|
| 1 | +### python高级爬虫实战之Headers信息校验-Cookie |
| 2 | + |
| 3 | +#### 一、什么是cookie |
| 4 | + |
| 5 | + 上期我们了解了User-Agent,这期我们来看下如何利用Cookie进行用户模拟登录从而进行网站数据的爬取。 |
| 6 | + |
| 7 | +首先让我们来了解下什么是Cookie: |
| 8 | + |
| 9 | + Cookie指某些网站为了辨别用户身份、从而储存在用户本地终端上的数据。当客户端在第一次请求网站指定的首页或登录页进行登录之后,服务器端会返回一个Cookie值给客户端。如果客户端为浏览器,将自动将返回的cookie存储下来。当再次访问改网页的其他页面时,自动将cookie值在Headers里传递过去,服务器接受值后进行验证,如合法处理请求,否则拒绝请求。 |
| 10 | + |
| 11 | +### 二、如何利用cookie |
| 12 | + |
| 13 | + 举个例子我们要去微博爬取相关数据,首先我们会遇到登录的问题,当然我们可以利用python其他的功能模块进行模拟登录,这里可能会涉及到验证码等一些反爬手段。 |
| 14 | + |
| 15 | + |
| 16 | + |
| 17 | +换个思路,我们登录好了,通过开发者工具“右击” 检查(或者按F12) 获取到对应的cookie,那我们就可以绕个登录的页面,利用cookie继续用户模拟操作从而直接进行操作了。 |
| 18 | + |
| 19 | +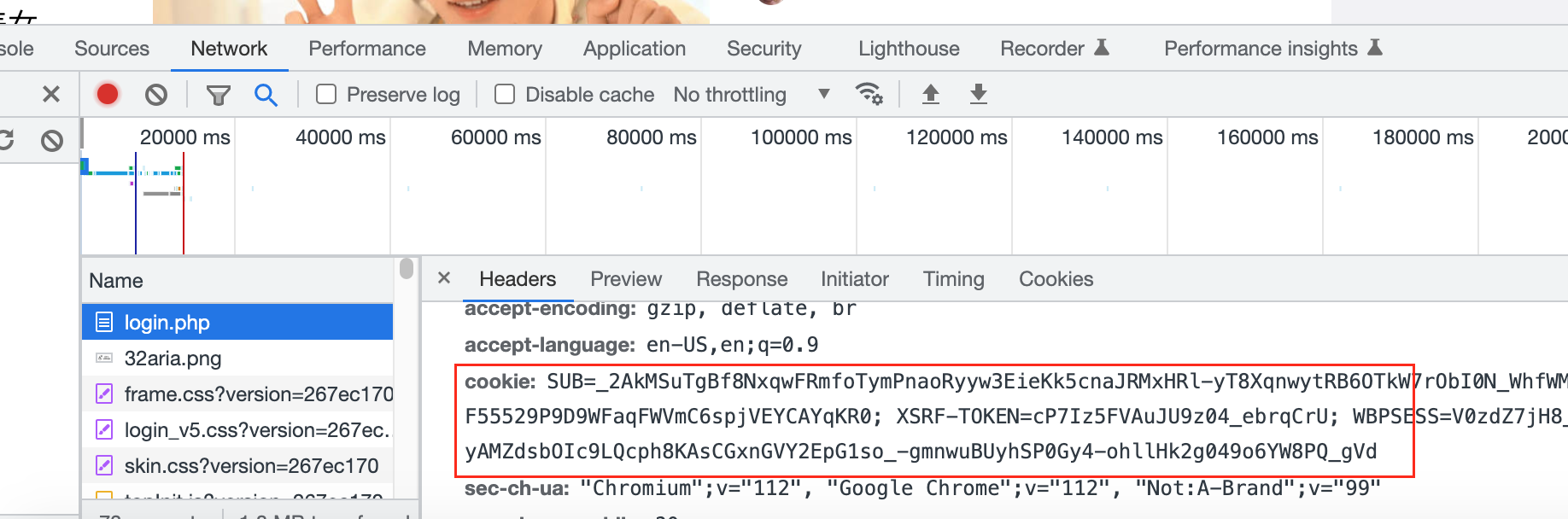 |
| 20 | + |
| 21 | +利用cookie实现模拟登录的两种方法: |
| 22 | + |
| 23 | +- [ ] 将cookie插入Headers请求头 |
| 24 | + |
| 25 | + ``` |
| 26 | + Headers={"cookie":"复制的cookie值"} |
| 27 | + ``` |
| 28 | + |
| 29 | + |
| 30 | + |
| 31 | +- [ ] 将cookie直接作为requests方法的参数 |
| 32 | + |
| 33 | +``` |
| 34 | +cookie={"cookie":"复制的cookie值"} |
| 35 | +requests.get(url,cookie=cookie) |
| 36 | +``` |
| 37 | + |
| 38 | +#### 三、利用selenium获取cookie,实现用户模拟登录 |
| 39 | + |
| 40 | +实现方法:利用selenium模拟浏览器操作,输入用户名,密码 或扫码进行登录,获取到登录的cookie保存成文件,加载文件解析cookie实现用户模拟登录。 |
| 41 | + |
| 42 | +```python |
| 43 | +from selenium import webdriver |
| 44 | +from time import sleep |
| 45 | +import json |
| 46 | +#selenium模拟浏览器获取cookie |
| 47 | +def getCookie: |
| 48 | + driver = webdriver.Chrome() |
| 49 | + driver.maximize_window() |
| 50 | + driver.get('https://weibo.co m/login.php') |
| 51 | + sleep(20) # 留时间进行扫码 |
| 52 | + Cookies = driver.get_cookies() # 获取list的cookies |
| 53 | + jsCookies = json.dumps(Cookies) # 转换成字符串保存 |
| 54 | + with open('cookies.txt', 'w') as f: |
| 55 | + f.write(jsCookies) |
| 56 | + |
| 57 | +def login: |
| 58 | + filename = 'cookies.txt' |
| 59 | + #创建MozillaCookieJar实例对象 |
| 60 | + cookie = cookiejar.MozillaCookieJar() |
| 61 | + #从文件中读取cookie内容到变量 |
| 62 | + cookie.load(filename, ignore_discard=True, ignore_expires=True) |
| 63 | + response = requests.get('https://weibo.co m/login.php',cookie=cookie) |
| 64 | +``` |
| 65 | + |
| 66 | +#### 四、拓展思考 |
| 67 | + |
| 68 | + 如果频繁使用一个账号进行登录爬取网站数据有可能导致服务器检查到异常,对当前账号进行封禁,这边我们就需要考虑cookie池的引入了。 |
0 commit comments