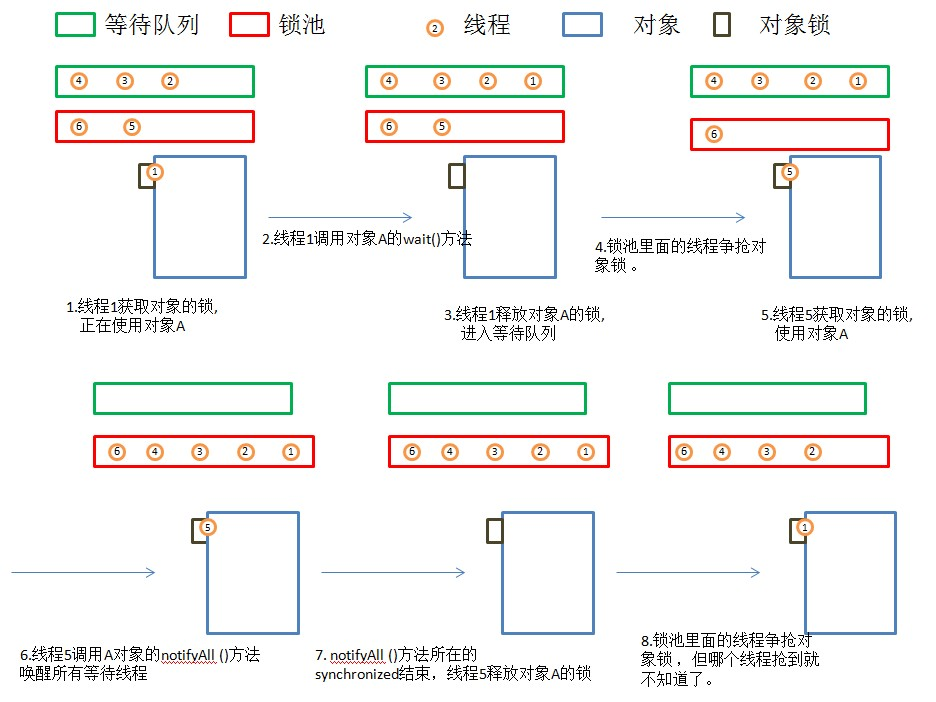
+
+# 锁池状态
+1. 当前线程想调用对象A的同步方法时,发现对象A的锁被别的线程占有,此时当前线程进入锁池状态。
+简言之,锁池里面放的都是想`争夺对象锁的线程`
+2. 当一个线程1被另外一个线程2唤醒时,1线程进入锁池状态,去争夺对象锁。
+3. 锁池是在同步的环境下才有的概念,`一个对象对应一个锁池`
+
+
+4. obj.wait(),当前线程调用对象的wait()方法,当前线程释放对象锁,进入等待队列。依靠notify()/notifyAll()唤醒或者wait(long timeout)timeout时间到自动唤醒。
+5. obj.notify()唤醒在此对象监视器上等待的单个线程,选择是任意性的。notifyAll()唤醒在此对象监视器上等待的所有线程。
+
+- 当对象锁被某一线程释放的一瞬间,锁池里面的哪个线程能获得这个锁?随机?队列FIFO?or sth else?
+- 等待队列里许许多多的线程都wait()在一个对象上,此时某一线程调用了对象的notify()方法,那唤醒的到底是哪个线程?随机?队列FIFO?or sth else?java文档就简单的写了句:选择是任意性的。
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\350\257\255\346\263\225\347\263\226\344\271\213\346\263\233\345\236\213\344\270\216\347\261\273\345\236\213\346\223\246\351\231\244.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\350\257\255\346\263\225\347\263\226\344\271\213\346\263\233\345\236\213\344\270\216\347\261\273\345\236\213\346\223\246\351\231\244.md"
new file mode 100644
index 0000000000..d1adafb052
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\350\257\255\346\263\225\347\263\226\344\271\213\346\263\233\345\236\213\344\270\216\347\261\273\345\236\213\346\223\246\351\231\244.md"
@@ -0,0 +1,38 @@
+# 1 泛型与类型擦除
+泛型,JDK 1.5新特性,本质是参数化类型(Parametersized Type) 的应用,即所操作的数据类型被指定为一个参数。这种参数类型可用在:
+- 类
+- 接口
+- 方法
+
+的创建中, 分别称为:
+- 泛型类
+- 泛型接口
+- 泛型方法
+
+在Java还没有泛型的版本时。只能通过:
+1. Object 是所有类型的父类
+2. 类型强制转换
+
+两个特性协作实现类型泛化。例如,在哈希表的存取中,JDK 1.5之前使用HashMap的get() 方法,返回值就是个Object。由于Java语言里面所有的类型都维承于**java.lang.Object**,所以Object转型成任何对象都有可能。但也因为有无限的可能性,就只有程序员和运行期的虚拟机才知道这个Objet到底是个什么类型的对象。
+编译期间,编译器无法检查该Object的强制转型是否成功。若仅仅依赖程序员去保障正确性,许多ClassCastException的风险就会延迟到程序运行期。
+
+Java语言中的泛型则不一样,它只在程序源码中存在,在编译后的字节码文件中,就已经替换为原来的原生类型(Raw Type) ,并在相应地方插入强制转换代码。
+因此,对运行期的Java来说`Araylist`、`Aralist`是同一个类。所以泛型是Java语言的一颗语法糖Java称为类型擦除,基于这种方法实现的泛型称为伪泛型。
+- 泛型擦除前的例子
+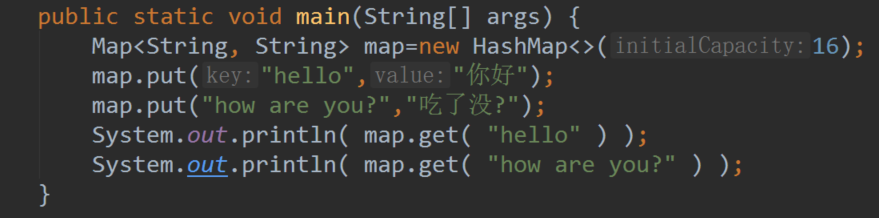
+把这段Java代码编译成Class文件,然后再用字节码反编译后,將会发现泛型都不见了,又变回了Java泛型出现之前的写法,泛型类型都变回了原类型。如:
+
+通过擦除实现泛型,丧失了一些泛型思想应有的优雅
+- 当泛型遇见重载1
+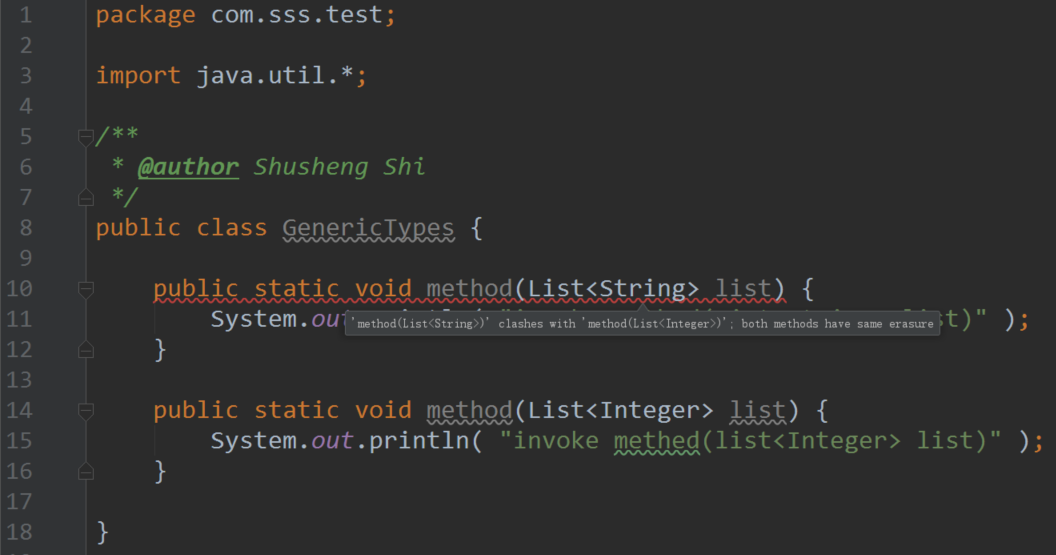
+不能被编译的,因为参数`List`和`List`编译之后都被擦除了。变成了一样的原生类型`List`,擦除动作导致这两种方法的特征签名变得一模一样。初步看来,无法重载的原因已经找到了,但真的就如此吗? 只能说,泛型擦除成相同的原生类型只是无法重载的部分原因
+- 当泛型遇见置载2
+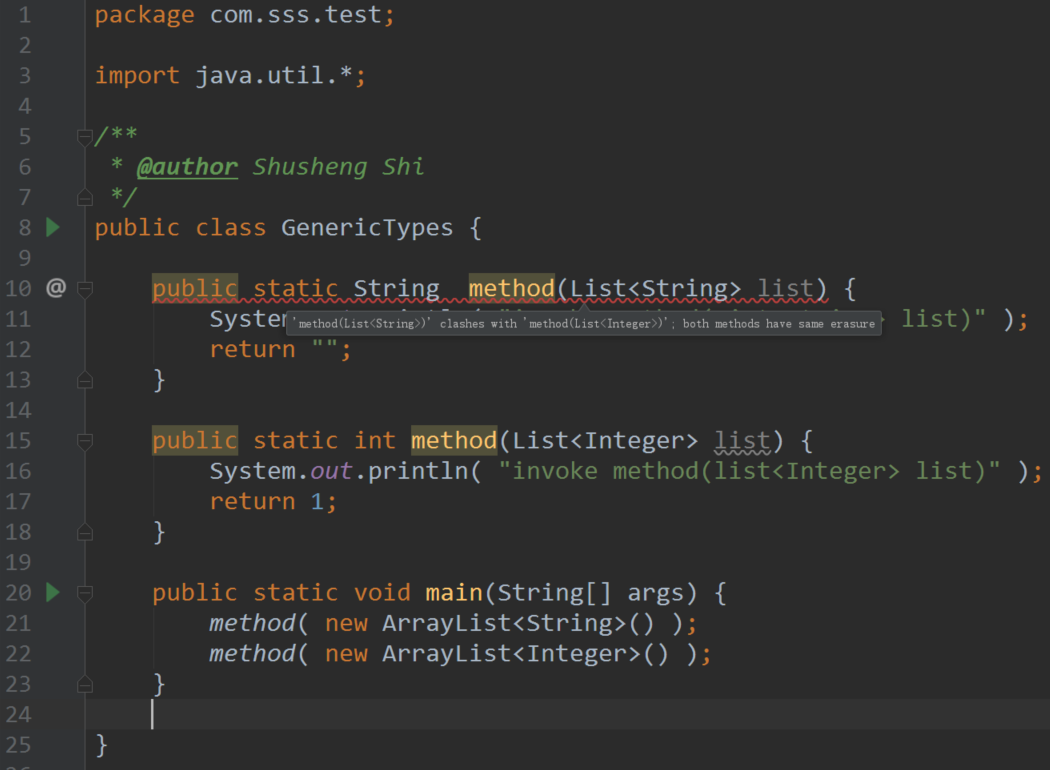
+由于Java泛型的引入,各种场景(虚拟机解析、反射等)下的方法调用都可能对原有基础产生影响,如在泛型类中如何获取传入的参数化类型等。因此,JCP组织对虚拟机规范做出了相应的修改,引入了诸如**Signature、LocalVariableTypeTable** 等新的属性用于解决伴随泛型而来的参数类型的识别问题,Signature 是其中最重要的一项属性,它的作用就是存储一个方法在字节码层面的特征签名,这个属性中保存的参数类型并不是原生类型,而是包括了参数化类型的信息。修改后的虚拟机规范要求所有能识别49.0以上版本的Class文件的虚拟机都要能正确地识别Signature参数。
+
+从Signature属性的出现我们还可以得出结论,所谓的擦除,仅仅是对方法的Code属性中的字节码进行擦除,实际上元数据还是保留了泛型信息,这也是我们能通过反射取得参数化类型的根本依据。
+- 自动装箱: 拆箱与遍历循环
+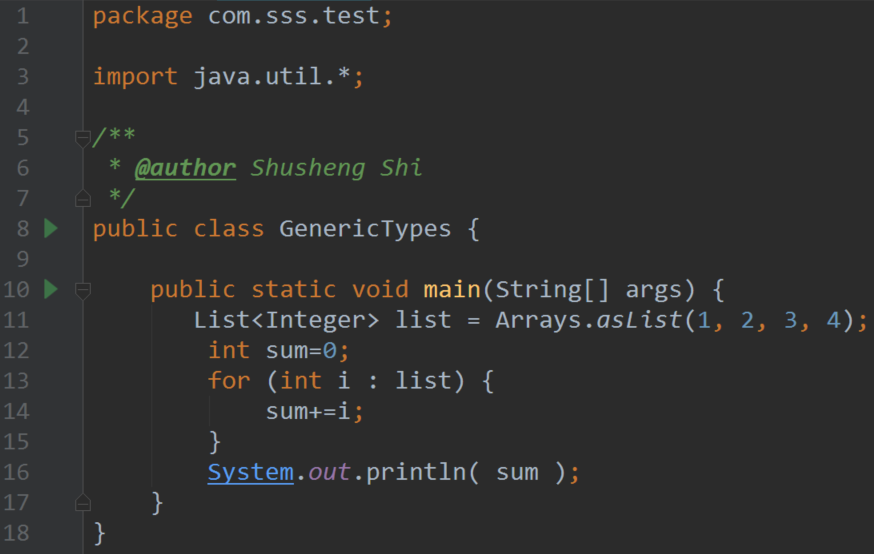
+- 自动装箱: 拆箱与遍历循环编译后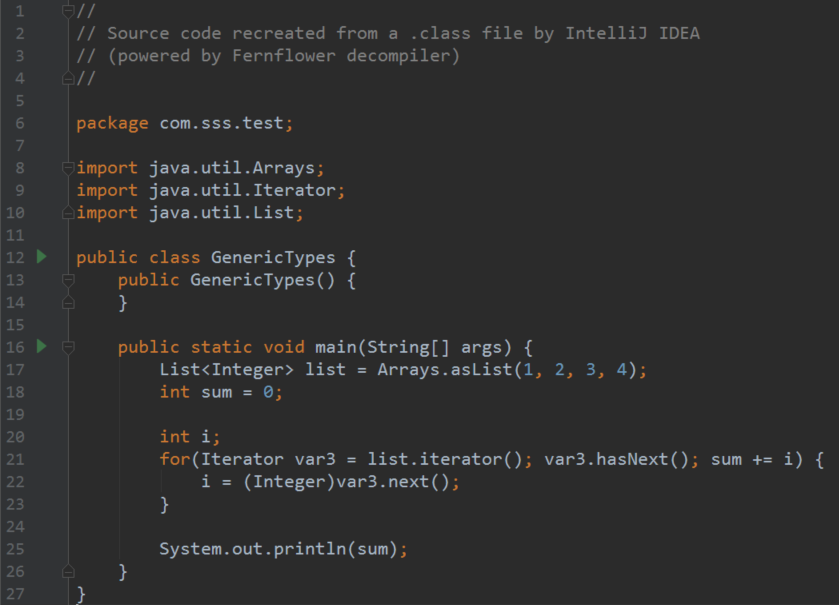
+遍历循环则把代码还原成了迭代器的实现,这也是为何遍历循环需要被遍历的类实现Iterable接口的原因。最后再看看变长参数,它在调用的时候变成了一个数组类型的参数,在变长参数出现之前,程序员就是使用数组来完成类似功能的。
+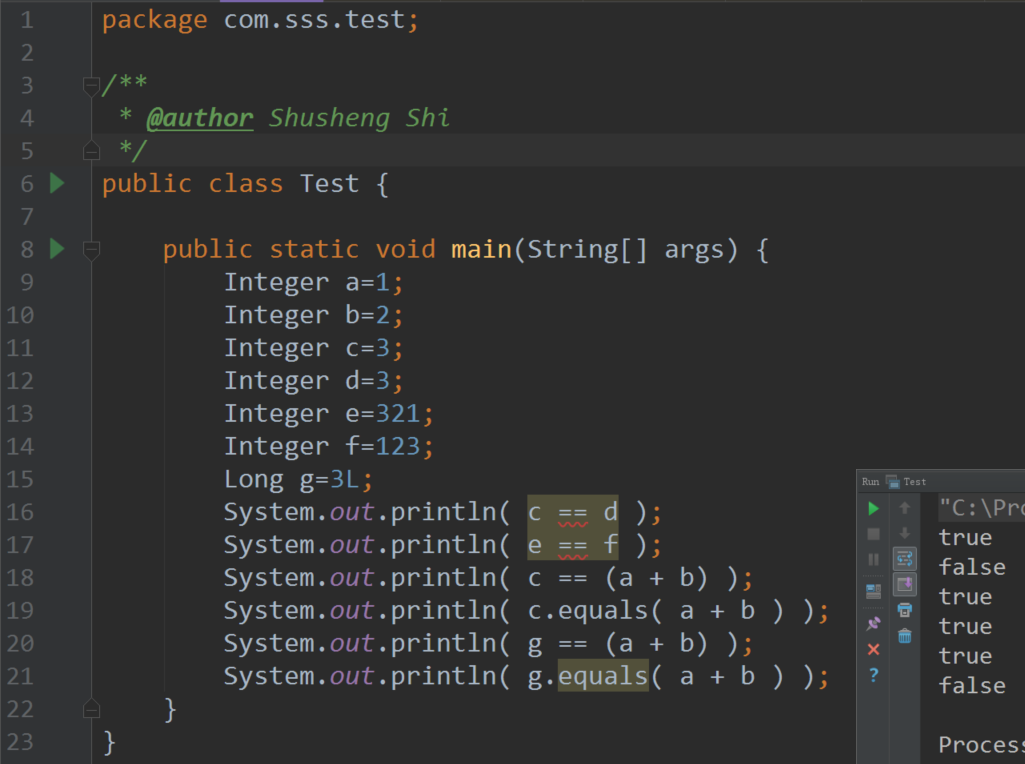
\ No newline at end of file
diff --git "a/Java/Java\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220---HashMap.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220---HashMap.md"
similarity index 99%
rename from "Java/Java\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220---HashMap.md"
rename to "JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220---HashMap.md"
index bd1ea05cb6..5f742d6338 100644
--- "a/Java/Java\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220---HashMap.md"
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/Java\351\233\206\345\220\210\346\272\220\347\240\201\350\247\243\346\236\220---HashMap.md"
@@ -161,7 +161,9 @@ n | (n >>> 8) 导致n二进制表示的高9~16位经过运算值均为1
可以看出,无论给定cap(cap < MAXIMUM_CAPACITY )的值是多少,经过以上运算,其值的二进制所有位都会是1.再将其加1,这时候这个值一定是2的幂次方.
当然如果经过运算值大于MAXIMUM_CAPACITY,直接选用MAXIMUM_CAPACITY.
-
+
+
+
至此tableSizeFor如何保证cap为2的幂次方已经显而易见了,那么问题来了
## 4.1 **为什么cap要保持为2的幂次方?**
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\344\270\200\346\226\207\346\220\236\346\207\202Java\347\232\204SPI\346\234\272\345\210\266.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\344\270\200\346\226\207\346\220\236\346\207\202Java\347\232\204SPI\346\234\272\345\210\266.md"
new file mode 100644
index 0000000000..1c69b61c1e
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\344\270\200\346\226\207\346\220\236\346\207\202Java\347\232\204SPI\346\234\272\345\210\266.md"
@@ -0,0 +1,63 @@
+# 1 简介
+SPI,Service Provider Interface,一种服务发现机制。
+
+有了SPI,即可实现服务接口与服务实现的解耦:
+- 服务提供者(如 springboot starter)提供出 SPI 接口。身为服务提供者,在你无法形成绝对规范强制时,适度"放权" 比较明智,适当让客户端去自定义实现
+- 客户端(普通的 springboot 项目)即可通过本地注册的形式,将实现类注册到服务端,轻松实现可插拔
+
+## 缺点
+- 不能按需加载。虽然 ServiceLoader 做了延迟加载,但是只能通过遍历的方式全部获取。如果其中某些实现类很耗时,而且你也不需要加载它,那么就形成了资源浪费
+- 获取某个实现类的方式不够灵活,只能通过迭代器的形式获取
+
+> Dubbo SPI 实现方式对以上两点进行了业务优化。
+
+# 源码
+
+应用程序通过迭代器接口获取对象实例,这里首先会判断 providers 对象中是否有实例对象:
+- 有实例,那么就返回
+- 没有,执行类的装载步骤,具体类装载实现如下:
+
+LazyIterator#hasNextService 读取 META-INF/services 下的配置文件,获得所有能被实例化的类的名称,并完成 SPI 配置文件的解析
+
+
+LazyIterator#nextService 负责实例化 hasNextService() 读到的实现类,并将实例化后的对象存放到 providers 集合中缓存
+
+# 使用
+如某接口有3个实现类,那系统运行时,该接口到底选择哪个实现类呢?
+这时就需要SPI,**根据指定或默认配置,找到对应实现类,加载进来,然后使用该实现类实例**。
+
+如下系统运行时,加载配置,用实现A2实例化一个对象来提供服务:
+
+再如,你要通过jar包给某个接口提供实现,就在自己jar包的`META-INF/services/`目录下放一个接口同名文件,指定接口的实现是自己这个jar包里的某类即可:
+
+别人用这个接口,然后用你的jar包,就会在运行时通过你的jar包指定文件找到这个接口该用哪个实现类。这是JDK内置提供的功能。
+
+> 我就不定义在 META-INF/services 下面行不行?就想定义在别的地方可以吗?
+
+No!JDK 已经规定好配置路径,你若随便定义,类加载器可就不知道去哪里加载了
+
+假设你有个工程P,有个接口A,A在P无实现类,系统运行时怎么给A选实现类呢?
+可以自己搞个jar包,`META-INF/services/`,放上一个文件,文件名即接口名,接口A的实现类=`com.javaedge.service.实现类A2`。
+让P来依赖你的jar包,等系统运行时,P跑起来了,对于接口A,就会扫描依赖的jar包,看看有没有`META-INF/services`文件夹:
+- 有,再看看有无名为接口A的文件:
+ - 有,在里面查找指定的接口A的实现是你的jar包里的哪个类即可
+# 适用场景
+## 插件扩展
+比如你开发了一个开源框架,若你想让别人自己写个插件,安排到你的开源框架里中,扩展功能时。
+
+如JDBC。Java定义了一套JDBC的接口,但并未提供具体实现类,而是在不同云厂商提供的数据库实现包。
+> 但项目运行时,要使用JDBC接口的哪些实现类呢?
+
+一般要根据自己使用的数据库驱动jar包,比如我们最常用的MySQL,其`mysql-jdbc-connector.jar` 里面就有:
+
+系统运行时碰到你使用JDBC的接口,就会在底层使用你引入的那个jar中提供的实现类。
+## 案例
+如sharding-jdbc 数据加密模块,本身支持 AES 和 MD5 两种加密方式。但若客户端不想用内置的两种加密,偏偏想用 RSA 算法呢?难道每加一种算法,sharding-jdbc 就要发个版本?
+
+sharding-jdbc 可不会这么蠢,首先提供出 EncryptAlgorithm 加密算法接口,并引入 SPI 机制,做到服务接口与服务实现分离的效果。
+客户端想要使用自定义加密算法,只需在客户端项目 `META-INF/services` 的路径下定义接口的全限定名称文件,并在文件内写上加密实现类的全限定名
+
+
+这就显示了SPI的优点:
+- 客户端(自己的项目)提供了服务端(sharding-jdbc)的接口自定义实现,但是与服务端状态分离,只有在客户端提供了自定义接口实现时才会加载,其它并没有关联;客户端的新增或删除实现类不会影响服务端
+- 如果客户端不想要 RSA 算法,又想要使用内置的 AES 算法,那么可以随时删掉实现类,可扩展性强,插件化架构
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\345\255\220\347\261\273\345\217\257\344\273\245\347\273\247\346\211\277\345\210\260\347\210\266\347\261\273\344\270\212\347\232\204\346\263\250\350\247\243\345\220\227\357\274\237.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\345\255\220\347\261\273\345\217\257\344\273\245\347\273\247\346\211\277\345\210\260\347\210\266\347\261\273\344\270\212\347\232\204\346\263\250\350\247\243\345\220\227\357\274\237.md"
new file mode 100644
index 0000000000..e48364b7f6
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\345\255\220\347\261\273\345\217\257\344\273\245\347\273\247\346\211\277\345\210\260\347\210\266\347\261\273\344\270\212\347\232\204\346\263\250\350\247\243\345\220\227\357\274\237.md"
@@ -0,0 +1,68 @@
+
+
+> 子类重写父类方法后,可以继承方法上的注解吗?
+
+
+这个不急,让我来分析一下,假设有如下注解:
+
+
+
+- 定义被注解的类
+
+
+
+- 子类直接继承父类
+
+
+
+- 获取父子类和方法的注解信息,并输出注解的value属性的值
+
+
+- 日志输出
+
+
+可见**子类及子类的方法,无法自动继承父类和父类方法上的注解**。
+
+不对呀,你得使用`@Inherited`元注解才能实现注解的继承!行,那咱就加上
+- 再看一遍控制台信息
+
+可见使用`@Inherited`只能实现类上的注解继承。
+
+> 那么如何实现方法上注解的继承呢?
+
+最简单暴力地,可通过反射技术,在继承链找到对应方法上的注解。但这样很麻烦,还需要考虑桥接方法。幸好Spring足够强大,提供了**AnnotatedElementUtils**类。
+### 对`@Inherited`的支持
+遵循get语义的方法将遵循Java的`@Inherited`注解的约定,除了在本地声明的批注(包括自定义组成的注解)优于继承的注解之外。相反,遵循find语义的方法将完全忽略`@Inherited`的存在,因为find搜索算法手动遍历类型和方法层次结构,从而隐式支持注解继承,而无需`@Inherited`。
+
+### Find V.S Get Semantics
+此类中的方法使用的搜索算法遵循find或get语义。
+#### Get 语义
+仅限于搜索存在于`AnnotatedElement`上的注解(即在本地声明或继承)或在AnnotatedElement上方的注解层次结构中声明的注释。
+#### Find 语义
+更加详尽,提供了获取语义以及对以下内容的支持:
+- 搜索接口(如果带注释的元素是类)
+- 搜索超类(如果带注释的元素是一个类)
+- 解析桥接方法(如果带注释的元素是方法)
+- 如果带注解的元素是方法,则在接口中搜索方法
+- 如果带注解的元素是方法,则在超类中搜索方法
+
+如下俩方法其实也很相像,有何区别呢?
+##### findAllMergedAnnotations
+Find 对应 `SearchStrategy.TYPE_HIERARCHY`
+
+**findMergedAnnotation**方法可一次性找出父类和接口、父类方法和接口方法上的注解
+
+##### getAllMergedAnnotations
+Get对应 `SearchStrategy.INHERITED_ANNOTATIONS`:
+
+
+> 想想 Spring 的@Service、@Controller 等注解支持继承吗?
+
+我们通常的controller类,都会使用controller注解,如果可以被继承的话,Spring就不会只让我们使用Controller注解了,会提供另一种方式注入Controller组件,就是继承BaseController类。
+Spring 官方对此也有回应:继承的问题在于那些注解真的应该应用于特定的具体类。
+
+> 参考
+> - https://github.com/spring-projects/spring-framework/issues/8859
+> - https://docs.oracle.com/javase/8/docs/api/java/lang/annotation/Inherited.html
+> https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/core/annotation/AnnotatedElementUtils.html
+> https://docs.oracle.com/javase/8/docs/api/java/lang/Class.html
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\346\267\261\345\205\245\345\210\206\346\236\220-Java-\347\232\204\346\236\232\344\270\276-enum.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\346\267\261\345\205\245\345\210\206\346\236\220-Java-\347\232\204\346\236\232\344\270\276-enum.md"
new file mode 100644
index 0000000000..b64692d19d
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\346\267\261\345\205\245\345\210\206\346\236\220-Java-\347\232\204\346\236\232\344\270\276-enum.md"
@@ -0,0 +1,487 @@
+# 1 定义
+
+一种数据类型,只包含自定义的特定数据,是一组有共同特性的数据的集合。
+
+创建需要enum关键字,如:
+
+```java
+public enum Color {
+ RED, GREEN, BLUE, BLACK, PINK, WHITE;
+}
+```
+
+enum的语法看似与类不同,但它实际上就是一个类。
+
+
+
+
+把上面的编译成 Gender.class, 然后用 ` javap -c Gender `反编译
+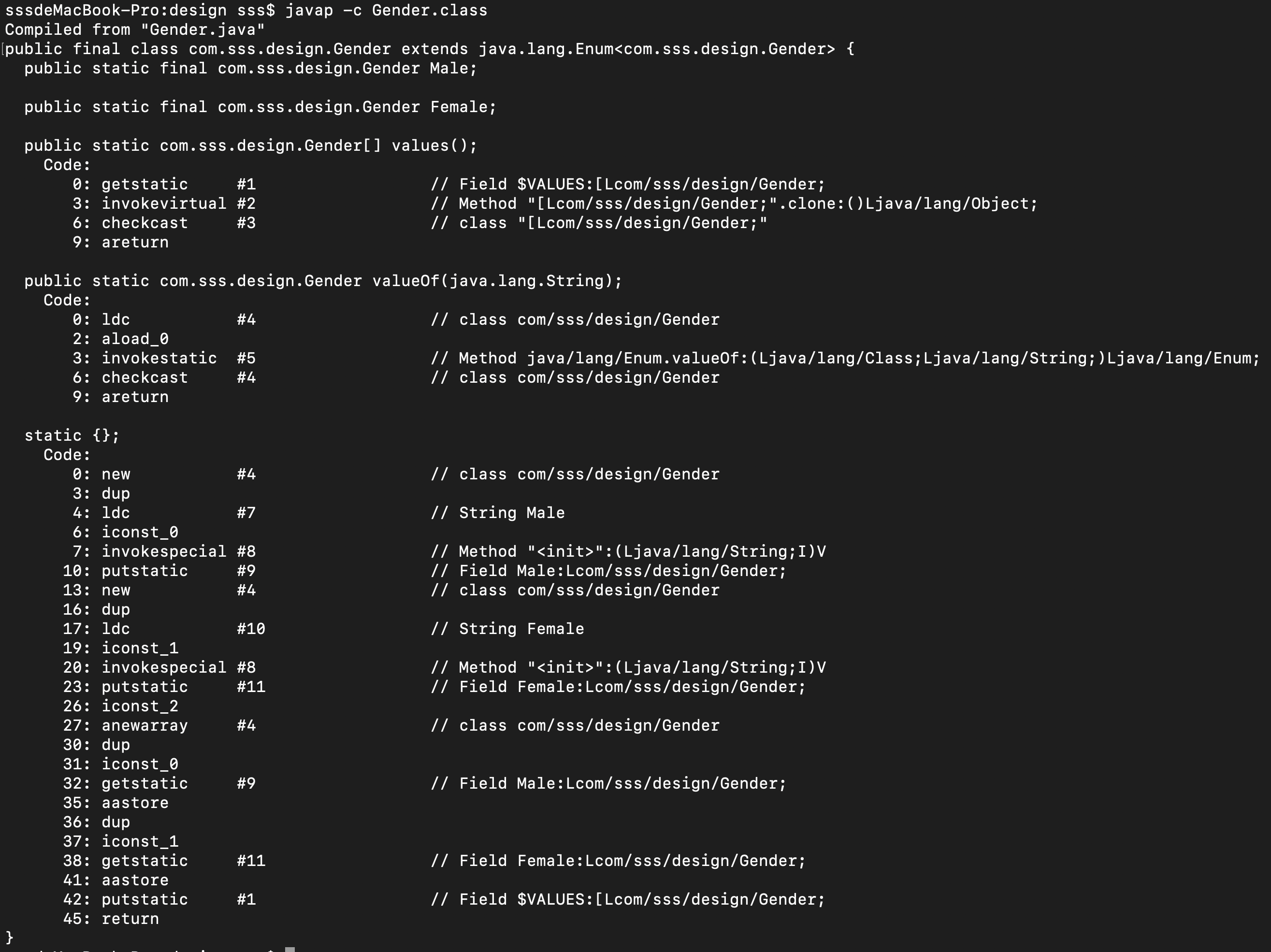
+
+可得到
+- Gender 是 final 的
+- Gender 继承自 java.lang.Enum 类
+- 声明了字段对应的两个 static final Gender 的实例
+- 实现了 values() 和 valueOf(String) 静态方法
+- static{} 对所有成员进行初始化
+
+结合字节码,还原 Gender 的普通类形式
+```java
+public final class Gender extends java.lang.Enum {
+
+ public static final Gender Male;
+ public static final Gender Female;
+
+ private static final Gender[] $VALUES;
+
+ static {
+ Male = new Gender("Male", 0);
+ Female = new Gender("Female", 1);
+
+ $VALUES = new Gender[] {Male, Female};
+ }
+
+
+
+ public static Gender[] values() {
+ return $VALUE.clone();
+ }
+
+ public static Gender valueOf(String name) {
+ return Enum.valueOf(Gender.class, name);
+ }
+}
+```
+创建的枚举类型默认是java.lang.enum<枚举类型名>(抽象类)的子类
+
+每个枚举项的类型都为`public static final`。
+
+上面的那个类是无法编译的,因为编译器限制了我们显式的继承自 java.Lang.Enum 类, 报错 "The type Gender may not subclass Enum explicitly", 虽然 java.Lang.Enum 声明的是
+
+
+
+这样看来枚举类其实用了多例模式,枚举类的实例是有范围限制的
+它同样像我们的传统常量类,只是它的元素是有限的枚举类本身的实例
+它继承自 java.lang.Enum, 所以可以直接调用 java.lang.Enum 的方法,如 name(), original() 等。
+name 就是常量名称
+
+original 与 C 的枚举一样的编号
+
+因为Java的单继承机制,emum不能再用extends继承其他的类。
+
+可以在枚举类中自定义构造方法,但必须是 private 或 package protected, 因为枚举本质上是不允许在外面用 new Gender() 方式来构造实例的(Cannot instantiate the type Gender)
+
+结合枚举实现接口以及自定义方法,可以写出下面那样的代码
+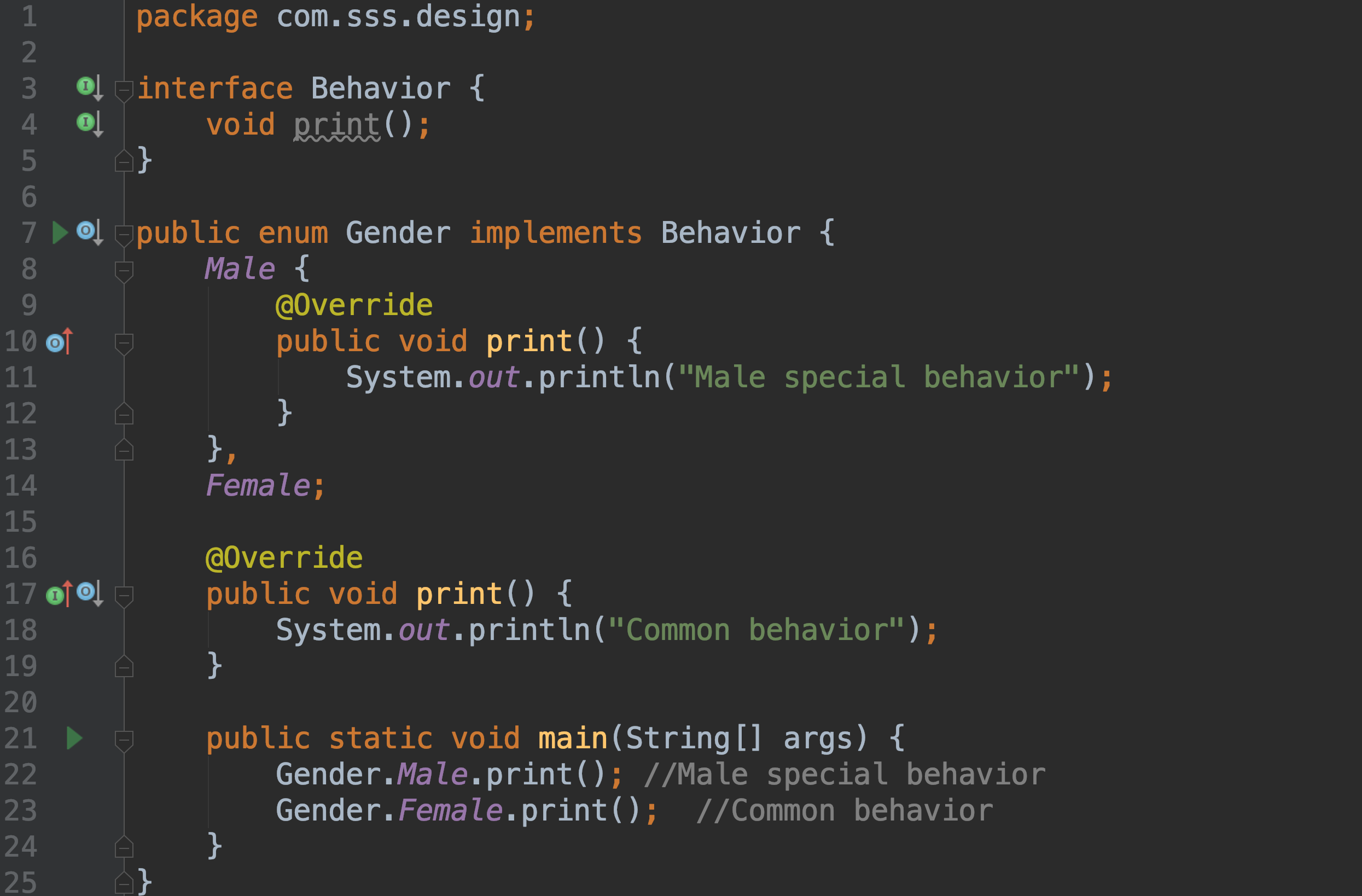
+方法可以定义成所有实例公有,也可以让个别元素独有
+
+需要特别注明一下,上面在 Male {} 声明一个 print() 方法后实际产生一个 Gender 的匿名子类,编译后的 Gender$1,反编译它
+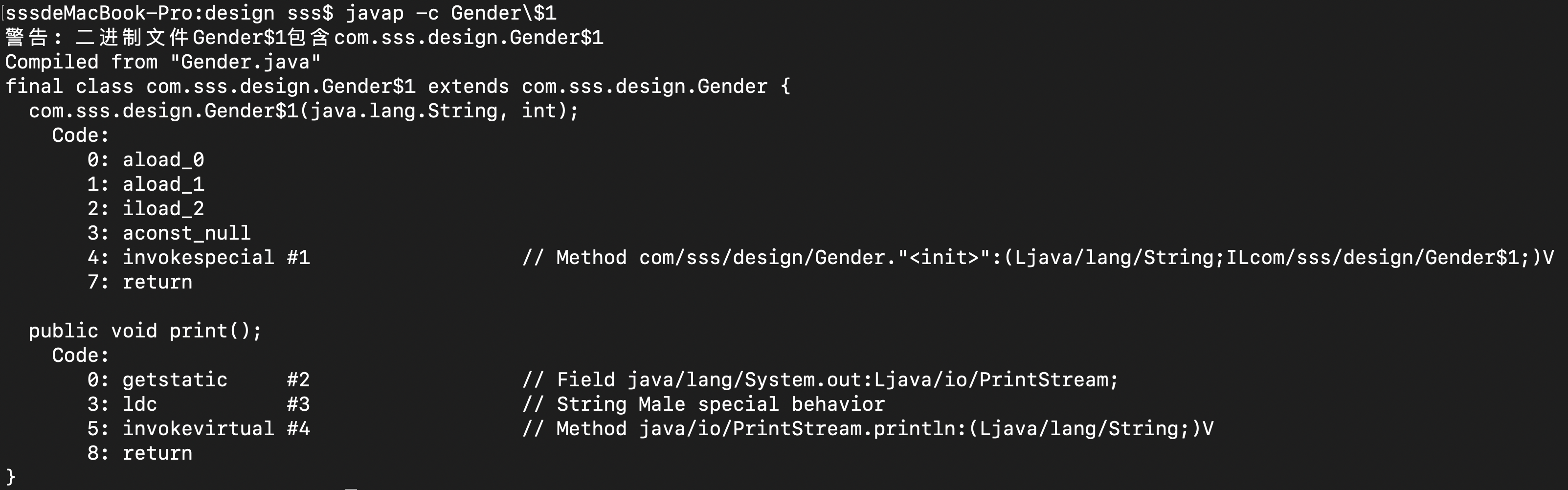
+所以在 emum Gender 那个枚举中的成员 Male 相当于是
+```
+public static final Male = new Gender$1("Male", 0); //而不是 new Gender("Male", 0)
+```
+上面` 4: Invokespecial #1` 要调用到下面的` Gender(java.lang.String, int, Gender$1) `方法
+
+若要研究完整的 Male 元素的初始化过程就得 javap -c Gender 看 Gender.java 产生的所有字节码,在此列出片断
+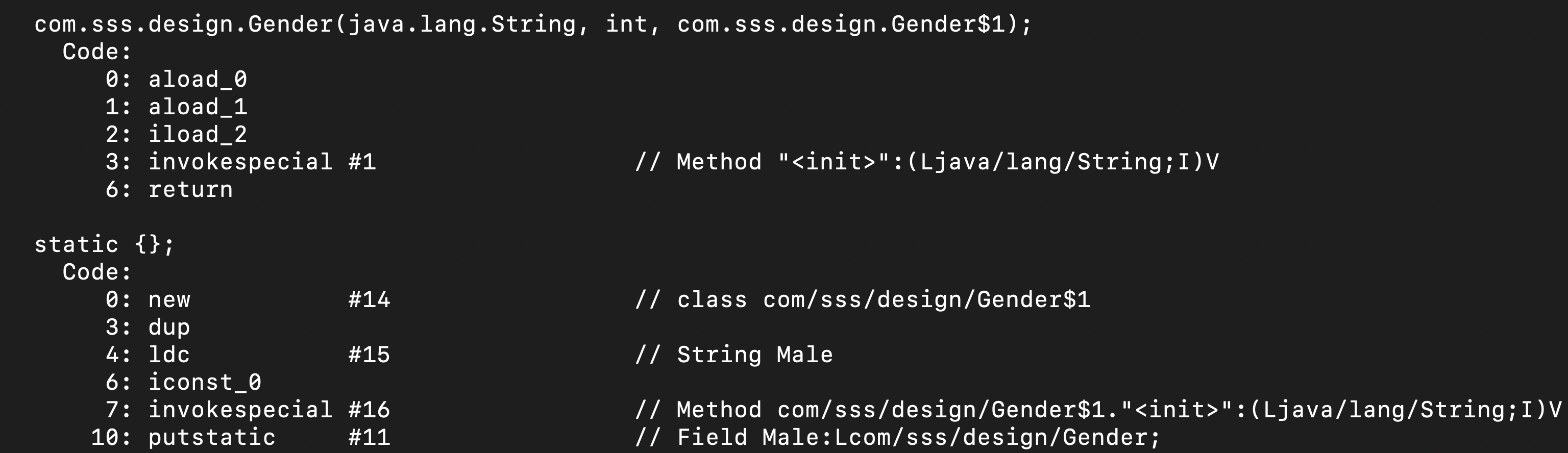
+在 static{} 中大致看下 Male 的初始过程:加载 Gender$1, 并调用它的 Gender$1(java.lang.String, int) 构造函数生成一个 Gender$1 实例赋给 Male 属性
+
+
+
+既然enum是一个类,那么它就可以像一般的类一样拥有自己的属性与方法。但Java要求必须先定义enum实例。
+
+否则会编译错误。
+```java
+public enum Color {
+ RED("红色", 1), GREEN("绿色", 2), BLANK("白色", 3), YELLO("黄色", 4);
+ // 成员变量
+ private String name;
+ private int index;
+
+ // 构造方法
+ private Color(String name, int index) {
+ this.name = name;
+ this.index = index;
+ }
+
+ // 普通方法
+ public static String getName(int index) {
+ for (Color c : Color.values()) {
+ if (c.getIndex() == index) {
+ return c.name;
+ }
+ }
+ return null;
+ }
+
+ // get set 方法
+ public String getName() {
+ return name;
+ }
+
+ public void setName(String name) {
+ this.name = name;
+ }
+
+ public int getIndex() {
+ return index;
+ }
+
+ public void setIndex(int index) {
+ this.index = index;
+ }
+ }
+```
+枚举实例的创建过程:枚举类型符合通用模式 Class Enum>,而 E 表示枚举类型的名称。枚举类型的每一个值都将映射到 protected Enum(String name, int ordinal) 构造函数中,在这里,每个值的名称都被转换成一个字符串,并且序数设置表示了此设置被创建的顺序。
+```java
+public enum Color{
+ RED, GREEN, BLUE, BLACK, PINK, WHITE;
+}
+```
+相当于调用了六次Enum构造方法
+
+Enum("RED", 0);
+
+Enum("GREEN", 1);
+
+Enum("BLUE", 2);
+
+Enum("BLACK", 3);
+
+Enum("PINK",4);
+
+Enum("WHITE", 5);
+
+**枚举类型的常用方法:**
+
+int compareTo(E o) 比较此枚举与指定对象的顺序。
+
+Class getDeclaringClass() 返回与此枚举常量的枚举类型相对应的 Class 对象。
+
+String name() 返回此枚举常量的名称,在其枚举声明中对其进行声明。
+
+int ordinal() 返回枚举常量的序数(它在枚举声明中的位置,其中初始常量序数为零
+
+String toString() 返回枚举常量的名称,它包含在声明中。
+
+static > T valueOf(Class enumType, String name) 返回带指定名称的指定枚举类型的枚举常量。
+
+# 2 常用用法
+## 2.1 常量
+
+在JDK1.5 之前,我们定义常量都是: public static fianl.... 。现在好了,有了枚举,可以把相关的常量分组到一个枚举类型里,而且枚举提供了比常量更多的方法。
+
+## 2.2 switch
+JDK1.6之前的switch语句只支持int、char、enum类型,使用枚举,能让我们的代码可读性更强。
+```java
+public class TestEnum {
+
+ public void changeColor() {
+
+ Color color = Color.RED;
+
+ System.out.println("原色:" + color);
+
+ switch(color){
+ case RED:
+ color = Color.GREEN;
+ System.out.println("变色:" + color);
+ break;
+ case GREEN:
+ color = Color.BLUE;
+ System.out.println("变色:" + color);
+ break;
+ case BLUE:
+ color = Color.BLACK;
+ System.out.println("变色:" + color);
+ break;
+ case BLACK:
+ color = Color.PINK;
+ System.out.println("变色:" + color);
+ break;
+ case PINK:
+ color = Color.WHITE;
+ System.out.println("变色:" + color);
+ break;
+ case WHITE:
+ color = Color.RED;
+ System.out.println("变色:" + color);
+ break;
+ }
+ }
+
+ public static void main(String[] args){
+ TestEnum testEnum = new TestEnum();
+ testEnum.changeColor();
+ }
+}
+```
+## 2.3 实现接口
+```java
+public interface Behaviour {
+ void print();
+
+ String getInfo();
+ }
+
+ public enum Color implements Behaviour {
+ RED("红色", 1), GREEN("绿色", 2), BLANK("白色", 3), YELLO("黄色", 4);
+ // 成员变量
+ private String name;
+ private int index;
+
+ // 构造方法
+ private Color(String name, int index) {
+ this.name = name;
+ this.index = index;
+ }
+
+ // 接口方法
+
+ @Override
+ public String getInfo() {
+ return this.name;
+ }
+
+ // 接口方法
+ @Override
+ public void print() {
+ System.out.println(this.index + ":" + this.name);
+ }
+ }
+```
+## 枚举集合
+- EnumSet保证集合中的元素不重复
+- EnumMap中的 key是enum类型,而value则可以是任意类型
+
+
+**三、综合实例**
+### **最简单的使用**
+最简单的枚举类
+```
+public enum Weekday {
+ SUN,MON,TUS,WED,THU,FRI,SAT
+}
+```
+如何使用它呢?
+先来看看它有哪些方法:
+
+这是Weekday可以调用的方法和参数。发现它有两个方法:values()和valueOf()。还有我们刚刚定义的七个变量
+
+这些事枚举变量的方法。我们接下来会演示几个比较重要的
+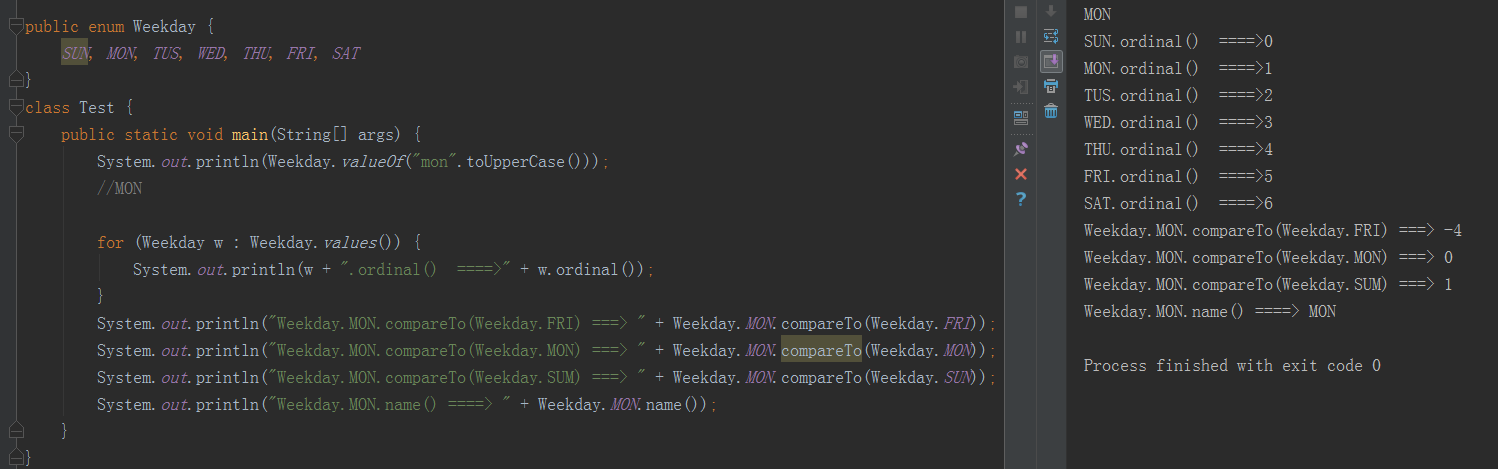
+
+
+这段代码,我们演示了几个常用的方法和功能:
+
+1. Weekday.valueOf() 方法:
+
+ > 它的作用是传来一个字符串,然后将它转变为对应的枚举变量。前提是你传的字符串和定义枚举变量的字符串一样,区分大小写。如果你传了一个不存在的字符串,那么会抛出异常。
+
+2. Weekday.values()方法。
+
+ > 这个方法会返回包括所有枚举变量的数组。在该例中,返回的就是包含了七个星期的Weekday[]。可以方便的用来做循环。
+
+3. 枚举变量的toString()方法。
+
+ > 该方法直接返回枚举定义枚举变量的字符串,比如MON就返回【”MON”】。
+
+4. 枚举变量的.ordinal()方法。
+
+ > 默认情况下,枚举类会给所有的枚举变量一个默认的次序,该次序从0开始,类似于数组的下标。而.ordinal()方法就是获取这个次序(或者说下标)
+
+5. 枚举变量的compareTo()方法。
+
+ > 该方法用来比较两个枚举变量的”大小”,实际上比较的是两个枚举变量的次序,返回两个次序相减后的结果,如果为负数,就证明变量1”小于”变量2 (变量1.compareTo(变量2),返回【变量1.ordinal() - 变量2.ordinal()】)
+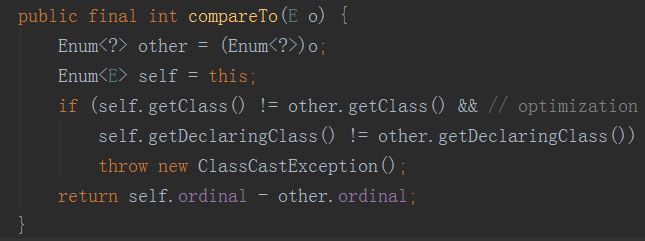
+ > 这是compareTo的源码,会先判断是不是同一个枚举类的变量,然后再返回差值。
+
+6. 枚举类的name()方法。
+
+ > 它和toString()方法的返回值一样,事实上,这两个方法本来就是一样的:
+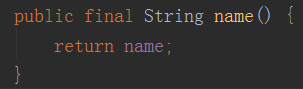
+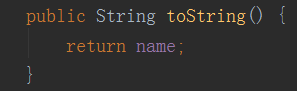
+ > 这两个方法的默认实现是一样的,唯一的区别是,你可以重写toString方法。name变量就是枚举变量的字符串形式。
+
+还有一些其他的方法我就暂时不介绍了,感兴趣的话可以自己去看看文档或者源码,都挺简单的。
+
+> **要点:**
+>
+> * 使用的是enum关键字而不是class。
+> * 多个枚举变量直接用逗号隔开。
+> * 枚举变量最好大写,多个单词之间使用”_”隔开(比如:INT_SUM)。
+> * 定义完所有的变量后,以分号结束,如果只有枚举变量,而没有自定义变量,分号可以省略(例如上面的代码就忽略了分号)。
+> * 在其他类中使用enum变量的时候,只需要【类名.变量名】就可以了,和使用静态变量一样。
+
+但是这种简单的使用显然不能体现出枚举的强大,我们来学习一下复杂的使用:
+### **枚举的高级使用方法**
+
+就像我们前面的案例一样,你需要让每一个星期几对应到一个整数,比如星期天对应0。上面讲到了,枚举类在定义的时候会自动为每个变量添加一个顺序,从0开始。
+
+假如你希望0代表星期天,1代表周一。。。并且你在定义枚举类的时候,顺序也是这个顺序,那你可以不用定义新的变量,就像这样:
+
+```
+public enum Weekday {
+ SUN,MON,TUS,WED,THU,FRI,SAT
+}
+```
+
+这个时候,星期天对应的ordinal值就是0,周一对应的就是1,满足你的要求。但是,如果你这么写,那就有问题了:
+
+```
+public enum Weekday {
+ MON,TUS,WED,THU,FRI,SAT,SUN
+}
+```
+
+我吧SUN放到了最后,但是我还是希0代表SUN,1代表MON怎么办呢?默认的ordinal是指望不上了,因为它只会傻傻的给第一个变量0,给第二个1。。。
+
+所以,我们需要自己定义变量!
+
+看代码:
+
+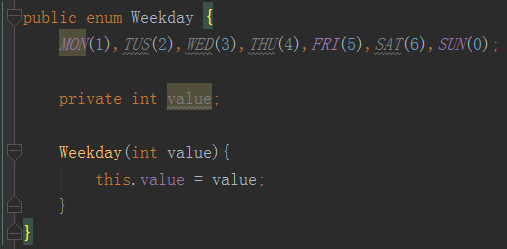
+
+我们对上面的代码做了一些改变:
+
+首先,我们在每个枚举变量的后面加上了一个括号,里面是我们希望它代表的数字。
+
+然后,我们定义了一个int变量,然后通过构造函数初始化这个变量。
+
+你应该也清楚了,括号里的数字,其实就是我们定义的那个int变量。这句叫做自定义变量。
+
+> 请注意:这里有三点需要注意:
+>
+> 1. 一定要把枚举变量的定义放在第一行,并且以分号结尾。
+>
+>
+> 2. 构造函数必须私有化。事实上,private是多余的,你完全没有必要写,因为它默认并强制是private,如果你要写,也只能写private,写public是不能通过编译的。
+>
+>
+> 3. 自定义变量与默认的ordinal属性并不冲突,ordinal还是按照它的规则给每个枚举变量按顺序赋值。
+
+好了,你很聪明,你已经掌握了上面的知识,你想,既然能自定义一个变量,能不能自定义两个呢?
+
+当然可以:
+
+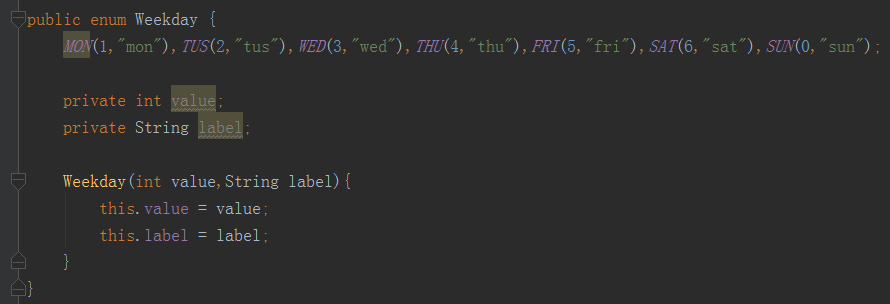
+
+你可以定义任何你想要的变量。学完了这些,大概枚举类你也应该掌握了,但是,还有没有其他用法呢?
+
+### **枚举类中的抽象类**
+
+如果我在枚举类中定义一个抽象方法会怎么样?
+
+> 你要知道,枚举类不能继承其他类,也不能被其他类继承。至于为什么,我们后面会说到。
+
+你应该知道,有抽象方法的类必然是抽象类,抽象类就需要子类继承它然后实现它的抽象方法,但是呢,枚举类不能被继承。。你是不是有点乱?
+
+我们先来看代码:
+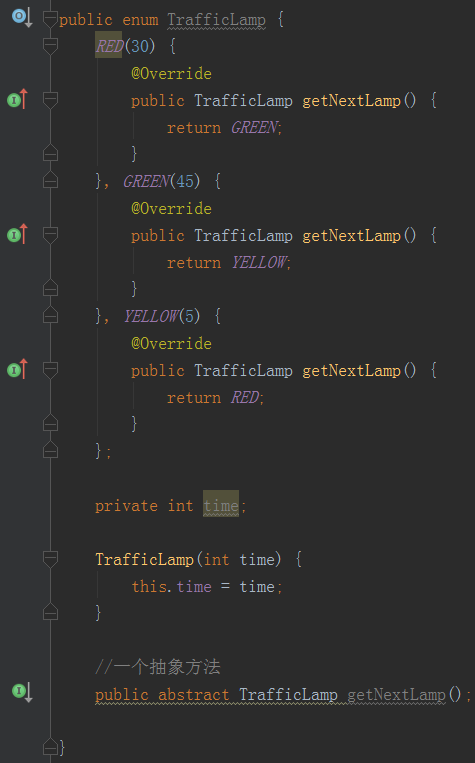
+
+你好像懂了点什么。但是你好像又不太懂。为什么一个变量的后边可以带一个代码块并且实现抽象方法呢?
+
+别着急,带着这个疑问,我们来看一下枚举类的实现原理。
+
+## **枚举类的实现原理**
+
+从最简单的看起:
+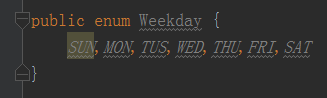
+还是这段熟悉的代码,我们编译一下它,再反编译一下看看它到底是什么样子的:
+
+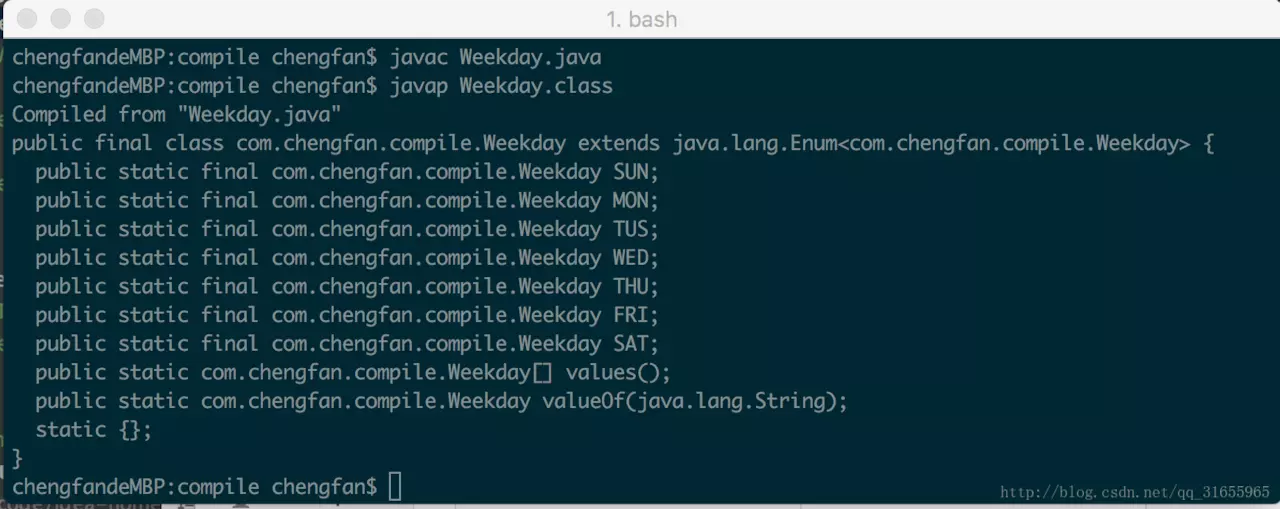
+
+
+你是不是觉得很熟悉?反编译出来的代码和我们用静态变量自己写的类出奇的相似!
+
+而且,你看到了熟悉的values()方法和valueOf()方法。
+
+仔细看,这个类继承了java.lang.Enum类!所以说,枚举类不能再继承其他类了,因为默认已经继承了Enum类。
+
+并且,这个类是final的!所以它不能被继承!
+
+回到我们刚才的那个疑问:
+
+为什么会有这么神奇的代码?现在你差不多懂了。因为RED本身就是一个TrafficLamp对象的引用。实际上,在初始化这个枚举类的时候,你可以理解为执行的是`TrafficLamp RED = new TrafficLamp(30)` ,但是因为TrafficLamp里面有抽象方法,还记得匿名内部类么?
+
+我们可以这样来创建一个TrafficLamp引用:
+
+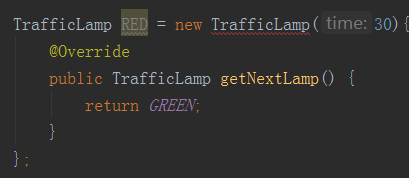
+
+
+而在枚举类中,我们只需要像上面那样写【`RED(30){}`】就可以了,因为java会自动的去帮我们完成这一系列操作
+
+## 枚举类用法
+虽然枚举类不能继承其他类,但是还是可以实现接口的
+
+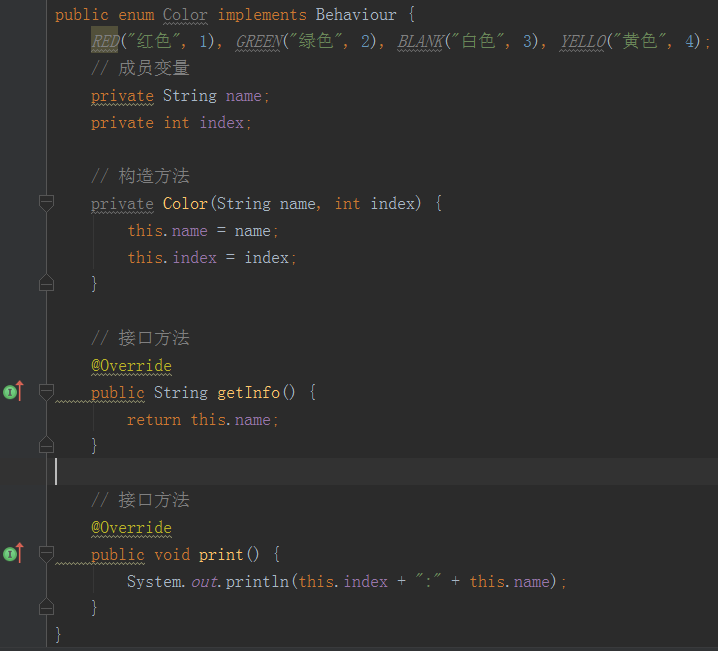
+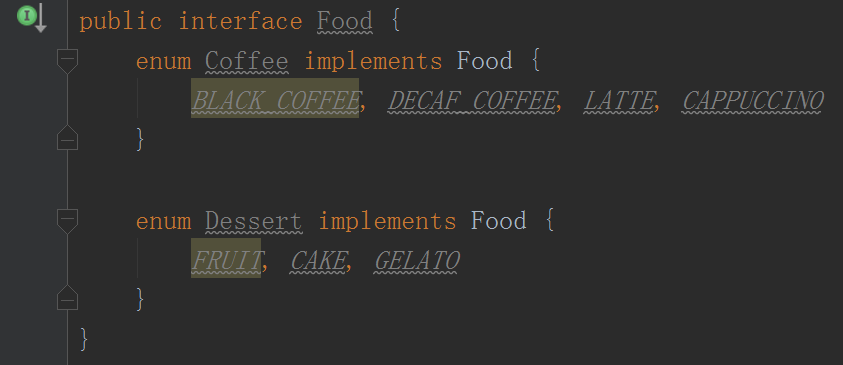
+
+
+### **使用枚举创建单例模式**
+
+***使用枚举创建的单例模式:***
+
+```
+public enum EasySingleton{
+ INSTANCE;
+}
+```
+
+代码就这么简单,你可以使用EasySingleton.INSTANCE调用它,比起你在单例中调用getInstance()方法容易多了。
+
+我们来看看正常情况下是怎样创建单例模式的:
+
+***用双检索实现单例:***
+
+下面的代码是用双检索实现单例模式的例子,在这里getInstance()方法检查了两次来判断INSTANCE是否为null,这就是为什么叫双检索的原因,记住双检索在java5之前是有问题的,但是java5在内存模型中有了volatile变量之后就没问题了。
+
+```
+public class DoubleCheckedLockingSingleton{
+ private volatile DoubleCheckedLockingSingleton INSTANCE;
+
+ private DoubleCheckedLockingSingleton(){}
+
+ public DoubleCheckedLockingSingleton getInstance(){
+ if(INSTANCE == null){
+ synchronized(DoubleCheckedLockingSingleton.class){
+ //double checking Singleton instance
+ if(INSTANCE == null){
+ INSTANCE = new DoubleCheckedLockingSingleton();
+ }
+ }
+ }
+ return INSTANCE;
+ }
+}
+```
+
+你可以访问DoubleCheckedLockingSingleTon.getInstance()来获得实例对象。
+
+***用静态工厂方法实现单例:***
+
+```
+public class Singleton{
+ private static final Singleton INSTANCE = new Singleton();
+
+ private Singleton(){}
+
+ public static Singleton getSingleton(){
+ return INSTANCE;
+ }
+}
+```
+
+你可以调用Singleton.getInstance()方法来获得实例对象。
+
+* * *
+
+上面的两种方式就是懒汉式和恶汉式单利的创建,但是无论哪一种,都不如枚举来的方便。而且传统的单例模式的另外一个问题是一旦你实现了serializable接口,他们就不再是单例的了。但是枚举类的父类【Enum类】实现了Serializable接口,也就是说,所有的枚举类都是可以实现序列化的,这也是一个优点。
+
+## **总结**
+- 可以创建一个enum类,把它看做一个普通的类。除了它不能继承其他类了。(java是单继承,它已经继承了Enum),可以添加其他方法,覆盖它本身的方法
+- switch()参数可以使用enum
+- values()方法是编译器插入到enum定义中的static方法,所以,当你将enum实例向上转型为父类Enum是,values()就不可访问了。解决办法:在Class中有一个getEnumConstants()方法,所以即便Enum接口中没有values()方法,我们仍然可以通过Class对象取得所有的enum实例
+- 无法从enum继承子类,如果需要扩展enum中的元素,在一个接口的内部,创建实现该接口的枚举,以此将元素进行分组。达到将枚举元素进行分组。
+- enum允许程序员为eunm实例编写方法。所以可以为每个enum实例赋予各自不同的行为。
\ No newline at end of file
diff --git "a/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\346\267\261\345\205\245\350\247\243\346\236\220Java\347\232\204\346\263\250\350\247\243\346\234\272\345\210\266.md" "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\346\267\261\345\205\245\350\247\243\346\236\220Java\347\232\204\346\263\250\350\247\243\346\234\272\345\210\266.md"
new file mode 100644
index 0000000000..0533174275
--- /dev/null
+++ "b/JDK/Java8\347\274\226\347\250\213\346\234\200\344\275\263\345\256\236\350\267\265/\346\267\261\345\205\245\350\247\243\346\236\220Java\347\232\204\346\263\250\350\247\243\346\234\272\345\210\266.md"
@@ -0,0 +1,1810 @@
+@[toc](目录)
+
+注解(也被称为元数据)为我们在代码中添加信息提供了一种形式化的方式,使我们可以在稍后的某个时刻更容易的使用这些数据。
+
+注解在一定程度上是把元数据和源代码文件结合在一起的趋势所激发的,而不是保存在外部文档。这同样是对像 C# 语言对于 Java 语言特性压力的一种回应。
+
+注解是 Java 5 所引入的众多语言变化之一。它们提供了 Java 无法表达的但是你需要完整表述程序所需的信息。因此,注解使得我们可以以编译器验证的格式存储程序的额外信息。注解可以生成描述符文件,甚至是新的类定义,并且有助于减轻编写“样板”代码的负担。通过使用注解,你可以将元数据保存在 Java 源代码。并拥有如下优势:
+- 简单易读的代码
+- 编译器类型检查
+- 使用 annotation API 为自己的注解构造处理工具
+- 为Java代码提供元数据
+- 暴露功能
+比如Spring的`@Service`、`@Controller`
+
+通过注解配置框架,属于声明式交互:
+- 简化框架配置
+- 和框架解耦
+
+即使 Java 定义了一些类型的元数据,但是一般来说注解类型的添加和如何使用完全取决于你。
+
+注解的语法十分简单,主要是在现有语法中添加 @ 符号。
+Java 5 引入了前三种定义在 **java.lang** 包中的注解:
+- **@Override**:表示当前的方法定义将覆盖基类的方法。如果你不小心拼写错误,或者方法签名被错误拼写的时候,编译器就会发出错误提示。
+- **@Deprecated**:如果使用该注解的元素被调用,编译器就会发出警告信息。
+- **@SuppressWarnings**:关闭不当的编译器警告信息。
+- **@SafeVarargs**:在 Java 7 中加入用于禁止对具有泛型varargs参数的方法或构造函数的调用方发出警告。
+- **@FunctionalInterface**:Java 8 中加入用于表示类型声明为函数式接口
+
+还有 5 种额外的注解类型用于创造新的注解。
+每当创建涉及重复工作的类或接口时,通常可以使用注解来自动化和简化流程。
+
+注解是真正语言层级的概念,以前构造出来就享有编译器的类型检查保护。注解在源代码级别保存所有信息而不是通过注释文字,这使得代码更加整洁和便于维护。通过使用拓展的 annotation API 或外部的字节码工具类库,你会拥有对源代码及字节码强大的检查与操作能力。
+
+# 1 基本语法
+
+
+
+在下面的例子中,使用 `@Test` 对 `testExecute()` 进行注解。该注解本身不做任何事情,但是编译器要保证其类路径上有 `@Test` 注解的定义。你将在本章看到,我们通过注解创建了一个工具用于运行这个方法:
+
+```java
+// annotations/Testable.java
+package annotations;
+import onjava.atunit.*;
+public class Testable {
+ public void execute() {
+ System.out.println("Executing..");
+ }
+ @Test
+ void testExecute() { execute(); }
+}
+```
+
+被注解标注的方法和其他的方法没有任何区别。在这个例子中,注解 `@Test` 可以和任何修饰符共同用于方法,诸如 **public**、**static** 或 **void**。从语法的角度上看,注解的使用方式和修饰符的使用方式一致。
+
+## 1.1 定义注解
+
+如下是一个注解的定义。注解的定义看起来很像接口的定义。事实上,它们和其他 Java 接口一样,也会被编译成 class 文件。
+
+```java
+// onjava/atunit/Test.java
+// The @Test tag
+package onjava.atunit;
+import java.lang.annotation.*;
+@Target(ElementType.METHOD)
+@Retention(RetentionPolicy.RUNTIME)
+public @interface Test {}
+```
+
+除了 @ 符号之外, `@Test` 的定义看起来更像一个空接口。注解的定义也需要一些元注解(meta-annoation),比如 `@Target` 和 `@Retention`。
+- `@Target` 定义你的注解可以应用在哪里(例如是方法还是字段)
+- `@Retention` 定义了注解在哪里可用
+ - 在源代码中(SOURCE)
+ - class文件(CLASS)
+ - 运行时(RUNTIME)
+
+注解通常会包含一些表示特定值的元素。当分析处理注解的时候,程序或工具可以利用这些值。注解的元素看起来就像接口的方法,但是可以为其指定默认值。
+
+不包含任何元素的注解称为标记注解(marker annotation),例如上例中的 `@Test` 就是标记注解。
+
+下面是一个简单的注解,我们可以用它来追踪项目中的用例。程序员可以使用该注解来标注满足特定用例的一个方法或者一组方法。于是,项目经理可以通过统计已经实现的用例来掌控项目的进展,而开发者在维护项目时可以轻松的找到用例用于更新,或者他们可以调试系统中业务逻辑。
+
+```java
+// annotations/UseCase.java
+import java.lang.annotation.*;
+@Target(ElementType.METHOD)
+@Retention(RetentionPolicy.RUNTIME)
+public @interface UseCase {
+ int id();
+ String description() default "no description";
+}
+```
+
+注意 **id** 和 **description** 与方法定义类似。由于编译器会对 **id** 进行类型检查,因此将跟踪数据库与用例文档和源代码相关联是可靠的方式。**description** 元素拥有一个 **default** 值,如果在注解某个方法时没有给出 **description** 的值。则该注解的处理器会使用此元素的默认值。
+
+在下面的类中,有三个方法被注解为用例:
+
+```java
+// annotations/PasswordUtils.java
+import java.util.*;
+public class PasswordUtils {
+ @UseCase(id = 47, description =
+ "Passwords must contain at least one numeric")
+ public boolean validatePassword(String passwd) {
+ return (passwd.matches("\\w*\\d\\w*"));
+ }
+ @UseCase(id = 48)
+ public String encryptPassword(String passwd) {
+ return new StringBuilder(passwd)
+ .reverse().toString();
+ }
+ @UseCase(id = 49, description =
+ "New passwords can't equal previously used ones")
+ public boolean checkForNewPassword(
+ List